This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
Today, we will present the problem of multi-armed bandit in the adversarial setting and show how to obtain sublinear regret.
1. Multi-Armed Bandit
This setting is similar to the Learning with Expert Advice (LEA) setting: In each round, we select one expert 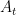

As in the learning with expert case, we need randomization in order to have a sublinear regret. Indeed, this is just a harder problem than LEA. However, we will assume that the adversary is oblivious, that is, he decides the losses of all the rounds before the game starts, but with the knowledge of the online algorithm. This makes the losses deterministic quantities and it avoids the inadequacy in our definition of regret when the adversary is adaptive (see (Arora, R. and Dekel, O. and Tewari, A., 2012)).
This kind of problems where we don’t receive the full-information, i.e., we don’t observe the loss vector, are called bandit problems. The name comes from the problem of a gambler who plays a pool of slot machines, that can be called “one-armed bandits”. On each round, the gambler places his bet on a slot machine and his goal is to win almost as much money as if he had known in advance which slot machine would return the maximal total reward.
In this problem, we clearly have an exploration-exploitation trade-off. In fact, on one hand we would like to play at the slot machine which, based on previous rounds, we believe will give us the biggest win. On the other hand, we have to explore the slot machines to find the best ones. On each round, we have to solve this trade-off.
Given that we don’t observe completely observe the loss, we cannot use our two frameworks: Online Mirror Descent (OMD) and Follow-The-Regularized-Leader (FTRL) both needs the loss functions or at least lower bounds to them.
One way to solve this issue is to construct stochastic estimates of the unknown losses. This is a natural choice given that we already know that the prediction strategy has to be a randomized one. So, in each round 

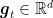
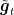
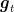

Note that this estimator has all the coordinates equal to 0, except the coordinate corresponding the arm that was pulled.
This estimator is unbiased, that is ![{\mathop{\mathbb E}_{A_t}[\tilde{{\boldsymbol g}}_t]={\boldsymbol g}_t}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5B%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5D%3D%7B%5Cboldsymbol+g%7D_t%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\tilde{g}_{t,i} = \boldsymbol{1}[A_t=i]\frac{g_{t,i}}{x_{t,i}}}](https://s0.wp.com/latex.php?latex=%7B%5Ctilde%7Bg%7D_%7Bt%2Ci%7D+%3D+%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5Cfrac%7Bg_%7Bt%2Ci%7D%7D%7Bx_%7Bt%2Ci%7D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathop{\mathbb E}_{A_t}[\boldsymbol{1}[A_t=i]]=x_{t,i}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5D%3Dx_%7Bt%2Ci%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \mathop{\mathbb E}_{A_t}[\tilde{g}_{t,i}] = \mathop{\mathbb E}_{A_t}\left[\boldsymbol{1}[A_t=i]\frac{g_{t,i}}{x_{t,i}}\right] = \frac{g_{t,i}}{x_{t,i}} \mathop{\mathbb E}_{A_t}[\boldsymbol{1}[A_t=i]] = g_{t,i}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5B%5Ctilde%7Bg%7D_%7Bt%2Ci%7D%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5Cleft%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5Cfrac%7Bg_%7Bt%2Ci%7D%7D%7Bx_%7Bt%2Ci%7D%7D%5Cright%5D+%3D+%5Cfrac%7Bg_%7Bt%2Ci%7D%7D%7Bx_%7Bt%2Ci%7D%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5D+%3D+g_%7Bt%2Ci%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s also calculate the (uncentered) variance of the coordinates of this estimator. We have
![\displaystyle \mathop{\mathbb E}_{A_t}[\tilde{g}_{t,i}^2] = \mathop{\mathbb E}_{A_t}\left[\boldsymbol{1}[A_t=i]\frac{g^2_{t,i}}{x^2_{t,i}}\right] = \frac{g_{t,i}^2}{x_{t,i}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5B%5Ctilde%7Bg%7D_%7Bt%2Ci%7D%5E2%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7BA_t%7D%5Cleft%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5Cfrac%7Bg%5E2_%7Bt%2Ci%7D%7D%7Bx%5E2_%7Bt%2Ci%7D%7D%5Cright%5D+%3D+%5Cfrac%7Bg_%7Bt%2Ci%7D%5E2%7D%7Bx_%7Bt%2Ci%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
We can now think of using OMD with an entropic regularizer and the estimated losses. Hence, assume 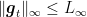
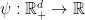

