This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
In the previous classes, we have shown that Online Mirror Descent (OMD) and Follow-The-Regularized-Leader (FTRL) achieves a regret of 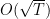
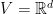



So, in order to get the best possible guarantee, we should know 
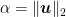
Far from being a technicality, this is an important issue as shown in the next example.
Example 1 Consider that we want to use OSD with online-to-batch conversion to minimize a function that is 1-Lipschitz. The convergence rate will be
using a learning rate of
, specifying
will result in a convergence rate 100 times slower that specifying the optimal choice in hindsight
. Note that this is a real effect not an artifact of the proof. Indeed,it is intuitive that the optimal learning rate should be proportional to the distance between the initial point that algorithm picks and the optimal solution.
If we could tune the learning rate in the optimal way, we would get a regret of

However, this is also impossible, because we proved a lower bound that says that the regret must be 
In the following, we will show that it is possible to reduce any Online Convex Optimization (OCO) game to betting on a non-stochastic coin. This will allow us to use a radically different way to design OCO algorithms that will enjoy the optimal regret and will not require any parameter (e.g. learning rates, regularization weights) to be tuned. We call these kind of algorithms parameter-free.
1. Coin-Betting Game
Imagine the following repeated game:
- Set the initial Wealth to
:
.
- In each round
- You bet
money on side of the coin equal to
; you cannot bet more money than what you currently have.
- The adversary reveals the outcome of the coin
.
- You gain money
, that is
.
- You bet
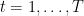
Given that we cannot borrow money, we can codify the bets 

![{\beta_t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cbeta_t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


The aim of the game is to make as much money as possible. As usual, given the adversarial nature of the game, we cannot hope to always win money. Instead, we try to gain as much money as the strategy that bets a fixed amount of money ![{\beta^\star \in [-1, 1]}](https://s0.wp.com/latex.php?latex=%7B%5Cbeta%5E%5Cstar+%5Cin+%5B-1%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Note that

So, given the multiplicative nature of the wealth, it is also useful to take the logarithm of the ratio of the wealth of the algorithm and wealth of the optimal betting fraction. Hence, we want to minimize the following regret
![\displaystyle \begin{aligned} \ln \max_{\beta \in [-1,1]} \epsilon \prod_{t=1}^T (1+\beta c_t) - \ln \text{Wealth}_T &= \ln \max_{\beta \in [-1,1]} \epsilon \prod_{t=1}^T (1+\beta c_t) - \ln \left(\epsilon \prod_{t=1}^T (1+\beta_t c_t)\right) \\ &= \max_{\beta \in [-1,1]} \sum_{t=1}^T \ln(1+\beta c_t) - \sum_{t=1}^T \ln(1+\beta_t c_t)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cln+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Cepsilon+%5Cprod_%7Bt%3D1%7D%5ET+%281%2B%5Cbeta+c_t%29+-+%5Cln+%5Ctext%7BWealth%7D_T+%26%3D+%5Cln+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Cepsilon+%5Cprod_%7Bt%3D1%7D%5ET+%281%2B%5Cbeta+c_t%29+-+%5Cln+%5Cleft%28%5Cepsilon+%5Cprod_%7Bt%3D1%7D%5ET+%281%2B%5Cbeta_t+c_t%29%5Cright%29+%5C%5C+%26%3D+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Cln%281%2B%5Cbeta+c_t%29+-+%5Csum_%7Bt%3D1%7D%5ET+%5Cln%281%2B%5Cbeta_t+c_t%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
In words, this is nothing else than the regret of an OCO game where the losses are 
![{V=[-1,1]}](https://s0.wp.com/latex.php?latex=%7BV%3D%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{c_t \in [-1, 1]}](https://s0.wp.com/latex.php?latex=%7Bc_t+%5Cin+%5B-1%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
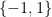
Remark 1 Note that the constraint to bet a fraction between
and
.
We could just use OMD or FTRL, taking special care of the non-Lipschitzness of the functions, but it turns out that there exists a better strategy specifically for this problem. There exists a very simple strategy to solve the coin-betting game above, that is called Krichevsky-Trofimov (KT) bettor. It simply says that on each time step 


