This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
Till now, we focused only on Online Subgradient Descent and its generalization, Online Mirror Descent (OMD), with a brief ad-hoc analysis of a Follow-The-Leader (FTL) analysis in the first lecture. In this class, we will extend FTL to a powerful and generic algorithm to do online convex optimization: Follow-the-Regularized-Leader (FTRL).
FTRL is a very intuitive algorithm: At each time step it will play the minimizer of the sum of the past losses plus a time-varying regularization. We will see that the regularization is needed to make the algorithm “more stable” with linear losses and avoid the jumping back and forth that we saw in Lecture 2 for Follow-the-Leader.
1. Follow-the-Regularized-Leader

As said above, in FTRL we output the minimizer of the regularized cumulative past losses. It should be clear that FTRL is not an algorithm, but rather a family of algorithms, in the same way as OMD is a family of algorithms.
Before analyzing the algorithm, let’s get some intuition on it. In OMD, we saw that the “state” of the algorithm is stored in the current iterate 
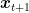


This difference in behavior might make the reader think that FTRL is more computationally and memory expensive. And indeed it is! But, we will also see that there is a way to consider approximate losses that makes the algorithm as expensive as OMD, yet retaining strictly more information than OMD.
For FTRL, we prove a surprising result: an equality for the regret! The proof is in the Appendix.
Lemma 1 Denote by
. Assume that
is not empty and set
. Then, for any
, we have
![\displaystyle \sum_{t=1}^T ( \ell_t({\boldsymbol x}_t) - \ell_t({\boldsymbol u}) ) = \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x}} \ \psi_{1}({\boldsymbol x}) + \sum_{t=1}^T [F_t({\boldsymbol x}_t) - F_{t+1}({\boldsymbol x}_{t+1}) + \ell_t({\boldsymbol x}_t)] + F_{T+1}({\boldsymbol x}_{T+1}) - F_{T+1}({\boldsymbol u})~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%28+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+-+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29+%29+%3D+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5BF_t%28%7B%5Cboldsymbol+x%7D_t%29+-+F_%7Bt%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29+%2B+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29%5D+%2B+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7BT%2B1%7D%29+-+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Given that the terms 
![\displaystyle - \sum_{t=1}^T \ell_t({\boldsymbol u}) = \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in V} \ \psi_{1}({\boldsymbol x}) + \sum_{t=1}^T [F_t({\boldsymbol x}_t) - F_{t+1}({\boldsymbol x}_{t+1})] + F_{T+1}({\boldsymbol x}_{T+1}) - F_{T+1}({\boldsymbol u})~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29+%3D+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5BF_t%28%7B%5Cboldsymbol+x%7D_t%29+-+F_%7Bt%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29%5D+%2B+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7BT%2B1%7D%29+-+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Remembering that 

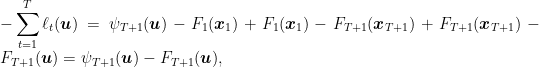
that is true by the definition of 

Remark 1 Note that we basically didn’t assume anything on
nor on
, the above equality holds even for non-convex losses and regularizers. Yet, solving the minimization problem at each step might be computationally infeasible.
Remark 2 Note that the left hand side of the equality in the theorem does not depend on
, so if needed we can set it to
.
Remark 3 Note that the algorithm is invariant to any positive constant added to the regularizers, hence we can always state the regret guarantee with
instead of
However, while surprising, the above equality is not yet a regret bound, because it is somehow “implicit” because the losses are appearing on both sides of the equality.
Let’s take a closer look at the equality. If 


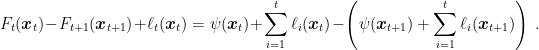
Hence, we are measuring the distance between the minimizer of the regularized losses (with two different regularizers) in two consecutive predictions of the algorithms. Roughly speaking, this term will be small if 
To quantify this intuition, we need a property of strongly convex functions.
2. Convex Analysis Bits: Properties of Strongly Convex Functions
We will use the following lemma for strongly convex functions.
Lemma 2 Let
![{f:{\mathbb R}^d \rightarrow (-\infty, +\infty]}](https://s0.wp.com/latex.php?latex=%7Bf%3A%7B%5Cmathbb+R%7D%5Ed+%5Crightarrow+%28-%5Cinfty%2C+%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
-strongly convex with respect to a norm
. Then, for all
,
, and
, we have

Proof: Define 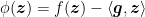





where the last step comes from the conjugate function of the squared norm (See Example 3 in the lecture on OLO lower bounds).
Corollary 3 Let
. Then, for all
, and
, we have

In words, the above lemma says that an upper bound to the suboptimality gap is proportional to the squared norm of the subgradient.
3. An Explicit Regret Bound using Strongly Convex Regularizers
We now state a Lemmas quantifying the intuition on the “stability” of the predictions.
Lemma 4 With the notation and assumptions of Lemma 1, assume that
-strongly convex w.r.t.
is non-empty. Then, we have
for all
.