![{{\boldsymbol x}_1=[1/d, \dots, 1/d]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+x%7D_1%3D%5B1%2Fd%2C+%5Cdots%2C+1%2Fd%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

We can now take the expectation at both sides and get
![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,A_t}\right] - \sum_{t=1}^T \langle {\boldsymbol g}_t,{\boldsymbol u}\rangle &=\mathop{\mathbb E}\left[\sum_{t=1}^T \langle {\boldsymbol g}_t,{\boldsymbol x}_t\rangle\right] - \sum_{t=1}^T \langle {\boldsymbol g}_t,{\boldsymbol u}\rangle & (1) \\ &=\mathop{\mathbb E}\left[\sum_{t=1}^T \langle \tilde{{\boldsymbol g}}_t,{\boldsymbol x}_t\rangle - \sum_{t=1}^T \langle \tilde{{\boldsymbol g}}_t,{\boldsymbol u}\rangle\right] \\ &\leq \frac{\ln d}{\eta} + \frac{\eta}{2}\sum_{t=1}^T \mathop{\mathbb E}[\|\tilde{{\boldsymbol g}}_t\|_\infty^2] \\ &\leq \frac{\ln d}{\eta} + \frac{\eta}{2}\sum_{t=1}^T \sum_{i=1}^d \frac{g_{t,i}^2}{x_{t,i}}~. & (2) \\\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D%5Cright%5D+-+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D%5Crangle+%26%3D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+x%7D_t%5Crangle%5Cright%5D+-+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D%5Crangle+%26+%281%29+%5C%5C+%26%3D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%2C%7B%5Cboldsymbol+x%7D_t%5Crangle+-+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%2C%7B%5Cboldsymbol+u%7D%5Crangle%5Cright%5D+%5C%5C+%26%5Cleq+%5Cfrac%7B%5Cln+d%7D%7B%5Ceta%7D+%2B+%5Cfrac%7B%5Ceta%7D%7B2%7D%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5C%7C_%5Cinfty%5E2%5D+%5C%5C+%26%5Cleq+%5Cfrac%7B%5Cln+d%7D%7B%5Ceta%7D+%2B+%5Cfrac%7B%5Ceta%7D%7B2%7D%5Csum_%7Bt%3D1%7D%5ET+%5Csum_%7Bi%3D1%7D%5Ed+%5Cfrac%7Bg_%7Bt%2Ci%7D%5E2%7D%7Bx_%7Bt%2Ci%7D%7D%7E.+%26+%282%29+%5C%5C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We are now in troubles, because the terms in the sum scale as 
One way to do it, is to take a convex combination of ![{\tilde{{\boldsymbol x}}_t=(1-\alpha) {\boldsymbol x}_t + \alpha [1/d, \dots, 1/d]}](https://s0.wp.com/latex.php?latex=%7B%5Ctilde%7B%7B%5Cboldsymbol+x%7D%7D_t%3D%281-%5Calpha%29+%7B%5Cboldsymbol+x%7D_t+%2B+%5Calpha+%5B1%2Fd%2C+%5Cdots%2C+1%2Fd%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


The same probability distribution is used in the estimator:

