This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
In this lecture we will present some lower bounds for online linear optimization (OLO). Remembering that linear losses are convex, this immediately gives us lower bounds for online convex optimization (OCO). We will consider both the constrained and the unconstrained case. The lower bounds are important because they inform us on what are the optimal algorithms and where are the gaps in our knowledge.
1. Lower bounds for Bounded OLO
We will first consider the bounded constrained case. Finding a lower bound accounts to find a strategy for the adversary that forces a certain regret onto the algorithm, no matter what the algorithm does. We will use the probabilistic method to construct our lower bound.
The basic method relies on the fact that for any random variable 

![\displaystyle \sup_{{\boldsymbol x} \in V} \ f({\boldsymbol x}) \geq \mathop{\mathbb E} [f({\boldsymbol z})]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csup_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+f%28%7B%5Cboldsymbol+x%7D%29+%5Cgeq+%5Cmathop%7B%5Cmathbb+E%7D+%5Bf%28%7B%5Cboldsymbol+z%7D%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
For us, it means that we can lower bound the effect of the worst-case sequence of functions with an expectation over any distribution over the functions. If the distribution is chosen wisely, we can expect that gap in the inequality to be small. Why do you rely on expectations rather than actually constructing an adversarial sequence? Because the use of a stochastic loss functions makes very easy to deal with arbitrary algorithms. In particular, we will choose stochastic loss functions that makes the expected loss of the algorithm 0, independently from the strategy of the algorithm.
Theorem 1 Let
be any non-empty bounded closed convex subset. Let
be the diameter of
be any (possibly randomized) algorithm for OLO on
be any non-negative integer. There exists a sequence of vectors
with
and
such that the regret of algorithm
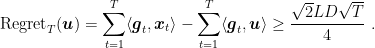
Proof: Let’s denote by 





![{\Pr[\epsilon_t=1]=\Pr[\epsilon_t=-1]=1/2}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5B%5Cepsilon_t%3D1%5D%3D%5CPr%5B%5Cepsilon_t%3D-1%5D%3D1%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \begin{aligned} \sup_{{\boldsymbol g}_1, \dots, {\boldsymbol g}_T} \text{Regret}_T &\geq \mathop{\mathbb E}\left[ \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol x}_t\rangle - \min_{{\boldsymbol u} \in V} \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol u}\rangle\right] = \mathop{\mathbb E}\left[- \min_{{\boldsymbol u} \in V} \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol u}\rangle\right] \\ &= \mathop{\mathbb E}\left[\max_{{\boldsymbol u} \in V} \sum_{t=1}^T - L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol u}\rangle\right] = \mathop{\mathbb E}\left[\max_{{\boldsymbol u} \in V} \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol u}\rangle\right] \\ &= \mathop{\mathbb E}\left[\max_{{\boldsymbol u} \in \{{\boldsymbol v}, {\boldsymbol w}\}} \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol u}\rangle\right] = \mathop{\mathbb E}\left[\frac{1}{2}\sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol v}+{\boldsymbol w}\rangle + \frac{1}{2}\left| \sum_{t=1}^T L \epsilon_t \langle {\boldsymbol z}, {\boldsymbol v}-{\boldsymbol w}\rangle\right|\right] \\ &= \frac{L}{2}\mathop{\mathbb E}\left[\left|\sum_{t=1}^T \epsilon_t \langle {\boldsymbol z}, {\boldsymbol v}-{\boldsymbol w}\rangle\right|\right] = \frac{LD}{2}\mathop{\mathbb E}\left[\left|\sum_{t=1}^T \epsilon_t \right|\right] \geq \frac{\sqrt{2} LD \sqrt{T}}{4}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csup_%7B%7B%5Cboldsymbol+g%7D_1%2C+%5Cdots%2C+%7B%5Cboldsymbol+g%7D_T%7D+%5Ctext%7BRegret%7D_T+%26%5Cgeq+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+-+%5Cmin_%7B%7B%5Cboldsymbol+u%7D+%5Cin+V%7D+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B-+%5Cmin_%7B%7B%5Cboldsymbol+u%7D+%5Cin+V%7D+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmax_%7B%7B%5Cboldsymbol+u%7D+%5Cin+V%7D+%5Csum_%7Bt%3D1%7D%5ET+-+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmax_%7B%7B%5Cboldsymbol+u%7D+%5Cin+V%7D+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmax_%7B%7B%5Cboldsymbol+u%7D+%5Cin+%5C%7B%7B%5Cboldsymbol+v%7D%2C+%7B%5Cboldsymbol+w%7D%5C%7D%7D+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+v%7D%2B%7B%5Cboldsymbol+w%7D%5Crangle+%2B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%7C+%5Csum_%7Bt%3D1%7D%5ET+L+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+v%7D-%7B%5Cboldsymbol+w%7D%5Crangle%5Cright%7C%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7BL%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%7C%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+z%7D%2C+%7B%5Cboldsymbol+v%7D-%7B%5Cboldsymbol+w%7D%5Crangle%5Cright%7C%5Cright%5D+%3D+%5Cfrac%7BLD%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%7C%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Cright%7C%5Cright%5D+%5Cgeq+%5Cfrac%7B%5Csqrt%7B2%7D+LD+%5Csqrt%7BT%7D%7D%7B4%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where we used ![{\mathop{\mathbb E}[\epsilon_t]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cepsilon_t%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002)

