This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
In this lecture, we will introduce the Online Mirror Descent (OMD) algorithm. To explain its genesis, I think it is essential to understand what subgradients do. In particular, the negative subgradients are not always pointing towards a direction that minimizes the function. We already discussed this problem in a previous blog post, but copy&paste is free so I’ll repeat the important bits here.
1. Subgradients are not Informative
You know that in online learning we receive a sequence of loss functions and we have to output a vector before observing the loss function on which we will be evaluated. However, we can gain a lot of intuition if we consider the easy case that the sequence of loss functions is always a fixed function, i.e., 
That said, we proved that the convergence of Online Subgradient Descent (OSD) depends on the following key property of the subgradients:

In words, to minimize the left hand side of this equation, it is enough to minimize the right hand side, that is nothing else than the instantaneous linear regret on the linear function 
So, take a look at the following examples that illustrate the fact that a subgradient does not always point in a direction where the function decreases.
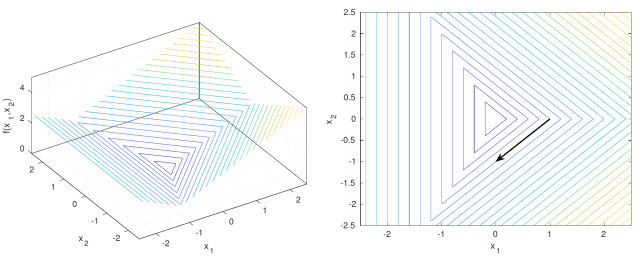
![{f(\boldsymbol x)=\max[-x_1,x_1-x_2,x_1+x_2]}](https://s0.wp.com/latex.php?latex=%7Bf%28%5Cboldsymbol+x%29%3D%5Cmax%5B-x_1%2Cx_1-x_2%2Cx_1%2Bx_2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{f(\boldsymbol x)=\max[x_1^2+(x_2+1)^2,x_1^2+(x_2-1)^2]}](https://s0.wp.com/latex.php?latex=%7Bf%28%5Cboldsymbol+x%29%3D%5Cmax%5Bx_1%5E2%2B%28x_2%2B1%29%5E2%2Cx_1%5E2%2B%28x_2-1%29%5E2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The negative subgradient is indicated by the black arrow.
. The negative subgradient is indicated by the black arrow.Let
, see Figure 1. The vector
is a subgradient in
of
. No matter how we choose the stepsize, moving in the direction of the negative subgradient will not decrease the objective function. An even more extreme example is in Figure 2, with the function
. Here, in the point
, any positive step in the direction of the negative subgradient will increase the objective function.
2. Reinterpreting the Online Subgradient Descent Algorithm.
How Online Subgradient Descent works? It works exactly as I told you before: thanks to (1). But, what does that inequality really mean?
A way to understand how OSD algorithms works is to think that it minimizes a local approximation of the original objective function. This is not unusual for optimization algorithms, for example the Netwon’s algorithm constructs an approximation with a Taylor expansion truncated to the second term. Thanks to the definition of subgradients, we can immediately build a linear lower bound to a function 


So, in our setting, this would mean that we update the online algorithm with the minimizer of a linear approximation of the loss function you received. Unfortunately, minimizing a linear function is unlikely to give us a good online algorithm. Indeed, over unbounded domains the minimum of a linear function is 
So, let’s introduce the other key concept: we constraint the minimization of this lower bound only in a neighborhood of 

