This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
To summarize what we said in the previous note, let’s define online learning as the following general game
- For
- Outputs
- Receive
- Pay
- Outputs
- End for
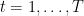
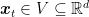
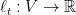

The aim of this game is to minimize the regret with respect to any competitor 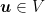

We also said that the way the losses 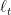
It is also important to remember why minimizing the regret is a good objective: Given that we don’t assume anything on how the adversary generates the loss functions, minimizing the regret is a good metric that takes into account the difficulty of the problem. If an online learning algorithm is able to guarantee a sublinear regret, it means that its performance on average will approach the performance of any fixed strategy. As said, we will see that in many situations if the adversary is “weak”, for example it is a fixed stochastic distribution over the loss functions, being prepared for the worst-case scenario will not preclude us to get the best guarantee anyway.
For a while, we will focus on the case that
Why so much math?? I will now introduce some math concepts. If you have a background in Convex Analysis, this will be easy stuff for you. On the other hand, if you never saw these things before they might look a bit scary. Let me tell you the right way to look at them: these are tools that will make our job easier. Without these tools, it would be basically impossible to design any online learning algorithm. And, no, it is not enough to test random algorithms on some machine learning dataset, because fixed datasets are not adversarial. Without a correct proof, you might never realize that your online algorithm fail on particular sequences of losses, as it happened to Adam (Reddi, S. J. and Kale, S. and Kumar, S., 2018). I promise you that once you understand the key mathematical concepts, online learning is actually easy.
1. Convex Analysis Bits: Convexity

Definition 1
is convex if for any
and any
, we have

In words, this means that the set 
We will make use of extended-real-valued functions, that is function that take value in 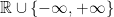



Extended-real-valued functions easily allow us to consider constrained set and are a standard notation in Convex Optimization, see, e.g., (Boyd, S. and Vandenberghe, L., 2004). For example, if I want the predictions of the algorithm 
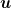
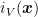
![{i_V:{\mathbb R}^d\rightarrow (-\infty, +\infty]}](https://s0.wp.com/latex.php?latex=%7Bi_V%3A%7B%5Cmathbb+R%7D%5Ed%5Crightarrow+%28-%5Cinfty%2C+%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

In this way, the only way for the algorithm and for the competitor to suffer finite loss is to predict inside the set

Convex functions will be an essential ingredient in online learning.
Definition 2 Let
.
, is convex.
We can see a visualization of this definition in Figure 2. Note that the definition implies that the domain of a convex function is convex. Also, observe that if 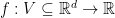
![{f + i_V: {\mathbb R}^d \rightarrow (-\infty, +\infty]}](https://s0.wp.com/latex.php?latex=%7Bf+%2B+i_V%3A+%7B%5Cmathbb+R%7D%5Ed+%5Crightarrow+%28-%5Cinfty%2C+%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Note that
The definition above gives rise to the following characterization for convex functions that do not assume the value 
Theorem 3 (Rockafellar, R. T., 1970, Theorem 4.1) Let
and
is a convex set. Then
, we have

Example 1 The simplest example of convex functions are the affine function:
.
Example 2 Norms are always convex, the proof is left as exercise.
How to recognize a convex function? In the most general case, you have to rely on the definition. However, most of the time we will recognize them as composed by operations that preserve the convexity. For example:
convex, then the linear combination with non-negative weights is also convex.
- The composition with an affine transformation preserves the convexity.
- Pointwise supremum of convex functions is convex.
The proofs are left as exercises.
A very important property of differentiable convex functions is that we can construct linear lower bound to the function.
Theorem 4 (Rockafellar, R. T., 1970, Theorem 25.1 and Corollary 25.1.1) Suppose
. If
then