For it, we can prove the following theorem.
Theorem 1 (Cesa-Bianchi, N. and Lugosi, G. , 2006, Theorem 9.4) Let
. Then, the KT bettor in Algorithm 1 guarantees
where
is a universal constant.
![\displaystyle \ln \text{Wealth}_T \geq \ln \max_{\beta \in [-1,1]} \prod_{t=1}^T (1+\beta c_t) - \frac{1}{2} \ln T - K,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cln+%5Ctext%7BWealth%7D_T+%5Cgeq+%5Cln+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Cprod_%7Bt%3D1%7D%5ET+%281%2B%5Cbeta+c_t%29+-+%5Cfrac%7B1%7D%7B2%7D+%5Cln+T+-+K%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
Note that if the outcomes of the coin are skewed towards one side, the optimal betting fraction will gain an exponential amount of money, as proved in the next Lemma.
 . Then, we have
. Then, we have![\displaystyle \max_{\beta \in [-1,1]} \exp\left( \sum_{t=1}^T \ln (1-\beta g_t) \right) \geq \exp\left(\sum_{t=1}^T \frac{\left(\sum_{t=1}^T g_t\right)^2}{4T}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Cexp%5Cleft%28+%5Csum_%7Bt%3D1%7D%5ET+%5Cln+%281-%5Cbeta+g_t%29+%5Cright%29+%5Cgeq+%5Cexp%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+%5Cfrac%7B%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+g_t%5Cright%29%5E2%7D%7B4T%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof:
![\displaystyle \begin{aligned} \max_{\beta \in [-1,1]} \exp\left( \sum_{t=1}^T \ln (1-\beta g_t) \right) &\geq \max_{\beta \in [-1/2,1/2]} \exp\left( \sum_{t=1}^T \ln (1-\beta g_t) \right) \geq \max_{\beta \in [-1/2,1/2]} \exp\left( \beta \sum_{t=1}^T g_t - \beta^2 \sum_{t=1}^T g_t^2 \right) \\ &= \max_{\beta \in [-1/2,1/2]} \exp\left( \beta \sum_{t=1}^T g_t - \beta^2 T \right) = \exp\left( \frac{\left(\sum_{t=1}^T g_t\right)^2}{4T} \right)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2C1%5D%7D+%5Cexp%5Cleft%28+%5Csum_%7Bt%3D1%7D%5ET+%5Cln+%281-%5Cbeta+g_t%29+%5Cright%29+%26%5Cgeq+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2F2%2C1%2F2%5D%7D+%5Cexp%5Cleft%28+%5Csum_%7Bt%3D1%7D%5ET+%5Cln+%281-%5Cbeta+g_t%29+%5Cright%29+%5Cgeq+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2F2%2C1%2F2%5D%7D+%5Cexp%5Cleft%28+%5Cbeta+%5Csum_%7Bt%3D1%7D%5ET+g_t+-+%5Cbeta%5E2+%5Csum_%7Bt%3D1%7D%5ET+g_t%5E2+%5Cright%29+%5C%5C+%26%3D+%5Cmax_%7B%5Cbeta+%5Cin+%5B-1%2F2%2C1%2F2%5D%7D+%5Cexp%5Cleft%28+%5Cbeta+%5Csum_%7Bt%3D1%7D%5ET+g_t+-+%5Cbeta%5E2+T+%5Cright%29+%3D+%5Cexp%5Cleft%28+%5Cfrac%7B%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+g_t%5Cright%29%5E2%7D%7B4T%7D+%5Cright%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where we used the elementary inequality 
![{x \in [-1/2, 1/2]}](https://s0.wp.com/latex.php?latex=%7Bx+%5Cin+%5B-1%2F2%2C+1%2F2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Hence, KT guarantees an exponential amount of money, paying only a 
Also, we can extend the guarantee of the KT algorithm to the case in which the coin are “continuous”, that is ![{c_t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bc_t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 3 (Orabona, F. and Pal, D., 2016, Lemma 14) Let
where
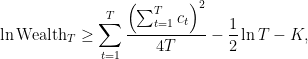
So, we have introduced the coin-betting game, extended it to continuous coins and presented a simple and optimal parameter-free strategy. In the next Section, we show how to use the KT bettor as a parameter-free 1-d OCO algorithm!
2. Parameter-free 1d OCO through Coin-Betting
So, Theorem 1 tells us that we can win almost as much money as a strategy betting the optimal fixed fraction of money at each step. We only pay a logarithmic price in the log wealth, that corresponds to a 
Now, let’s see why this problem is interesting in OCO. It turns out that solving the coin-betting game is equivalent to solving a 1-dimensional unconstrained online linear optimization problem. That is, a coin-betting algorithm is equivalent to design an online learning algorithm that produces a sequences of 

