In this post, we talk about implicit updates in the online convex optimization framework (reminder: online 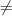
1. Implicit Updates
Let’s consider the two mostly commonly used frameworks for online learning: Online Mirror Descent (OMD) and Follow-The-Regularized-Leader (FTRL).
We already explained that in OMD we update the iterate as the minimizer of an linear approximation of the last loss function we received plus a term that measures the distance to the previous iterate:

where 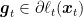
On the other hand, in FTRL we have two possibilities: we can minimize the regularized sum of the loss we have received till now or the regularized sum of the linear approximation of the losses. In the first case, we update with

while in the second case, we use

where 

Overall, we have two different frameworks and two different ways to use the loss functions in the update. So, it should be obvious that there is at least another possibility, that is OMD with exact loss. That is, we would like to consider the update

As in the FTRL case, we would expect this update to be better than the linearized one, at least empirically.
To gain some more intuition, let’s consider the simple case that 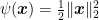
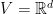

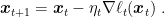
For example, with square loss and linear predictors over couples input/labels 


On the other hand, the update of OMD with the exact loss function becomes

The optimality condition tells us that 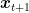

that is

So, the update is not in a closed formula anymore, but it has an implicit form, where
Remark 1. Observe that for linear losses OMD and the Implicit OMD are equivalent.
In general, calculating the update of Implicit OMD can be an annoying optimization problem. However, in some cases the Implicit OMD update can still be solved in a closed form.
Example 1. Consider again linear regression with square loss. The update of Implicit OMD becomes
To solve the equation, we take the inner product of both sides with
, to obtain
that is
Substituting this expression in (3), we have




Implicit Updates are Always Descending Till now, we have motivated implicit updates purely from an intuitive point of view: We expect this algorithm to be better because we do not approximate the loss functions. Indeed, we often gain a lot in performance switching to implicit updates. However, we can even prove that implicit updates have interesting theoretical properties.
First, contrarily to OGD, implicit updates remains “sane” even when the learning rate goes to infinity. Indeed, taking 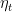
When we consider non-differentiable convex functions, there is another important difference between implicit updates and subgradient descent updates. We already saw that the subgradient might not point in a descent direction. That is, no matter how we choose 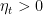


Proximal updates Are implicit updates actually an invention of online learning people? Actually, no. Indeed, these kind of updates were known at least in 1965 (!) and they were proposed for the (offline) optimization of functions with the name of proximal updates. Basically, we have a function 

starting from an initial point 
2. Passive-Aggressive
Now, let me show you that implicit updates were actually used a lot in the online literature, even if many people did not realize it.
Let’s take a look at a very famous online learning algorithm: the Passive-Aggressive (PA) algorithm. PA was a major success in online learning: 2099 citations and counting, that is huge for the online learning area. The theory was not very strong, but the performance of these algorithms was way better than anything else we had at that time. Let’s see how the PA algorithm works.
The PA algorithm was introduced before the Online Convex Optimization (OCO) framework was proposed. So, at that time, online learning for classification and regression focused on the particular case in which the loss functions have the form 


where 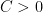
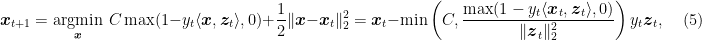
where the second equality is calculated using the optimality condition and it is left as an exercise to the reader.
So, the huge boost in performance of PA over other online algorithm is due uniquely to the implicit updates.
3. Implicit Updates on Truncated Linear Models: aProx
There is another first-order optimization algorithm inspired to implicit updates. As we said, implicit updates are rarely in a closed form. So, we can try to approximate the implicit updates in some way. One possibility is to use the implicit update on a surrogate loss function. Indeed, when we use a linear approximation we recover plain OMD. Instead, when we use the exact function we get the implicit updates. What can we use in between the two cases? We could think to use a truncated linear model. That is, in the case we know that the functions are lower bounded by some 

for any 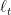
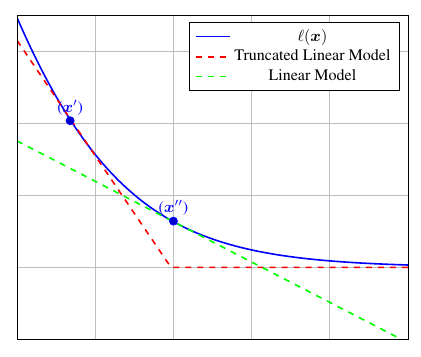
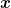 , and a linear model (Green) built around the point
, and a linear model (Green) built around the point  .
.Now, we can use these surrogate function in the implicit OMD:

