This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
In the last lecture, we have shown a very simple and parameter-free algorithm for Online Convex Optimization (OCO) in 1-dimension. Now, we will see how to reduce OCO in a 
1. Coordinate-wise Parameter-free OCO
We have already seen that it is always possible to decompose an OCO problem over the coordinate and use a different 1-dimensional Online Linear Optimization (OLO) algorithm on each coordinate. In particular, we saw that

where the 

Hence, if we have a 1-dimensional OLO algorithm, we can

The regret bound we get is immediate: We just have to sum the regret over the coordinates.
Theorem 1 With the notation in Algorithm 1, assume that
. Then,
, the following regret bounds hold
where
is a universal constant.

Note that the Theorem above suggests that in high dimensional settings 

2. Parameter-free in Any Norm
The above reductions works only with in a finite dimensional space. Moreover, it gives a dependency on the competitor w.r.t. the 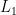
This reduction requires an unconstrained OCO algorithm for the 1-dimensional case and an algorithm for learning in 
We can formalize this idea in the following Theorem.

Theorem 2 Denote by
the linear regret of algorithm
for any
in the unit ball w.r.t a norm
, and
the linear regret of algorithm
for any competitor
. Then, for any
, Algorithm 2 guarantees regret
Further, the subgradients
sent to
.

Proof: First, observe that 




Remark 1 Note that the direction vector is not constrained to have norm equal to 1, yet this does not seem to affect the regret equality.
We can instantiate the above theorem using the KT betting algorithm for the 1d learner and OMD for the direction learner. We obtain the following examples.
Example 1 Let
and learning rate
. Let
the KT algorithm for 1-dimensional OCO with
. Assume the loss functions are
-Lipschitz w.r.t. the
. Then, using the construction in Algorithm 2, we have
Using an online-to-batch conversion, this algorithm is a stochastic gradient descent procedure without learning rates to tune.

To better appreciate this kind of guarantee, let’s take a look at the one of Follow-The-Regularized-Leader (Online Subgradient Descent can be used in unbounded domains only with constant learning rates). With the regularizer 

So, to get the right dependency on 

In the same way, we can even have a parameter-free regret bound for 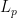
Example 2 Let
and learning rate
. Let
. Then, using the construction in Algorithm 2, we have
If we want to measure the competitor w.r.t the
and
such that
. Now, assuming that
. Hence, we have to divide all the losses by
and, for all
, we obtain


Note that the regret against 
Proposition 3 Let
an OLO algorithm that predicts
for any
for OCO is

3. Combining OCO Algorithms
Finally, we now show a useful application of the parameter-free OCO algorithms property to have a constant regret against
Theorem 4 Let
and
two OLO algorithms that produces the predictions
and
respectively. Then, predicting with
, we have for any
Moreover, if both algorithm guarantee a constant regret of

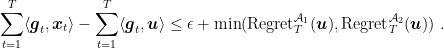
Proof: Set 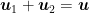
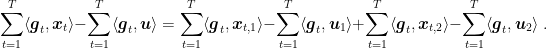
In words, the above theorem allows us to combine online learning algorithm. If the algorithms we combine have constant regret against the null competitor, then we always get the best of the two guarantees.
Example 3 We can combine two parameter-free OCO algorithms, one that gives a bound that depends on the
norm of the competitor and subgradients and another one specialized to the
norm of competitor/subgradients. The above theorem assures us that we will also get the best guarantee between the two, paying only a constant factor in the regret.
Of course, upper bounding the OCO regret with the linear regret, the above theorem also upper bounds the OCO regret.
4. History Bits
The approach of using a coordinate-wise version of the coin-betting algorithm was proposed in the first paper on parameter-free OLO in (M. Streeter and B. McMahan, 2012). Recently, the same approach with a special coin-betting algorithm was also used for optimization of deep neural networks (Orabona, F. and Tommasi, T., 2017). Theorem 2 is from (A. Cutkosky and F. Orabona, 2018). Note that the original theorem is more general because it works even in Banach spaces. The idea of combining two parameter-free OLO algorithms to obtain the best of the two guarantees is from (A. Cutkosky, 2019).
(Orabona, F. and Pal, D., 2016) proposed a different way to transform a coin-betting algorithm into an OCO algorithm that works in 
There are also reductions that allow to transform an unconstrained OCO learner into a constrained one (A. Cutkosky and F. Orabona, 2018). They work constructing a Lipschitz barrier function on the domain and passing to the algorithm the original subgradients plus the subgradients of the barrier function.
5. Exercises
Exercise 1 Prove that
with
and
are exp-concave. Then, using the Online Newton Step Algorithm, give an algorithm and a regret bound for a game with these losses. Finally, show a wealth guarantee of the corresponding coin-betting strategy.

Hi Francesco, very nice post!
Few comments: in Algorithm 2 line 3 I think $\tilde{x}$ should be in B, not S. Also it’s not totally clear what losses we feed to the 2 algorithms, but if I understood well they should be $\ell_t^{\mathcal{A}_{1d}} (z_t) $ for the KT algo and $ \ell_t^{\mathcal{A}_B} (\tilde{x}_t) $ to MD, right?
Also, some typos: in the second line of the proof of Theorem 2, the subscript t is missing from $ \tilde{x} $, while in the second bound of Theorem 4, the min is between R_T(u) (instead of R_T(u_1)) and R_T(u_2).
LikeLike
Fixed all the typos, thanks!
Regarding passing the losses in Algorithm 2: I am not sure I understand your concern, here we pass the entire loss to the direction and magnitude learners, and they will use them as they like. I don’t just pass the value of the losses on their predictions, right?
LikeLike
Yes, I totally agree. I got confused by the notation somehow.
Thanks
LikeLike