We can have that 

Observing that ![{\mathop{\mathbb E}[\sum_{i=1}^d \tilde{g}_{t,i}]=\sum_{i=1}^d g_{t,i}\leq d L_\infty}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Csum_%7Bi%3D1%7D%5Ed+%5Ctilde%7Bg%7D_%7Bt%2Ci%7D%5D%3D%5Csum_%7Bi%3D1%7D%5Ed+g_%7Bt%2Ci%7D%5Cleq+d+L_%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb E}\left[\sum_{t=1}^T \langle \tilde{{\boldsymbol g}}_t, \tilde{{\boldsymbol x}}_t-{\boldsymbol u}\rangle \right] \leq \mathop{\mathbb E}\left[\sum_{t=1}^T \langle \tilde{{\boldsymbol g}}_t, (1-\alpha){\boldsymbol x}_t-{\boldsymbol u}\rangle \right] + \alpha L_\infty T \leq \mathop{\mathbb E}[\text{Regret}_T({\boldsymbol u})] + \alpha L_\infty T~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%2C+%5Ctilde%7B%7B%5Cboldsymbol+x%7D%7D_t-%7B%5Cboldsymbol+u%7D%5Crangle+%5Cright%5D+%5Cleq+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%2C+%281-%5Calpha%29%7B%5Cboldsymbol+x%7D_t-%7B%5Cboldsymbol+u%7D%5Crangle+%5Cright%5D+%2B+%5Calpha+L_%5Cinfty+T+%5Cleq+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Ctext%7BRegret%7D_T%28%7B%5Cboldsymbol+u%7D%29%5D+%2B+%5Calpha+L_%5Cinfty+T%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Putting together the last inequality and the upper bound to the expected regret in (2), we have
![\displaystyle \mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,A_t}\right] - \sum_{t=1}^T \langle {\boldsymbol g}_t,{\boldsymbol u}\rangle \leq \frac{\ln d}{\eta} + \frac{\eta d^2 L_\infty^2 T}{2 \alpha} + \alpha L_\infty T~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D%5Cright%5D+-+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D%5Crangle+%5Cleq+%5Cfrac%7B%5Cln+d%7D%7B%5Ceta%7D+%2B+%5Cfrac%7B%5Ceta+d%5E2+L_%5Cinfty%5E2+T%7D%7B2+%5Calpha%7D+%2B+%5Calpha+L_%5Cinfty+T%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Setting 
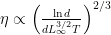

This is way worse than the 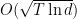
2. Exponential-weight algorithm for Exploration and Exploitation: Exp3
It turns out that the algorithm above actually works, even without the mixing with the uniform distribution! We were just too loose in our regret guarantee. So, we will analyse the following algorithm, that is called Exponential-weight algorithm for Exploration and Exploitation (Exp3), that is nothing else than OMD with entropic regularizer and stochastic estimates of the losses. Note that now we will assume that ![{g_{t,i} \in [0, L_\infty]}](https://s0.wp.com/latex.php?latex=%7Bg_%7Bt%2Ci%7D+%5Cin+%5B0%2C+L_%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Let’s take another look to the regret guarantee we have. From the OMD analysis, we have the following one-step inequality that holds for any

Let’s now focus on the term 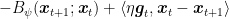

![{\alpha \in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
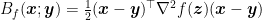

![{\alpha_t\in[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha_t%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

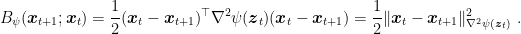
So, assuming the Hessian in 
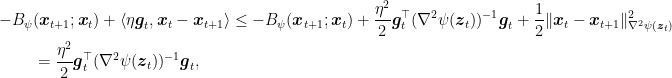
where we used Fenchel-Young inequality with the function 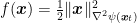
![{{\boldsymbol x}_t=[1/3,1/3,1/3]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+x%7D_t%3D%5B1%2F3%2C1%2F3%2C1%2F3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\boldsymbol x}_t=[0.1,0.45,0.45]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+x%7D_t%3D%5B0.1%2C0.45%2C0.45%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


This expression of the Hessian a regret of

where ![{\alpha_t \in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha_t+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
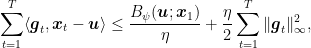
that we derived just using the strong convexity of the entropic regularizer.
However, we don’t know the exact value of 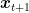


In the next lecture, we will see an alternative way to analyze OMD that will give us exactly this kind of guarantee for Exp3 and will use give us the optimal regret guarantee using the Tsallis entropy in few lines of proof.
3. History Bits
The algorithm in Algorithm 1 is from (Cesa-Bianchi, N. and Lugosi, G. , 2006, Theorem 6.9). The Exp3 algorithm was proposed in (Auer, P. and Cesa-Bianchi, N. and Freund, Y. and Schapire, R. E., 2002).
