Disclaimer: This post assumes that you understand how FTRL works. If not, please take a look here.
In this post, I explain a variation of the EG/Hedge algorithm, called AdaHedge. The basic idea is to design an algorithm that is adaptive to the sum of the squared 
First, consider the case in which we use as constant regularizer the negative entropy 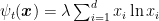
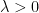



where we upper bounded the negative entropy of 

This suggests that the optimal 

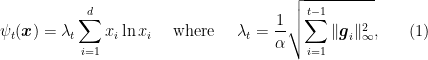
where 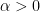


Note that this choice makes the regularizer non-decreasing over time and immediately gives us
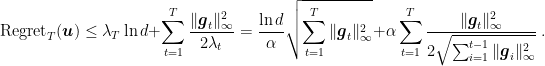
At this point, we might be tempted to use Lemma 1 from the L* post to upper bound the sum in the upper bound, but unfortunately we cannot! Indeed, the denominator does not contain the term 



where we used the definition of 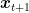

where we used the fact that the minimum between two numbers is less than their harmonic mean. Assuming 

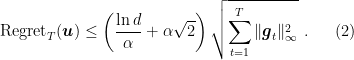
The bound and the assumption on 

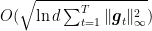
We might consider ourselves happy, but there is a clear problem in the above algorithm: the choice of
Let’s consider a generic regularizer 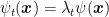

where we assume
Now, observe that the sum is unlikely to disappear for this kind of algorithms, so we could try to make the term 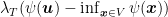
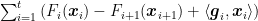

Now, we can set 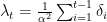

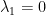
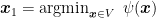

Setting 
With this choice of the regularizer, we can simplify a bit the expression of 

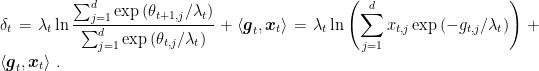
Overall, we get the pseudo-code of AdaHedge in Algorithm 1.

So, now we need an upper bound for 

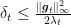

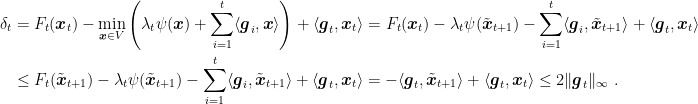
Hence, we have

We can solve this recurrence using the following Lemma, where 

Lemma 1. Let
be any sequence of non-negative real numbers. Suppose that
is a sequence of non-negative real numbers satisfying
Then, for any
,
.

Proof: Observe that
![\displaystyle \Delta_T^2 = \sum_{t=1}^T (\Delta_t^2 - \Delta_{t-1}^2) = \sum_{t=1}^T \left[(\Delta_t - \Delta_{t-1})^2 + 2 (\Delta_t - \Delta_{t-1}) \Delta_{t-1}\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CDelta_T%5E2+%3D+%5Csum_%7Bt%3D1%7D%5ET+%28%5CDelta_t%5E2+-+%5CDelta_%7Bt-1%7D%5E2%29+%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%5B%28%5CDelta_t+-+%5CDelta_%7Bt-1%7D%29%5E2+%2B+2+%28%5CDelta_t+-+%5CDelta_%7Bt-1%7D%29+%5CDelta_%7Bt-1%7D%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
We bound each term in the sum separately. The left term of the minimum inequality in the definition of 

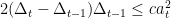


So, overall we got
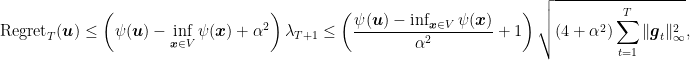
and setting 
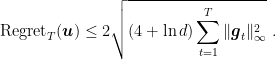
Note that this is roughly the same regret in (2), but the very important difference is that this new regret bound depends on the much tighter quantity 


There is an important lesson to be learned from AdaHedge: the regret is not the full story and algorithms with the same worst-case guarantee can exhibit vastly different empirical behaviors. Unfortunately, this message is rarely heard and there is a part of the community that focuses too much on the worst-case guarantee rather than on the empirical performance. Even worse, sometimes people favor algorithms with a “more elegant analysis” completely ignoring the likely worse empirical performance.
1. History Bits
The use of FTRL with the regularizer in (1) was proposed in (Orabona and Pál, 2015), I presented a simpler version of their proof that does not require Fenchel conjugates. The AdaHedge algorithm was introduced in (van Erven et al., 2011) and refined in (de Rooij et al., 2014). The analysis reported here is from (Orabona and Pál, 2015), that generalized AdaHedge to arbitrary regularizers in AdaFTRL. Additional properties of AdaHedge for the stochastic case were proven in (van Erven et al., 2011).
2. Exercises
Exercise 1. Implement AdaHedge and compare its empirical performance to FTRL with the time-varying regularizer in (1).

Hi, again your blog is making my life better. I think that it should be ‘\alpha = max (4 …)’ in (2) not min and the inequality in the assumption should \geq not strict. And It’s going to be 4 anyway unless d is in billions. Aaaand if we assume \alpha \leq 4, 4 ends up being optimal so perhaps just set alpha to 4?
Typo in bounding lambda middle step of the third equation (“Hence, we have …” : ‘\lambda_{t+1} = \lambda{t} +\alpha\delta_t’ instead of ‘\lambda_{t+1} = \lambda{t} +\farc{\delta_t}{\alpha^2}’
Missing brackets in the first sum of proof of lemma 1 (for clarity).
LikeLike
Happy to know you like it!
For the setting of alpha, if we set alpha=4, then the bound would depend asymptotically in d as log(d) instead of sqrt{log(d)}. As you observe, alpha=4 would be the optimal setting for any reasonable d, but theoreticians really like to have the optimal dependency in their asymptotics 🙂
Also, fixed all the bugs you found, thanks again!
LikeLiked by 1 person
thanks!!
LikeLike
Hi, a small typo. In the align section
begin{align*}
F_t(x_t) – F_{t+1}(x_{t+1}) + langle g_t, x_t rangle
&leq F_t(x_{t+1}) – F_{t+1}(x_{t+1}) + langle g_t, x_t rangle
&= psi_t(x_{t+1}) + sum_{i}^{t-1} langle g_i, x_{t+1} rangle
psi_{t+1}(x_{t+1}) – sum_{i=1}^{t} langle g_i, x_{t+1} rangle
&leq -langle g_t, x_{t+1} rangle + langle g_t, x_t rangle
&leq 2 |g_t|_infty,
end{align*}
you missed out writing the langle g_t, x_t rangle term in the RHS of the equality.
LikeLike
(sorry for the huge delay, somehow I missed your message…)
I am not sure I see the error, maybe I already fixed it?
LikeLike