Equivalently, for some 

This is a well-defined update scheme, that hopefully moves 
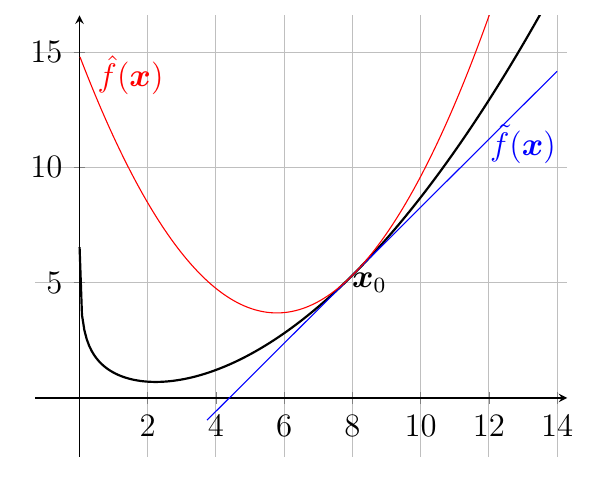 .
.And now the final element of our story: the argmin in (2) is exactly the update we used in OSD! Indeed, solving the argmin and completing the square, we get
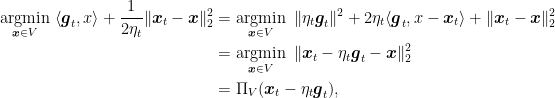
where 


The new way to write the update of OSD in (2) will be the core ingredient for designing Online Mirror Descent. In fact, OMD is a strict generalization of that update when we use a different way to measure the locality of 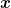
To answer these questions we have to introduce another useful mathematical object: the Bregman divergence.
3. Convex Analysis Bits: Bregman Divergence
We first give a new definition, a slightly stronger notion of convexity.
Definition 1 Let
and

From the definition, it is immediate to see that strong convexity w.r.t. any norm implies strict convexity. Note that for a differentiable function, strict convexity also implies that 

We now define our new notion of “distance”.
Definition 2 Let
be strictly convex and continuously differentiable on
. The Bregman Divergence w.r.t.
is
defined as

From the definition, we see that the Bregman divergence is always non-negative for 




Let me give you some more intuition on the concept Bregman divergence. Consider the case that 
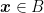
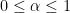

where 
We can also lower bound the Bregman divergence if the function 
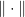

Example 2 If
, then
.
Example 3 If
and
, then
, that is the Kullback-Leibler divergence between the discrete distributions
We also have the following lemma that links the Bregman divergences between 3 points.
Lemma 3 (Chen, Gong and Teboulle, Marc, 1993) Let
the Bregman divergence w.r.t.
and
, the following identity holds
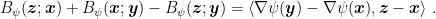
4. Online Mirror Descent
Based on what we said before, we can start from the equivalent formulation of the OSD update

and we can change the last term with another measure of distance. In particular, using the Bregman divergence w.r.t. a function
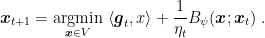
These two updates are exactly the same when 
So we get the Online Mirror Descent algorithm in Algorithm 4.

However, without an additional assumption, this algorithm has a problem. Can you see it? The problem is that 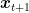

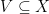

To fix this problem, we need either one of the following assumptions

If either of these conditions are true, the update is well-defined on all rounds (proof left as an exercise).
Now we have a well-defined algorithm, but does it guarantee a sublinear regret? We know that at least in one case it recovers the OSD algorithm, that does work. So, from an intuitive point of view, how well the algorithm work should depend on some characteristic on
To analyze OMD, we first prove a one step relationship, similar to the one we proved for Online Gradient Descent and OSD. Note how in this Lemma, we will use a lot of the concepts we introduced till now: strong convexity, dual norms, subgradients, Fenchel-Young inequality, etc. In a way, over the past lectures I slowly prepared you to be able to prove this lemma.
Lemma 4 Let
a convex set. Set
. Assume (4) or (5) hold. Then,
and with the notation in Algorithm 1, the following inequality holds
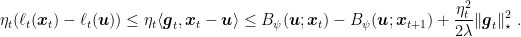
Proof: From the optimality condition for the update of OMD, we have
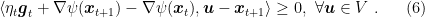
From the definition of subgradient, we have that
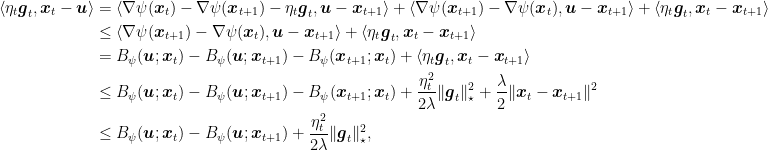
where in the second inequality we used (6), in the second equality we used Lemma 3, in the third inequality we used 
The lower bound with the function values is due, as usual, to the definition of subgradients.