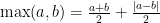

We see that the lower bound is a constant multiplicative factor from the upper bound we proved for Online Subgradient Descent (OSD) with learning rates 
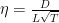
At this point there is an important consideration to do: How can this be the optimal regret when we managed to proved better regret, for example with adaptive learning rates? The subtlety is that, constraining the adversary to play 
We now move to the unconstrained case, however first we have to enrich our math toolbox with another essential tool, Fenchel conjugates.
2. Convex Analysis Bits: Fenchel Conjugate
Definition 2 A function
is closed iff
is closed for every
.
Note that in a Hausdorff space a function is closed iff it is lower semicontinuos (Bauschke, H. H. and Combettes, P. L., 2011, Lemma 1.24).
Example 1 The indicator function of a set
Definition 3 For a function
, we define the Fenchel conjugate
as

From the definition we immediately obtain the Fenchel’s inequality
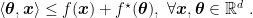
We have the following useful property for the Fenchel conjugate
Theorem 4 (Rockafellar, R. T., 1970, Corollary 23.5.1 and Theorem 23.5) Let
be convex, proper, and closed. Then
iff
.
achieves its supremum in
at
iff
.
Example 2 Let
, hence we have
. Solving the optimization, we have that
if
and
,
, and
for
.
Example 3 Consider the function
, where
is a norm in
, with dual norm
. We can show that its conjugate is
. From
for all
, which has maximum value
. Therefore for all
which shows that
. To show the other inequality, let
, scaled so that
. Then we have, for this
which shows that
.

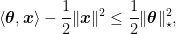

Lemma 5 Let
be a function and let
be its Fenchel conjugate. For
and
, the Fenchel conjugate of
is
.
Proof: From the definition of conjugate function, we have

Lemma 6 (Bauschke, H. H. and Combettes, P. L., 2011, Example 13.7) Let
even. Then
.
3. Unconstrained OLO
The above lower bound applies only to the constrained setting. In the unconstrained setting, we proved that OSD with 




The approach I will follow is to reduce the OLO game to the online game of betting on a coin, where the lower bounds are known. So, let’s introduce the coin-betting online game:
- Start with an initial amount of money
.
- In each round, the algorithm bets a fraction of its current wealth on the outcome of a coin.
- The outcome of the coin is revealed and the algorithm wins or lose its bet, 1 to 1.
The aim of this online game is to win as much money as possible. Also, as in all the online games we consider, we do not assume anything on how the outcomes of the coin are decided. Note that this game can also be written as OCO using the log loss.
We will denote by 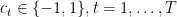
![{\beta_t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cbeta_t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



where we used the fact that 
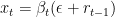
If we got all the outcomes of the coin correct, we would double our money in each round, so that 
Theorem 7 (Cesa-Bianchi, N. and Lugosi, G. , 2006, a simplified statement of Theorem 9.2) Let
. Then, for any betting strategy with initial money
, such that

Now, let’s connect the coin-betting game with OLO. Remember that proving a regret guarantee in OLO consists in showing

for some function 

Hence, for a given online algorithm we can prove regret bounds proving that there exists a function 
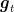
Without any other information, it can be challenging to guess what is the slowest increasing function
Theorem 8 Let
a non-decreasing function of the index of the rounds and
for any sequence of
with
. Then, there exists
such that
and
for
.
Proof: Define 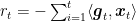