We will also use the optimality condition for convex functions:
Theorem 5 Let
, and
iff
.
In words, at the constrained minimum, the gradient makes an angle of 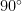
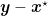
Another critical property of convex functions is Jensen’s inequality.
Theorem 6 Let
be a measurable convex function and
exists and
with probability 1. Then
![\displaystyle E[f({\boldsymbol x})] \geq f(E[{\boldsymbol x}])~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Bf%28%7B%5Cboldsymbol+x%7D%29%5D+%5Cgeq+f%28E%5B%7B%5Cboldsymbol+x%7D%5D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s see our first OCO algorithm in the case that the functions are also differentable.
2. Online Gradient Descent
Last time we saw a simple strategy to obtain a logarithmic regret in the guessing game. The strategy was to use the best over the past, that is the Follow-the-Leader strategy. In formulas,
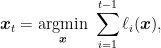
and in the first round we can play any admissible point. One might wonder if this strategy always works, but the answer is negative!
Example 3 (Failure of FTL) Let
and consider the sequence of losses
, where
Then, a part from the first round where the prediction of FTL is arbitrary in
, the predictions of FTL will be
for
even and
for
while the cumulative loss of the fixed solution
is 0. Thus, the regret of FTL is
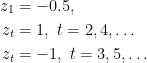
Hence, we will show an alternative strategy that guarantees sublinear regret for convex Lipschitz functions. Later, we will also prove that the dependency on

First, we show the following two Lemmas. The first lemma proves that Euclidean projections always decrease the distance with points inside the set.
Proposition 7 Let
and
, where
. Then,
.
Proof: From the optimality condition of Theorem 5, we obtain

Therefore,
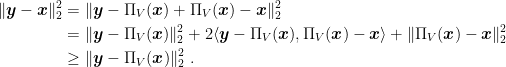

The next lemma upper bounds the regret in one iteration of the algorithm.
Lemma 8 Let
a closed non-empty convex set and
a convex function differentiable in a open set that contains
. Then,
, the following inequality holds
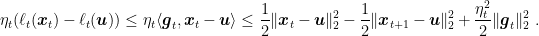
Proof: From Proposition 7 and Theorem 4, we have that

Reordering, we have the stated bound.
We can prove the following regret guarantee in the online setting.
Theorem 9 Let
a closed non-empty convex set with diameter
, i.e.
. Let
an arbitrary sequence of convex functions
. Pick any
assume
. Then,
Moreover, if
is constant, i.e.
, we have
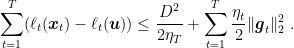
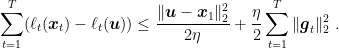
Proof: Dividing the inequality in Lemma 8 by 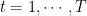
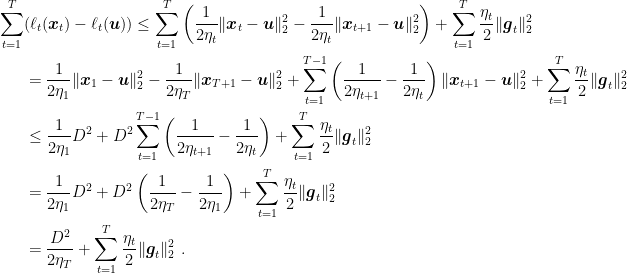
The proof of the second statement is left as an exercise.
We can immediately observe few things.
- If we want to use time-varying learning rates you need a bounded domain
- Another important observation is that the regret bound helps us choosing the learning rates
As we said, the presence of parameters like the learning rates make no sense in online learning. So, we have to decide a strategy to set them. A simple choice is to find the constant learning rate that minimizes the bounds for a fixed number of iterations. We have to consider the expression

and minimize with respect to 
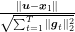
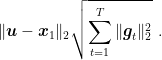
However, we have a problem: in order to use this stepsize, we should know all the future subgradients and the distance between the optimal solution and the initial point! This is clearly impossible: Remember that the adversary can choose the sequence of functions. Hence, it can observe your choice of learning rates and decide the sequence so that your learning rate is now the wrong one!
Indeed, it turns out that this kind of rate is completely impossible because it is ruled out by a lower bound. Yet, we will see that it is indeed possible to achieve very similar rates using adaptive and parameter-free algorithms.
In the following, we will see many adaptive strategies. For the moment, we can observe that we might be happy to minimize a looser upper bound. In particular, assume that the norm of the gradients is bounded by 

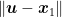
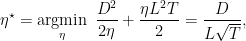
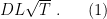
So, indeed the regret is sublinear in time. Next time, we will see how to remove the differentiability assumption through the use of subgradients.
3. History Bits
The Projected Online Subgradient Descent with time-varying learning rate and the concept itself of Online Convex Optimization was introduced by (M. Zinkevich, 2003). Note that, if we consider the optimization literature, the optimization people never restricted themselves to the bounded case.
4. Exercises
Exercise 1 Prove the second part of Theorem 9.
Exercise 2 Prove that
.
Exercise 3 Using the inequality in the previous exercise, prove that a learning rate
gives rise to a regret only a constant multiplicative factor worse than the one in (1).

