While preparing the post on faster rates for saddle-point optimization with optimistic Online Convex Optimization algorithms, I realized I never explained Optimistic Online Mirror Descent (OMD). So, here it is: Optimistic OMD!
The post will be short: the algorithm is straightforward, especially after knowing Optimistic Follow-The-Regularized-Leader (FTRL), and the proof is the simplest one I know. Yet, there are few interesting bits that one can extract from this short proof.
1. Optimistic OMD
I have already discussed the Optimistic version of FTRL and show how the proof is immediate once we change the regularizers. By immediate, I mean that it is just the FTRL regret equality and a telescopic sum over the hints. Here, I’ll show that a regret bound for Optimistic OMD can be proven in the exact same way.
I always found previous proofs of optimistic OMD unnecessarily complex. Instead, here we show that the proof is just the usual OMD proof applied to a different sequence of subgradients and a telescopic sum: easy peasy! I want to stress that this is not a “trick”, but the very essence of the Optimistic OMD algorithm.
First, let’s introduce the Optimistic OMD algorithm, see Algorithm 1. Here, at round 


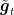

To gain some intuition on why this update makes sense, consider the case that 

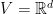

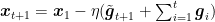
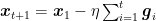

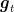
Note that one might be tempted to multiply 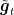

One might also be tempted to find a way to study this algorithm with a special proof. However, the one-step lemma we proved for OMD is essentially tight: we only used two inequalities, one to deal with the set 
Theorem 1. Let
the Bregman divergence w.r.t.
and assume
to be proper, closed, and
-strongly convex with respect to
in
a non-empty closed convex set. With the notation in Algorithm 1, assume
exists, and it is in
.
Assume. Then, and
, the following regret bounds hold
Moreover, if
is constant, i.e.,
, we have
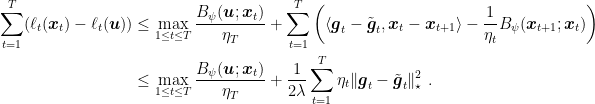

Proof: The proof closely follows the one of Lemma 4 in the OMD proof with 

Summing over 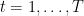

Summing the last terms on the r.h.s., we have that
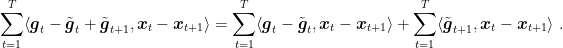
Finally, observe that

Given that loss on the rounds 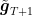
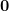
To obtain the second inequalities, we use the strong convexity of

These regret bounds are essentially the same of the ones of Optimistic FTRL, minus the intrinsic differences between FTRL and OMD. In particular, the constant factors are also the same. Hence, similar results to the ones that we proved for Optimistic FTRL can be proved for Optimistic OMD.
As said above, we will use this result to show how to accelerate the optimization of smooth saddle-point problems.
2. History Bits
The original Optimistic OMD was proposed in Rakhlin and Sridharan (2013) with two-updates-per-step. Later, Joulani et al. (2017) showed that the same bounds could be obtained with a simpler one-update-per-step version of Optimistic OMD, that is the version I describe here. The proof I present here is based on the one I proposed for Optimistic FTRL.