Next time, we will see how to use this one step relationship to prove a regret bound, that will finally show us if and when this entire construction is a good idea. In fact, it is worth stressing that the above motivation is not enough in any way to justify the existence of the OMD algorithm. Also, next time we will explain why the algorithm is called Online “Mirror” Descent.
5. Exercises
Exercise 1 Prove that the
Exercise 2 Derive a closed form update for OMD when using the
.
6. History Bits
Mirror Descent (MD) was introduced by (Nemirovsky, A.S. and Yudin, D., 1983) in the batch setting. The description of MD with Bregman divergence that I described here (with minor changes) was done by (Beck, A. and Teboulle, M., 2003). The minor changes are in decoupling the domain

Hi Francesco, I think there’s a mistake in the first equation after fig. 4. Shouldn’t it be $ \argmin_{x \in V} \langle g_t, x – x_t \rangle + … $ instead of just $ \argmin_{x \in V} \langle g_t, x \rangle + … $. If that’s the case, then the error is propagated also below in Section 4, when you define the OSD and Mirror Descent updates (and the algorithm as well).
Also, could you clarify on the first statement of the proof in Lemma 4? Using the optimality condition, I get that
$$ \langle \eta_t g_t, x_{t+1} – x_t \rangle + B_{\psi}(x_{t+1}, x_t) \leq eta_t \langle g_t, u – x + B_{\psi}(u, x_t) $$
Doing calculations,
$$ \langle \eta_t g_t – \nabla \psi(x_t), u – x_{t+1} \rangle + \psi(u) – \psi(x_{t+1}) \geq 0 $$
Now we need an upper bound on $ \psi(u) – \psi(x_{t+1}) $, but using the definition of Bregman divergence we only get a lower bound in terms of $ \nabla \psi(x_{t+1})^\top (u – x_{t+1}) $..
LikeLike
Hi Nicolò,
1) the argmin does not change if we add constant terms w.r.t. x, i.e. the position of the minimum does not change if I move the function up or down.
2) by optimality condition, I mean Theorem 5 in https://parameterfree.com/2019/09/11/online-gradient-descent/
Does it make sense?
LikeLike
Yes, thanks!
LikeLiked by 1 person
Sholdn’t it be f(y) instead of y in the right hand side of Definition 1 ?
LikeLiked by 1 person
Yes! Fixed, thanks.
LikeLike
Hello, Francesco. I have a question about the well-definedness of mirror descent. How can we formally show that given assumption 4, the next iterate $x_{t+1}$will not be on the boundary of $X$. You leave it as an exercise, but I can’t figure it out. I am stuck at why we often assume this condition and call this kind of $\phi$ Legendre function.
LikeLike
Hi Frankie, to have the OMD update well-defined we need $x_{t+1}$ to be in the interior of $X$, because in the next step we need to evaluate the second argument of the Bregman function that is defined only in the interior of $X$. So, assumption (4) says that $\psi$ is a barrier function for $X$, hence informally when we calculate $x_{t+1}$ this condition will assure that the argmin will be in the interior of $X$. Does it make sense?
LikeLike
Thank you, Francesco. I know informally the assumption (4) will assure that the argmin will be in the interior of $X$. I just don’t know how can I formally prove it. Do you have any reference materials about proving it?
LikeLike
When I wrote it, I had in mind all the properties associated with being Legendre, see “essentially smooth” in Rockafellar. In alternative, remember that the OMD update can be written as unconstrained argmin + Bregman projection and take a look at Theorem 3.12 in https://cmps-people.ok.ubc.ca/bauschke/Research/07.pdf
LikeLike
Thank you so much.
LikeLiked by 1 person