Since, we assumed that 

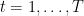



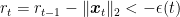
So, from the fact that 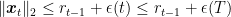

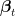
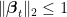
This theorem informs us of something important: any OLO algorithm that suffer a non-decreasing regret against the null competitor must predict in the form of a “vectorial” coin-betting algorithm. This immediately implies the following.
EDIT 10/23/23
The following theorem is correct but it does not prove what we need! The problem is that it proves it for a single competitor, while we would need it to hold for any fixed competitor. This difference is important because we are trying to argue that the lower bound is a certain function of the competitor, but we only evaluate this function on a single point. As I wrote in the history bits, I knew from the beginning that this was a weak proof, but over time I convinced myself that it is too weak to be useful. Sooner or later, I’ll post the correct proof in (Orabona, F., 2013) that uses a stochastic construction.
Theorem 9 Let
with
and
, such that
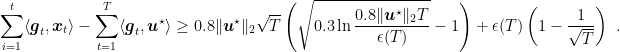
Proof: The proof works by reducing the OLO game to a coin-betting game and then using the upper bound to the reward for coin-betting games.
First, set ![{{\boldsymbol g}_t=[-c_t,0,\dots,0]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+g%7D_t%3D%5B-c_t%2C0%2C%5Cdots%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
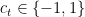



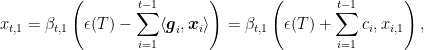
for some 

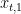


where 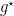

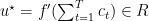
From the above theorem we have that OSD with learning rate 
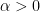
In the future classes, we will see that the connection between coin-betting and OLO can also be used to design OLO algorithm. This will give us optimal unconstrained OLO algorithms with the surprising property of not requiring a learning rate at all.
4. History Bits
The lower bound for OCO is quite standard, the proof presented is a simplified version of the one in (F. Orabona and D. Pál, 2018).
On the other hand, both the online learning literature and the optimization one almost ignored the issue of lower bounds for the unconstrained case. The connection between coin betting and OLO was first unveiled in (Orabona, F. and Pal, D., 2016). Theorem 8 is an unpublished result by Ashok Cutkosky (Thanks for allowing me to use it here!), that proved similar and more general results in his PhD thesis (Cutkosky, A., 2018). Theorem 9 is new, by me. (McMahan, B. and Abernethy, J., 2013) implicitly also proposed using the conjugate function for lower bound in unconstrained OLO.
There is a caveat in the unconstrained lower bound: A stronger statement would be to choose the norm of 
5. Exercises
Exercise 1 Fix
. Mimicking the proof of Theorem 1, prove that for any OCO algorithm there exists a
where
and the loss functions are
.
Exercise 2 Extend the proof of Theorem 1 to an arbitrary norm
.
Exercise 3 Let
be even. Prove that
Exercise 4 Find the exact expression of the conjugate function of
, for
. Hint: Wolfram Alpha or any other kind of symbolic solver can be very useful for this type of problems.

Update: Fixed a problem in the proof of Theorem 8 that one of my students anonymously posted on our internal forum.
LikeLike
Hi Francesco,
First fo all, nice post! I’m pretty sure I may be missing something simple, but I don’t quite see why Theorem 1 requires a constrained domain. If we remove that assumption, where does the proof break? We could define v and w in a slightly different way. Define them such that ||v-w||=1, and change the equality at the beginning of line 3 of the proof to an inequality (restricting the optimization domain to {v, w}). Then, I feel that all of the steps would still be valid. Of course, the diameter D won’t show up anymore, but that’s a constant. What’s wrong with these modifications?
Thanks!
LikeLike
Hi Mass,
yes, you are very right! The theorem would work also for unbounded domains. However, the resulting lower bound would be supoptimal because it would lack of the logarithmic factor we get from the other proof. I guess I should change a bit the text to explain this bit.
LikeLike
Hi Francesco,
I have a dumb question on the sentence “It is clear that the regret must be at least linear in {\|{\boldsymbol u}\|_2}”. It must be simple but I can not figure it out.
LikeLike
It is a lower bound, so we can make things easier for the algorithm and see what happens. In particular, we can pass to the algorithm how much is ||u||. In this case, we go back to the bounded case where the diameter is 2||u|| and the lower bound depends on the diameter, hence on ||u||. Now, without the information on ||u||, the performance of the algorithm can only be worse. So, the regret must be at least linear in ||u||.
LikeLiked by 1 person