Implicit OMD with truncated linear models and the squared L2 Bregman is called aProx (Asi and Duchi, 2019).
Considering 
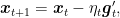
where 
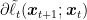
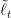
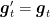

![{\alpha_t \in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha_t+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
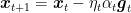
and we only need to find 
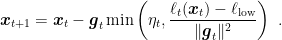
The similarity between this update and the one of PA in (5) should be adamant, that is due to the similarity between the truncated linear model and the hinge loss. Indeed, running aProx on linear classifiers with hinge loss is exactly the PA algorithm.
4. More Updates Similar to the Implicit Updates
From an empirical point of view, we can gain a lot of performance using implicit updates, even just approximating them. So, it should not be surprising if people proposed and used similar ideas in many optimization algorithm. Let me give you some examples.
The default optimization algorithm in the machine learning library Vowpal Wabbit (VW) uses the Importance Weight Aware Updates (Karampatziakis and Langford, 2011). These updates essentially approximate the implicit update using a differential equation that for linear models can be calculated in a closed formula. So, if you ever used VW, you already used a close relative of implicit updates, probably without knowing it.
Another interesting example is the setting of adaptive filtering, where one wants to minimize 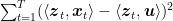
There are even interpretations of the Nesterov’s accelerated gradient method as an implicit update on a curved space (Defazio, 2019).
So, implicit updates are so “natural” that I personally think that any offline/online optimization algorithm that has good performance must be a good approximation of implict updates. Hence, I am sure there are even more examples of implicit updates hiding in other well-known algorithms.
5. Regret Guarantee for Implicit Updates
From the above reasoning, it seems very intuitive to expect a better regret bound for implicit updates. However, it turns out particularly challenging to prove a quantifiable advantage of implicit updates over OMD ones in the adversarial setting.
Here, I show a very recent result of mine on Implicit OMD that for the first time shows a clear advantage of Implicit OMD in some situations.
First, we can show the following theorem.
Theorem 1. Assume a constant learning rate
. Then, implicit OMD guarantees
Moreover, assume the distance generating function to be 1-strongly convex w.r.t.
. Then, there exists
such that we have


Proof: To obtain this bound, we proceed in a slightly different way than in the classic OMD proof. In particular, for any 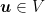

where 

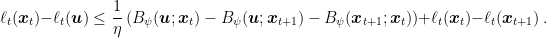
Summing over time, we get the first bound.
For the second bound, let’s now focus on the terms 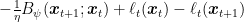


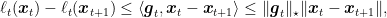
where 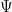

Hence, putting all together we have
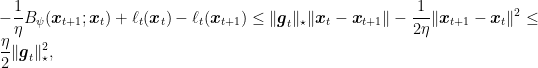
where in the last inequality we used the elementary inequality 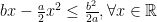
From the optimality condition of the implicit OMD update, we know that there exists 
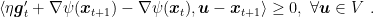
Hence, we have

where we used the convexity of the Bregman divergence in its first argument in the second inequality and the optimality condition of the update in the third inequality. This chain of inequalities implies that 

The theorem shows a possible and small improvement over the OMD regret bound. In particular, there might be sequences of losses where 
From the regret above, we have

Denoting by 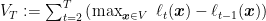

Now, in the case that the loss functions are all the same 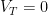

However, there is a caveat: In order to get a 

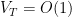

Our last observation is that we can recover the constant regret bound even for FTRL when used on the exact losses. Again, this is due to the use of the exact losses rather than the linear approximation. Remember that FTRL predicts with 

