This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
1. Online Mirror Descent

Last time we introduced the Online Mirror Descent (OMD) algorithm, in Algorithm 1. We also said that we need one of these two assumptions to hold.
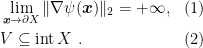
We also proved the following Lemma.
Lemma 1 Let
the Bregman divergence w.r.t.
and assume
to be
-strongly convex with respect to
in
. Let
a closed convex set. Set
. Assume (1) or (2) hold. Then,
and with the notation in Algorithm 1, the following inequality holds
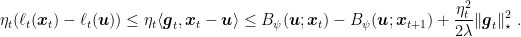
Today, we will finally prove a regret bound for OMD.
Theorem 2 Set
such that
. Assume
. Then, under the assumptions of Lemma 1 and
Moreover, if
is constant, i.e.
, we have
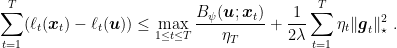

Proof: Fix 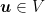
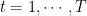

where we denoted by 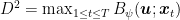
The second statement is left as an exercise.

In words, OMD allows us to prove regret guarantees that depend on arbitrary couple of dual norms 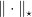
Overall, the regret bound is still of the order of 

to achieve a regret bound of 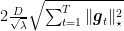

Next time, we will see practical examples of OMD that guarantee strictly better regret than OSD. As we did in the case of AdaGrad, the better guarantee will depend on the shape of the domain and the characteristics of the subgradients.
Instead, now we see the meaning of the “Mirror”.
2. The “Mirror” Interpretation
First, we need a couple of convex analysis results.
When we introduced the Fenchel conjugate, we said that 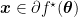


Theorem 3 Let
be a proper, convex, and closed function,
strongly convex w.r.t.
is finite everywhere and differentiable.
-smooth w.r.t.
We will also use the following optimality condition.
Theorem 4 Let
proper. Then
iff
.
Hence, we can state the following theorem.
Theorem 5 Let
. Then
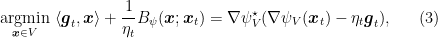
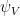 the restriction of
the restriction of  .
. Proof: Consider the update rule in Algorithm 1 and let’s see
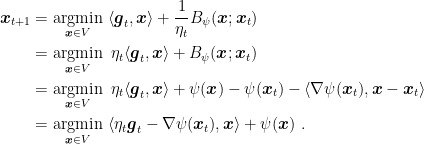
Now, we want to use the first order optimality condition, so we have to use a little bit of subdifferential calculus. Given that 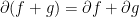
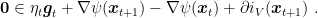
that is
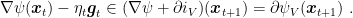
or equivalently

Using that fact that 
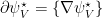
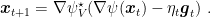
Noting that 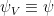

Let’s explain what this theorem says. We said that Online Mirror Descent extends the Online Subgradient Descent method to non-euclidean norms. Hence, the regret bound we proved contains dual norms, that measure the iterate and the gradients. We also said that it makes sense to use a dual norm to measure a gradient, because it is a natural way to measure how “big” is the linear functional 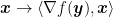

So, in OMD we need a way to go from one space to the other. And this is exactly the role of 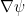

Example 1 Let
equal to
where
. Then,
Solving the constrained optimization problem, we have
. Hence, we have
that is finite everywhere and differentiable. So, we have
and
So, using (3), we obtain exactly the update of projected online subgradient descent.
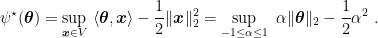


3. Yet Another Way to Write the OMD Update
There exists yet another way to write the update of OMD. This third method uses the concept of Bregman projections. Extending the definition of Euclidean projections, we can define the projection with respect to a Bregman divergence. Let 

In the online learning literature, the OMD algorithm is typically presented with a two step update: first, solving the argmin over the entire space and then projecting back over 
First, we prove a general theorem that allows to break the constrained minimization of functions in the minimization over the entire space plus and Bregman projection step.
Theorem 6 Let
proper, closed, strictly convex, and differentiable in
. Also, let
a non-empty, closed convex set with
and assume that
exists and
. Denote by
. Then the following hold:
exists and is unique.
.
Proof: For the first point, from (Bauschke, H. H. and Combettes, P. L., 2011, Proposition 11.12) and the existence of 

For the second point, from the definition of 
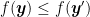


that is 

Now, note that, if 
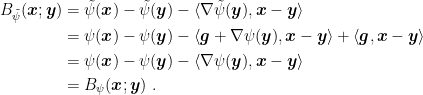
Also, defining 


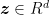
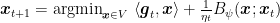

The advantage of this update is that sometimes it gives two easier problems to solve rather than a single difficult one.
4. History Bits
Most of the online learning literature for OMD assumes 
5. Exercises
Exercise 1 Find the conjugate function of
defined over
.
Exercise 2 Generalize the concept of strong convexity to Bregman functions, instead of norms, and prove a logarithmic regret guarantee for such functions using OMD.