where the 
![{g_t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bg_t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 4 Let
be a proper closed convex function and let
be its Fenchel conjugate. An algorithm that generates
guarantees
where
, if and only if it guarantees


Proof: Let’s prove the left to right implication.

For the other implication, we have

To make sense of the above theorem, assume that we are considering a 1-d problem and

can be done through a betting strategy that bets 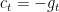
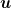
This consideration immediately gives us the conversion between 1-d OLO and coin-betting: the outcome of the coin is the negative of the subgradient of the losses on the current prediction. Indeed, setting
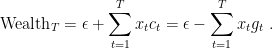
So, a lower bound on the wealth corresponds to a lower bound that can be used in Theorem 3. To obtain a regret guarantee, we only need to calculate the Fenchel conjugate of the reward function, assuming it can be expressed as a function of 
The last step is to reduce 1-d OCO to 1-d OLO. But, this is an easy step that we have done many times. Indeed, we have

where 
So, to summarize, the Fenchel conjugate of the wealth lower bound for the coin-betting game becomes the regret guarantee for the OCO game. In the next section, we specialize all these considerations to the KT algorithm.
3. KT as a 1d Online Convex Optimization Algorithm
Here, we want to use the considerations in the above section to use KT as a parameter-free 1-d OCO algorithm. First, let’s see what such algorithm looks like. KT bets 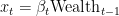
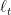

The pseudo-code is in Algorithm 3.

Let’s now see what kind of regret we get. From Theorem 3 and Lemma 2, we have that the KT bettor guarantees the following lower bound on the wealth when used with

So, we found the function 

where
is the Lambert function, i.e.
defined as to satisfy
.
 , for
, for 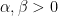 ,
,  . Then
. Then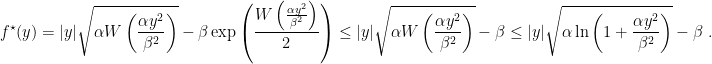
Proof: From the definition of Fenchel dual, we have

where 
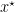
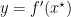
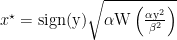
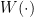
So, the regret guarantee of KT used a 1d OLO algorithm is upper bounded by

where the only assumption was that the first derivatives (or sub-derivatives) of ![{[1,\sqrt{T}]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2C%5Csqrt%7BT%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
To better appreciate this regret, compare this bound to the one of OMD with learning rate
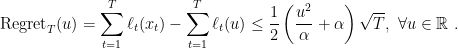
Hence, the coin-betting approach allows to get almost the optimal bound, without having to guess the correct learning rate! The price that we pay for this parameter-freeness is the log factor, that is optimal from our lower bound.
It is interesting also to look at what the algorithm would do on an easy problem, where 
 .
.Next time, we will see that we can also reduce OCO in 
4. History Bits
The keyword “parameter-free” has been introduced in (Chaudhuri, K. and Freund, Y. and Hsu, D. J., 2009) for a similar strategy for the learning with expert problem. It is now used as an umbrella term for all online algorithms that guarantee the optimal regret uniformly over the competitor class. The first algorithm for 1-d parameter-free OCO is from (M. Streeter and B. McMahan, 2012), but the bound was suboptimal. The algorithm was then extended to Hilbert spaces in (Orabona, F., 2013), still with a suboptimal bound. The optimal bound in Hilbert space was obtained in (McMahan, H. B. and Orabona, F., 2014). The idea of using a coin-betting to do parameter-free OCO was introduced in (Orabona, F. and Pal, D., 2016). The Krichevsky-Trofimov algorithm is from (Krichevsky, R. and Trofimov, V., 1981) and its extension to the “continuous coin” is from (Orabona, F. and Pal, D., 2016). The regret-reward duality relationship was proved for the first time in (McMahan, H. B. and Orabona, F., 2014). Lemma 5 is from (Orabona, F. and Pal, D., 2016).
5. Exercises
Exercise 1 While the original proof of the KT regret bound is difficult, it is possible to obtain a looser bound using the be-the-leader method in FTRL. In particular, it is easy to show a regret of
for the log wealth.
6. Appendix
The Lambert function 