Proof: We have

where in the second inequality we used Lemma 2, the fact that 





Let’s see some immediate applications of FTRL
Corollary 5 Let
a
, where
. Then, FTRL guarantees
for all
-Lipschitz, setting
we get

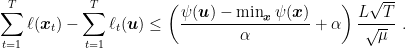
Proof: The corollary is immediate from Lemma 1, Lemma 4, and the observation that from the assumptions we have 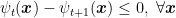
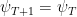
This might look like the same regret guarantee of OMD, however here there is a very important difference: The last term contains a time-varying element (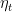


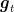
The another important difference is that here the update rule seems way more expensive than in OMD, because we need to solve an optimization problem at each step. However, it turns out we can use FTRL on linearized losses and obtain the same bound with the same computational complexity of OMD.
4. FTRL with Linearized Losses
If we consider that case in which the losses are linear, we have that the prediction of FTRL is
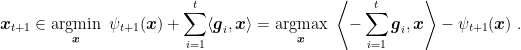
Now, if we assume 




In turn, this update can be written in the following way

This corresponds to Figure 1.
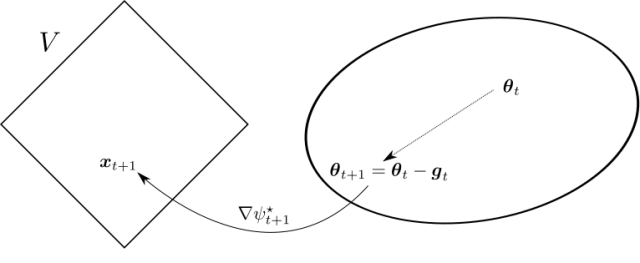
Compare it to the mirror update of OMD, rewritten in a similar way:

They are very similar, but with important differences:
- In OMD, the state is kept in
- In FTRL with linear losses, the state is kept directly in the dual space, updated and then transformed in the primal variable. The primal variable is only used to predict, but not directly in the update.
- In OMD, the samples are weighted by the learning rates that is typically decreasing
- In FTRL with linear losses, all the subgradients have the same weight, but the regularizer is typically increasing over time.
Also, we will not loose anything in the bound! Indeed, we can run FTRL on the linearized losses 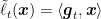

In fact, using the definition of the subgradients and the assumptions of Corollary 5, we have
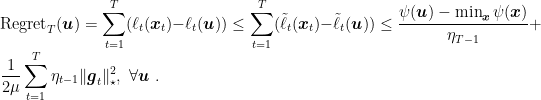
The only difference with respect to Corollary 5 is that here the
In the next example, we can see the different behavior of FTRL and OMD.
Example 1 Consider
. With Online Subgradient Descent (OSD) with learning rate
and
, the update is
On the other hand in FTRL with linearized losses, we can use
and it is easy to verify that the update in (1) becomes
While the regret guarantee would be the same for these two updates, from an intuitive point of view OMD seems to be loosing a lot of potential information due to the projection and the fact that we only memorize the projected iterate.

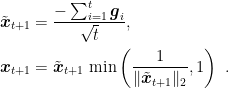
Next time, we will see how to obtain logarithmic regret bounds for strongly convex losses for FTRL and more applications.
5. History Bits
Follow the Regularized Leader was introduced in (Abernethy, J. D. and Hazan, E. and Rakhlin, A., 2008) where at each step the prediction is computed as the minimizer of a regularization term plus the sum of losses on all past rounds. However, the key ideas of FTRL, and in particular its analysis through the dual, were planted by Shai Shalev-Shwartz and Yoram Singer way before (Shalev-Shwartz, S. and Singer, Y., 2006)(Shalev-Shwartz, S. and Singer, Y., 2007). Later, the PhD thesis of Shai Shalev-Shwartz (S. Shalev-Shwartz, 2007) contained the most precise dual analysis of FTRL, but he called it “online mirror descent” because the name FTRL was only invented later! Even later, I contributed to the confusion naming a general analysis of FTRL with time-varying regularizer and linear losses “generalized online mirror descent” (F. Orabona and K. Crammer and N. Cesa-Bianchi, 2015). So, now I am trying to set the record straight 🙂
Later to all this, the optimization community starts using FTRL with linear losses as well, calling it Dual Averaging (Nesterov, Y., 2009). Note that this paper by Nesterov is actually from 2005 (Nesterov, Y., 2005), and in the paper he claims that these ideas are from 2001-2002, but he decided not to publish them for a while because he was convinced that “the importance of black-box approach in Convex Optimization will be irreversibly vanishing, and, finally, this approach will be completely replaced by other ones based on a clever use of problem’s structure (interior-point methods, smoothing, etc.).” Hence, Nesterov is for sure the the first inventor of offline FTRL with linear losses. It is interesting to note that Nesterov introduced the Dual Averaging algorithm to fix the fact that in OMD gradients enter the algorithm with decreasing weights, contradicting the common sense understanding of how optimization should work. The same ideas were then translated to online learning and stochastic optimization in (L. Xiao, 2010), essentially rediscovering the framework of Shalev-Shwartz and rebranding it Regularized Dual Averaging (RDA). Finally, (McMahan, H B., 2017) gives the elegant equality result that I presented here (with minor improvements) that holds for general loss functions and regularizers. Note that Dual Averaging stems from the dual interpretation of FTRL for linear losses, but Lemma 1 underlines the fact that FTRL is actually more general.
Another source of confusion stems from the fact that some people differentiate among a “lazy” and “greedy” version of OMD. In reality, as proved in (McMahan, H B., 2017), the lazy algorithm is just FTRL with linearized losses and the greedy one is just OMD. The notation “lazy online mirror descent” was introduced in (Zinkevich, M., 2004), where he basically introduced for the first time FTRL with linearized losses in the special case of 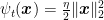
6. Exercises
Exercise 1 Prove that the update of FTRL with linearized loss in Example 1 is correct.
Exercise 2 Find a way to have
bounds for smooth losses with linearized FTRL: Do you need an additional assumption compared to what we did for OSD?