![\displaystyle \begin{aligned} \sum_{t=1}^T ( \ell_t({\boldsymbol x}_t) - \ell_t({\boldsymbol u}) ) &= \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in V} \ \psi_{1}({\boldsymbol x}) + \sum_{t=1}^T [F_t({\boldsymbol x}_t) - F_{t+1}({\boldsymbol x}_{t+1}) + \ell_t({\boldsymbol x}_t)] + F_{T+1}({\boldsymbol x}_{T+1}) - F_{T+1}({\boldsymbol u}) \\ &\leq \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in V} \ \psi_{1}({\boldsymbol x}) + \sum_{t=1}^T (\ell_t({\boldsymbol x}_{t}) - \ell_t({\boldsymbol x}_{t+1}))\\ &\leq \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in V} \ \psi_{1}({\boldsymbol x}) + \ell_1({\boldsymbol x}_1) - \ell_T({\boldsymbol x}_{T+1}) + \sum_{t=2}^T \left( \max_{{\boldsymbol x} \in V} \ \ell_t({\boldsymbol x}) - \ell_{t-1}({\boldsymbol x}) \right) \\ &= \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in V} \ \psi_{1}({\boldsymbol x}) + \ell_1({\boldsymbol x}_1) - \ell_T({\boldsymbol x}_{T+1}) + V_T~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%28+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+-+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29+%29+%26%3D+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5BF_t%28%7B%5Cboldsymbol+x%7D_t%29+-+F_%7Bt%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29+%2B+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29%5D+%2B+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7BT%2B1%7D%29+-+F_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+%5C%5C+%26%5Cleq+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%28%5Cell_t%28%7B%5Cboldsymbol+x%7D_%7Bt%7D%29+-+%5Cell_t%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29%29%5C%5C+%26%5Cleq+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Cell_1%28%7B%5Cboldsymbol+x%7D_1%29+-+%5Cell_T%28%7B%5Cboldsymbol+x%7D_%7BT%2B1%7D%29+%2B+%5Csum_%7Bt%3D2%7D%5ET+%5Cleft%28+%5Cmax_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29+-+%5Cell_%7Bt-1%7D%28%7B%5Cboldsymbol+x%7D%29+%5Cright%29+%5C%5C+%26%3D+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Cell_1%28%7B%5Cboldsymbol+x%7D_1%29+-+%5Cell_T%28%7B%5Cboldsymbol+x%7D_%7BT%2B1%7D%29+%2B+V_T%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
However, FTRL with exact losses requires to solve a finite sum optimization problem whose size grows with the number of iterations. Instead, Implicit OMD uses only one loss in each round, resulting in a closed formula in a number of interesting cases. We also note that we would have the same tuning problem as before: in order to get a constant regret when
6. History Bits
The implicit updates in online learning were proposed for the first time by (Kivinen and Warmuth, 1997). However, such update with the Euclidean divergence is the Proximal update in the optimization literature dating back at least to 1965 (Moreau, 1965)(Martinet, 1970)(Rockafellar, 1976)(Parikh and Boyd, 2014), and more recently used even in the stochastic setting (Toulis and Airoldi, 2017)(Asi and Duchi, 2019).
The PA algorithms were proposed in (Crammer et al., 2006), but the connection with implicit updates was absent in the paper. I am not sure who first realized the connection: I realized it in 2011 and I showed it to Joseph Keshet (one of the author of PA) that encouraged me to publish it somewhere. Only 10 years later, I am doing it 🙂 Note that the mistake bound proved in the PA paper is worse than the Perceptron bound. Later, we proved a mistake bound for PA that is strictly better than the classic Perceptron’s bound (Jie et al., 2010).
The very nice idea of truncated linear models was proposed by (Asi and Duchi, 2019) as a way to approximate proximal updates and retaining closed form updates.
The connection between implicit OMD and normalized LMS was shown by (Kivinen et al., 2006).
(Kulis and Bartlett, 2010) provide the first regret bounds for implicit updates that match those of OMD, while (McMahan, 2010) makes the first attempt to quantify the advantage of the implicit updates in the regret bound. Finally, (Song et al., 2018) generalize the results in (McMahan, 2010) to Bregman divergences and strongly convex functions, and quantify the gain differently in the regret bound. Note that in (McMahan, 2010)(Song et al., 2018) the gain cannot be exactly quantified, providing just a non-negative data-dependent quantity subtracted to the regret bound. The connection between temporal variation and implicit updates was shown in (Campolongo and Orabona, 2020), together with a matching lower bound.
7. Acknowledgements
Thanks to Nicolò Campolongo for feedback on a draft of this post.
8. Exercises
Exercise 1. Prove that the update of PA given above is correct.
Exercise 2. Prove that the update of aProx given above is correct.
Exercise 3. Find an learning rate strategy to adapt to the value of
without knowing it (Campolongo and Orabona, 2020).

Is the \eta/2 multiplying the first inequality of Theorem 1 a typo?
LikeLiked by 1 person
You are right! Fixed, thanks.
LikeLike