The following lemma provides bounds on
Lemma 5 The Lambert function

Proof: The inequalities are satisfied for 

From this equality, using the elementary inequality 
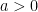

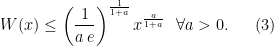

Consider now the function 
![{[0,b]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


![{[0,x^*]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cx%5E%2A%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x^*,b]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5E%2A%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
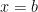


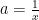

For 
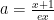
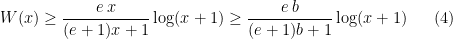
Hence, we set

Numerically, 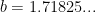

For the upper bound, we use Theorem 2.3 in (Hoorfar, A. and Hassani, M., 2008), that says that

Setting 

EDIT: Fixed a small bug in the KT guarantee, now the guarantee is split in two theorems one for the “standard” coins and the other one for “continuous” coins.
LikeLike
Hi, Francesco. I have the problem with where you get the lower bound of the online sub-gradient descent algorithm is $\Omega(||u||_2\sqrt{T\ln(||u||_2+1)})$ . I guess it is from theorem 5.12 in the book but I’m not sure.
LikeLike
Hi Frank, the theorem is 5.17 in the latest version of my notes on ArXiv or as a blog post https://parameterfree.com/2019/09/25/lower-bounds-for-online-linear-optimization/.
That said, I am rewriting the lower bound in these days because the stated lower bound holds only for a single vector u, while we want one that holds for any u. I’ll probably put a blog post on it when I have some spare time. In the while, you can find the better lower bound in my 2013 NeurIPS paper (https://francesco.orabona.com/papers/13nips_a_long.pdf).
LikeLike
Thank you so much, Francesco. Now I know the bound is from theorem 5.17 in the latest version of your excellent notes, but I still have a problem with it. In theorem 5.17, you have $\epsilon(T)$ in the bound, but you don’t have it in the lower bound of online sub-gradient descent. How do you remove it? I also notice that in the bound stated in theorem 5.17, you have $T$ dependency inside of $\ln$ while you don’t have it on the other lower bound. Is it canceled by the $\epsilon(T)$?
Recently, I’ve been reading your ICML tutorial. I have a related question on tutorial slide part 1 page 33 and page 38. On page 33, you stated a decreasing learning rate $\frac{\alpha}{\sqrt{t}}$ will get a bound $O(\frac{1}{\sqrt}(\frac{||x^*-x_1||^2}{\alpha}+\alphaG^2))$ . How do you get it? I know how to derive a bound for a fixed learning rate but have no idea of a decreasing learning rate. I try to use theorem 2.13 to prove it, but in theorem 2.13, we bound the regret using the diameter instead of the distance between the optimal point and the initial point. On page 38, you also state two lower bounds, Is it the same lower bound as theorem 5.17 in the note? If not, what reference could I find the bound?
Last but not least, thank you for pointing out your NeruIPS 2013 paper. I guess the lower bound is from theorem 2. I am looking forward to seeing your new blog post!
LikeLike
For your first question, I am not sure what you mean by epsilon(T) is not in the lower bound of online sub-gradient descent. Maybe upper bound of OGD? If yes, epsilon(T) is there: for u=0, the regret of OGD with eta = O(1/sqrt{T}) is still O(sqrt(T))=epsilon(T).
Regarding the T in the log, yes it can be cancelled with epsilon(T). However, the correct lower bound has sqrt{T} inside the log, so you can cancel it with epsilon(T)=sqrt{T}. The stated lower bound is correct, but it is for a fixed u. So, it is possible to have log(T ||u||) = constant * log(sqrt{T} ||u||). Hence, this lower bound cannot capture the right dependencies.
For the question on the tutorial, you are right! It should be a fixed learning rate depending on T. However, you can get that rate with FTRL and increasing regularizer, but it is not exactly the same as SGD.
LikeLike