This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
Last time, we saw that we can use Follow-The-Regularized-Leader (FTRL) on linearized losses:

Today, we will show a number of applications of FTRL with linearized losses, some easy ones and some more advanced ones.
As a remainder, the regret upper bound for FTRL for linearized losses that we proved last time for the case that the 

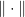


We also said that we are free to choose 

Remark 1 As we said last time, the algorithm is invariant to any positive constant added to the regularizer, hence we can always state the regret guarantee with
instead of
. However, for clarity in the following we will instead explicitly choose the regularizer such that their minimum is 0.
1. FTRL with Linearized Losses Can Be Equivalent to OMD
First, we see that even if FTRL and OMD seem very different, in certain cases they are equivalent. For example, consider that case that 
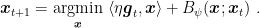
Assume that 

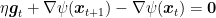
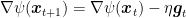


On the other hand, consider FTRL with linearized losses with regularizers 

Assuming that 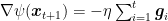
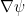
This equivalence immediately gives us some intuition on the role of 
Example 1 Consider
and
, then it satisfies the conditions above to have the predictions of OMD equal to the ones of FTRL.
2. Exponentiated Gradient with FTRL: No Need to know 
Let’s see an example of an instantiation of FTRL with linearized losses to have the FTRL version of Exponentiated Gradient (EG).
Let 
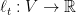

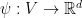



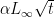
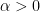
Given that the regularizers are strongly convex, we know that
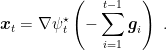
We already saw that 


Note that this is exactly the same update of EG based on OMD, but here we are effectively using time-varying learning rates.
We also get that the regret guarantee is
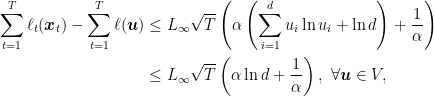
where we used the fact that using 



3. Composite Losses
Let’s now see a variant of the linearization of the losses: partial linearization of composite losses.
Suppose that the losses we receive are composed by two terms: one convex function changing over time and another part is fixed and known. These losses are called composite. For example, we might have 
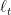
There is a better way to deal with these kind of losses: Move the constant part of the loss inside the regularization term. In this way, that part will not be linearized but used exactly in the argmin of the update. Assuming that the argmin is still easily computable, you can always expect better performance from this approach. In particular, in the case of adding an L1 norm to the losses, you will be predicting in each step with the solution of an L1 regularized optimization problem.
Practically speaking, in the example above, we will define 





where 

Example 2 Let’s also take a look at the update rule in that case that
We can solve this problem observing that the minimization decomposes over each coordinate of
. Denote by
. Hence, we know from first-order optimality condition that
is the solution for the coordinate
iff there exists
such that
Consider the 3 different cases:
, then
and
.
, then
and
.
, then
and
.
So, overall we have
Observe as this update will produce sparse solutions, while just taking the subgradient of the L1 norm would have never produced sparse predictions.
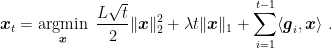


Remark 2 (Proximal operators) In the example above, we calculated something like
This operation is known in the optimization literature as Proximal Operator of the L1 norm. In general, a proximal operator of a convex, proper, and closed function
is defined as
Proximal operators are used in optimization in the same way as we used it: They allow to minimize the entire function rather a linear approximation of it. Also, proximal operators generalizes the concept of Euclidean projection. Indeed,
.