Hi,
Am I wrong or in the first line of the Proof of Theorem 9, the second inequality of Lemma 8 has to be divided by \eta_t instead of 2 \eta_t ?
Besides this minor detail, I was wondering if the choice of the adaptive parameter in Exercise 3 is taken by “converting to online” the ideal batch choice \eta= $\frac{D}{LT}$.
Thanks
LikeLike
Typo fixed, thanks!
The choice of the time-varying learning rate in Exercise 3 does indeed corresponds to make the choice eta proportional 1/sqrt{T} to an “online version” of eta_t proportional to 1/sqrt{t}. However, the reason why it works seems to be purely mathematical. In other words, it is not true that any fixed choice of parameters can be made “online” in a natural way: Each time you’ll have to prove that it works by proving the regret guarantee.
LikeLike
Hi,
I’m in trouble with the beginning of the Proof of Proposition 7; how can you obtain the vectors of the inner product from the Optimality condition of Theorem 5?
Pheraps it is just a gap of mine in algebra. Anyway, I tried to find a way to “connect” the things but I wasn’t able to.
Could you please explain me how to?
Thanks
LikeLike
Hi Jacopo, there are a couple of skipped steps: we want to apply the optimality condition of the objective function of the projection. Now, instead of doing it directly, we first observe that the argmin of the projection does not change if instead of considering ||x-y||, we consider 1/2 ||x-y||^2. Taking the gradient of this function and using the optimality condition should give you the inner product. Can you see it now?
LikeLike
Hi
I am in trouble to understand Lemma 2.12. Why Lt(Xt) – Lt(u) <= ? From Theorem 2.7, we can get Lt(Xt) >= Lt(u) + . Could you pls give me more explain?
Thanks
LikeLike
In theorem 2.7 set x=x_t and y=u, to obtain f(u) >= f(x_t) + inner product. Now, just reorder the terms and bring the negative sign inside the inner product.
LikeLike
In proof of theorem 9: do we know any relation between $$n_t$$’s ?
like that n1>n2>… and so on? (the learning rate)
LikeLike
As stated in the assumptions of the theorem, for the first bound we assume the learning rate to be non-increasing. So, it can stay constant or decrease between one iteration and the following one.
LikeLiked by 1 person
Hello
In Theorem 9, could you please explain the role of the assumption $\eta_{t+1} \le \eta_t$? It seems like this assumption is not directly utilized in the proof.
Thanks a lot.
LikeLike
In the second inequality, you need 1/eta_{t+1}-1/eta_t to be positive to be able to upper bound ||x_{t+1}-u|| with D
LikeLike
Thank you for your guidance. I realized that I overlooked the point.
I find that if we assume $\eta_{t+1} > \eta$, we can still obtain a similar regret bound. In this case, when the term $1/\eta_{t+1}-1/\eta_t$ is negative, we obtain the bound $1/(2\eta_1) ||x_1 – u||2^2 + \sum_{t=1}^{T} \eta_t/2 ||g_t||_2^2$.
This assumption, $\eta_{t+1} > \eta_t$, seems to suggest that even with an increasing learning rate, the algorithm still converges. Is my understanding correct, or could this assumption have other effects on the algorithm?
LikeLiked by 1 person
You are correct that even increasing learning rate gives you something. But to get sqrt(T) regret you still need the term sum_{t=1}^{T} eta_t/2 ||g_t||_2^2 to be of the order of sqrt{T}, so eta_t cannot grow too fast. There are papers on the learning with expert setting where they use a mildly increasing learning rate to take advantage of an additional negative term in the regret.
LikeLike
I will take a look at relevant papers. Thanks very much!
LikeLiked by 1 person
Hello! Thanks for the post!
Regarding OGD, I get that mathematically it’ll enjoy optimal regret under some conditions, which is good! But how do we understanding it intuitively? That is, at time t, we only use the current g_t to do the descent, whereas g_t+1 is adversarially chosen. How can we sort of put all the faith to the current g_t?
LikeLike