Very nice post! I never fully understood why the Legendre assumption was needed.
LikeLiked by 1 person
Hi, I have one question regarding Example 1: the supremum in the Fenchel conjugate of \psi(\theta) was written as a supremum of an expression dependent on \alpha in [-1, 1]. Could you elaborate on how the supremum can be written in that form? Thanks.
LikeLike
You can write x in the supremum as the sum of two orthogonal vectors: one parallel to theta and one orthogonal to theta. So, now you can maximize over both vectors. The orthogonal part can only decrease the argument of the sup, so it has to be zero. Hence, the sup over x in V is actually a sup over a vector parallel to theta with bounded norm and it becomes a sup over alpha in [-1,1]. Does it make sense?
LikeLiked by 1 person
That makes sense. After posting the question I realized that we could also use an observation that for whatever x^\star that maximizes \psi, if it is not already parallel to \theta then it can be rotated so that x^\star is parallel to \theta and the dot product is increased (while the norm ||x^\star|| stays the same). This argument holds only when the feasible set V is closed under rotation, which it is in this case since V is an Euclidean ball.
LikeLiked by 1 person
Excellent post! I’ve learned a lot – thank you very much!
I have a quick question regarding the regret bound in Theorem 2: if the norm of the subgradient g_t is in general unbounded for x_t in V. Are there any effective upper bounds we could use? Thank you.
LikeLike
In general, you cannot prove a vanishing average regret without any assumption on the losses. Assuming bounded subgradients is a common assumption, but other assumptions are possible too. For example, you could assume that the losses are smooth (that is, the gradient is Lipschitz), see post on L* bounds. In other cases, we can still have vanishing average regret with unbounded losses, as in the case of Universal Portfolio that I’ll post soon. So, it really depends on your specific application what kind of assumption you can use.
LikeLike
Dear Professor Orabona,
I’m student from Institute of Mathematics, Mechanics and Computer Sciences of the Southern Federal University (Russia), Viacheslav D. Potapov.
I’m a bit confused about choosing the adaptive for Lipschitz constant step sizes for OMD (p.52 immediately before section 6.4.1 on arxive 2025 version OR in the end of the first section here). Can you clarify the appearance of D in eta_t there, please ?
If D^2 is still max of Bregman div over T rounds as in the previous theorem, we need to know feature.
Do we implicitly assume that B_psi is bounded over int V times int V with D^2 ?
In the third case of the evidence of the boundedness of that Bregman; it seems to me being very cumbersome what facts about psi and V we need to combine to establish that.
loss_t is Lipschitz at feasible set, but strong convexity concern psi; and therefore this two facts doesn’t require boundedness of V. Moreover, it seems to me that assumption (6.5 from arxive) that makes it impossible to coexist two facts: x_{t+1} at the boundary of X and the first order optimality condition; imply unboundedness of B_psi(cdot ,x_t) even in the case of bounded V…
Taking this opportunity, I would like to thank you very much for your efforts in shedding light on online optimization for beginners !)
LikeLike
Thanks for your kind words, I am glad you found my notes useful.
You are right in all your observations! In particular, that setting of eta implicitly assumes that B_psi(x;y) to be bounded for all x and y in V. As you observe, if the function psi is steep at the boundary, then the Bregman cannot be bounded. So, we can use that choice only in some very restrictive settings, for example, psi is the squared p-norm and the feasible set V is bounded.
I am not aware of any paper suggesting to try to “track” D over the iterations. In principle one could try it, but I am not sure if the final regret bound would be meaningful or not.
Overall, this issue is not so important because it is completely resolved in FTRL, where we don’t need to assume a bounded Bregman anymore.
I hope this clarifies your doubts.
LikeLike
I added the definition of D^2 and the assumption of boundedness explicitly, I’ll make the same change to the arxiv version. Is your name Viacheslav D. Potapov? If yes, I’ll add it to the acknowledgements in the arxiv version.
LikeLiked by 1 person
Oh, sure it’s a pure pleasure for me, but I think you shouldn’t. Indeed, my clarifying question is just a very small thing
With great respect, Viacheslav D. Potapov ))
LikeLiked by 1 person
Or fourth case, does there any simple adaptation to D in eta_t via D_t^2 = max B_psi(u,x_i) where i over [t], as for L sqrt(T) ?
LikeLike