4. FTRL with Strongly Convex Functions
Let’s now go back to the FTRL regret bound and let’s see if you can strengthen it in the case that the regularizer is proximal, that is it satisfies that 
Lemma 1 Denote by
. Assume that
is not empty and set
. Also, assume that
is
. Also, assume that
is non-empty. Then, we have

Proof: We have

where in the second inequality we used Corollary 1 from last lecture, the fact that 







Remark 3 Note that a constant regularizer is proximal because any point is the minimizer of the zero function. On the other hand, a constant regularizer makes the two Lemmas the same, unless the loss functions contribute to the total strong convexity.
We will now use the above lemma to prove a logarithmic regret bound for strongly convex losses.
Corollary 2 Let
strongly convex w.r.t.
. Set the sequence of regularizers to zero. Then, FTRL guarantees a regret of

The above regret guarantee is the same of OMD over strongly convex losses, but here we don’t need to know the strong convexity of the losses. In fact, we just need to output the minimizer over the past losses. However, as we noticed last time, this might be undesirable because now each update is an optimization problem.
Hence, we can again use the idea of replacing the losses with an easy surrogate. In the Lipschitz case, it made sense to use linear losses. However, here you can do better and use quadratic losses, because the losses are strongly convex. So, we can run FTRL on the quadratic losses 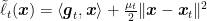
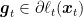

To see why this is a good idea, consider the case that the losses are strongly convex w.r.t. the L2 norm. The update now becomes:
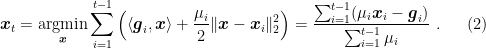
Moreover, we will get exactly the same regret bound as in Corollary 2, with the only difference that here the guarantee holds for a specific choice of the 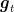
Example 3 Going back to the example in the first lecture, where
and
are strongly convex, we now see immediately that FTRL without a regularizer, that is Follow the Leader, gives logarithmic regret. Note that in this case the losses were defined only over
, so that the minimization is carried over
5. History Bits
The first analysis of FTRL with composite losses is in (L. Xiao, 2010). The analysis presented here using the negative terms 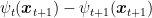
The first proof of FTRL for strongly convex losses was in (S. Shalev-Shwartz and Y. Singer, 2007) (even if they don’t call it FTRL).
There is an interesting bit about FTRL-Proximal (McMahan, H. B., 2011): FTRL-Proximal is an instantiation of FTRL that uses a particular proximal regularizer. It became very famous in internet companies when Google disclosed in a very influential paper that they were using FTRL-Proximal to train the classifier for click prediction (McMahan, H. B. and Holt, G. and Sculley, D. and Young, M. and Ebner, D. and Grady, J. and Nie, L. and Phillips, T. and Davydov, E. and Golovin, D. and Chikkerur, S. and Liu, D. and Wattenberg, M. and Hrafnkelsson, A. M. and Boulos, T. and Kubica, J., 2013). This generated even more confusion because many people started conflating the term FTRL-Proximal (a specific algorithm) with FTRL (an entire family of algorithms). Unfortunately, this confusion is still going on in these days.
6. Exercises
Exercise 1 Prove that the update in (2) is equivalent to the one of OSD with
and learning rate
.

What do you mean exactly by “proximal regularizer”? I imagined that one that includes euclidean distance from x_t but even if it were true I don’t know how to derive x_t \in argmin_x \psi_{t+1}(x) – \psi_t(x).
LikeLike
It is just a technical condition introduced by Brendan McMahan. There are not many algorithms that actually have a proximal regularizers, but constant regularizer is proximal. So, I used it because it allows me to deal with a bunch of different cases with one Lemma. In the note on Online Newton Step, for example, I used this characterization again.
LikeLike
When proving that FTRL with linerized losses is equivalent to OMD, at the very first steps there is “Assume x_{t+1} is in the int dom psi , then ngt-\/psi(x_t+1)-\/psi(x_t) = 0. Is there any resource to study why this holds?
LikeLike
I have now added a more formal explanation after Theorem 2.8 in the updated version of the pdf of these notes (https://arxiv.org/abs/1912.13213)
LikeLike
There, I am assuming V=dom psi. So, if the update of OMD is in int dom psi it means that the constraint did not play any role. In other words, you would obtain the same update removing completely the feasible set. This implies that x_{t+1} is the unconstrained minimum of the OMD update rule, hence the gradient of the OMD update rule must be 0 in x_{t+1}, that is exactly the equality I wrote.
LikeLike