Corollary 5’s proof should have that \psi_t(x) – \psi_{t+1}(x) \leq 0 (currently the sign of the inequality is incorrect)
LikeLike
Hi Anil, thanks for the bug report! Fixed now.
LikeLike
Hi Francesco, I am a bit confused about corollary 5. Here’s my reasoning: starting from the regret equality lemma, we can say that F_{T+1}(x_{T+1}) \leq F_{T+1}(u) because x_{T+1} is the minimiser of F_{T+1}(x), thus we can get rid of the last 2 terms since their sum is less or equal than 0. Then using lemma 4 and the choice of regularisers that you gave, the sum over t of the terms in the rhs of the regret equality lemma reduces to $ \frac{1}{2 \mu} \sum_{t=1}^T \n_{t-1} \| g_t \|_*^2 $ as written. Until here, everything should be fine. Now regarding the first two terms, using the definition of $\psi$ you gave we should get
$$ \psi_{T+1}(u) – \min_x \psi_1(x) = \frac{1}{\eta_T}( \Psi(u) – \min_z \Psi(z) ) – \min_x ( \frac{1}{\eta_0} ( \Psi(x) – \min_z \Psi(z) ) ) $$
which, if I’m not wrong reduces to
$$ \frac{1}{\eta_T} \Psi(u) – \frac{1}{\eta_0} \min_x \Psi(x) $$
assuming decreasing learning rates, i.e. \eta_t \leq \eta_{t-1}. But, if this is true we get the final bound as
$$ R_T(u) \leq \frac{1}{\eta_T} \Psi(u) – \frac{1}{\eta_0} \min_x \Psi(x) + \frac{1}{2\mu} \sum_{t=1}^T \| g_t \|_*^2 $$
where the first two terms are bit different from what you have written, in particular the one with \eta_0. Do we make any assumption on \eta_0 or maybe I did some mistakes in the calculations?
Also, some I think there are some typos when you mention the linearised losses part. In particular, when you say: “Now, if we assume {\psi} to be proper, convex, and closed, using the theorem 2” – I think it should be theorem 4 – “in the lecture on OLO lower bounds, we have that {x_t}” – I think it should be x_{t+1}.
Thank you,
Nicolò
LikeLike
Hi Nicolò,
thanks for reporting the typos, they are fixed now.
Regarding the main issue, there is a remark that I forgot to write, probably it is in the next lecture: constant biases do not play any role in the update rule. Hence, I can always consider psi_t(x) substituted with psi(x) – min_y psi(y). So, the term psi_1(x_1)-min_y psi_1(y)=0 and you also get \frac{1}{\eta_T} (\psi(u) – min_x \psi(x)).
EDIT: I now added the remark.
LikeLike
All right, thanks!
LikeLiked by 1 person
EDIT: Greatly simplified the proof of the equality Lemma for FTRL.
LikeLike
Thanks to Christian Kroer for pointing out the exact dates in Nesterov’s Dual Averaging.
LikeLike
Hello Francesco, I’ve been following along your modern introduction to online convex optimization. It is a great resource. I just have a comment about example 1. Shouldn’t it be max instead of min? Otherwise, we would run into situations where x_{t+1} is not in V, i.e., || x_{t+1} || > 1.
LikeLike
I think it is correct as it is. For example, if || \tilde{x}_{t+1} ||=10, then 1/|| \tilde{x}_{t+1} || is less than 1, and we correctly divide the vector by its norm. The min keeps vectors with norm less than 1 to be normalized to 1.
LikeLike
Yeah, I see it now, my bad. Thank you so much for the quick response.
LikeLiked by 1 person
Hi Francesco, I have a small question about Corollary 5.
For the summation term in Lemma 1, I apply Lemma 4 and get $\sum_{t=1}^{T}F_t(x_t) – F_{t+1}(x_{t+1}) + l_t(x_t) \le \sum_{t=1}^{T} \frac{||g_t||_*^2}{2\mu} $. I wonder why $\eta_{t-1}$ appears in the final result.
Thanks a lot.
LikeLike
Sorry to interrupt. I have found the reason. $\psi$ is a $\mu$-strongly convex function and $\psi_t$ is a $\frac{\mu}{\eta_{t-1}}$-strongly convex function.
LikeLike
Correct!
LikeLike