This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
Last time, we introduced Projected Online Gradient Descent:

And we proved the following regret guarantee:
Theorem 1 Let
a closed non-empty convex set with diameter
, i.e.
. Let
an arbitrary sequence of convex functions
differentiable in open sets containing
for
. Pick any
assume
. Then,
, the following regret bound holds
Moreover, if
is constant, i.e.
, we have
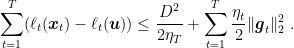
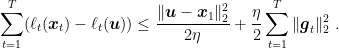
However, the differentiability assumption for the 



1. Convex Analysis Bits: Subgradients
First, we need a technical definition.
Definition 2 If a function
is nowhere
and finite somewhere, then
In these class, we are mainly interested in convex proper functions, that basically better conform to our intuition of what a convex function looks like.
Let’s first define formally what is a subgradient.
Definition 3 For a proper function
, we define a subgradient of
as a vector
that satisfies

Basically, a subgradient of 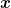


Observe that if 

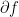
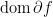

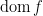
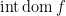

Also, we can also calculate the subgradient of sum of functions.
Theorem 4 (Rockafellar, R. T., 1970, Theorem 23.8,Bauschke, H. H. and Combettes, P. L., 2011, Corollary 16.39) Let
be proper convex functions on
, and
. Then
. If
, then actually
.
Example 1 Let
, then the subdifferential set
![\displaystyle \partial f(x) = \begin{cases} \{1\}, & x>0,\\ [-1,1], & x=0\\ \{-1\}, & x<0~. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpartial+f%28x%29+%3D+%5Cbegin%7Bcases%7D+%5C%7B1%5C%7D%2C+%26+x%3E0%2C%5C%5C+%5B-1%2C1%5D%2C+%26+x%3D0%5C%5C+%5C%7B-1%5C%7D%2C+%26+x%3C0%7E.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Example 2 Let’s calculate the subgradient of the indicator function for a non-empty convex set
. By definition,
if
This condition implies that
and
(because for
the inequality is always verified). The set of all
(Hint: take
). For example, for
,
for all
.

Another useful theorem is to calculate the subdifferential of the pointwise maximum of convex functions.
Theorem 5 (Bauschke, H. H. and Combettes, P. L., 2011, Theorem 18.5) Let
be a finite set of convex functions from
and suppose
and
continuous at
and let
the set of the active functions. Then

Example 3 (Subgradients of the Hinge loss) Consider the loss
for
. The subdifferential set if
![\displaystyle \partial \ell({\boldsymbol x}) = \begin{cases} \{\boldsymbol{0}\}, & 1-\langle {\boldsymbol z},{\boldsymbol x}\rangle <0\\ \{-\alpha {\boldsymbol z}| \alpha \in [0,1]\}, & 1-\langle {\boldsymbol z},{\boldsymbol x}\rangle =0\\ \{-{\boldsymbol z}\}, & \text{otherwise} \end{cases}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpartial+%5Cell%28%7B%5Cboldsymbol+x%7D%29+%3D+%5Cbegin%7Bcases%7D+%5C%7B%5Cboldsymbol%7B0%7D%5C%7D%2C+%26+1-%5Clangle+%7B%5Cboldsymbol+z%7D%2C%7B%5Cboldsymbol+x%7D%5Crangle+%3C0%5C%5C+%5C%7B-%5Calpha+%7B%5Cboldsymbol+z%7D%7C+%5Calpha+%5Cin+%5B0%2C1%5D%5C%7D%2C+%26+1-%5Clangle+%7B%5Cboldsymbol+z%7D%2C%7B%5Cboldsymbol+x%7D%5Crangle+%3D0%5C%5C+%5C%7B-%7B%5Cboldsymbol+z%7D%5C%7D%2C+%26+%5Ctext%7Botherwise%7D+%5Cend%7Bcases%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Definition 6 Let
-Lipschitz over a set
if
.
We also have this handy result that upper bounds the norm of subgradients of convex Lipschitz functions.
Theorem 7 Let
and
we have
.
Proof: Assume 



that implies that
For the other implication, the definition of subgradient and Cauchy-Schwartz inequalities gives us

for any 

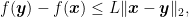
that completes the proof.

2. Analysis with Subgradients
As I promised you, with the proper mathematical tools, the analyzing online algorithms becomes easy. Indeed, switching from gradient to subgradient comes for free! In fact, our analysis of OGD with differentiable losses holds as is using subgradients instead of gradients. The reason is that the only property of the gradients that we used in our proof was that

where 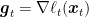
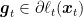

Also, the regret bounds we proved holds as well, just changing differentiability with subdifferentiability and gradients with subgradients.
3. From Convex Losses to Linear Losses
Let’s take a deeper look at this step

And summing over time, we have

Now, define the linear (and convex) losses 
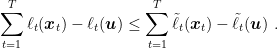
This is more powerful that what it seems: We upper bounded the regret with respect to the convex losses
So, we will often consider just the problem of minimizing the linear regret

This problem is called Online Linear Optimization (OLO).
Example 4 Consider the guessing game of the first class, we can solve easily it with Online Gradient Descent. Indeed, we just need to calculate the gradients, prove that they are bounded, and find a way to calculate the projection of a real number in
So,
, that is bounded for
. The projection on
. With the optimal learning rate, the resulting regret would be
. This is worse than the one we found in the first class, showing that the reduction not always gives the best possible regret.
Example 5 Consider again the guessing game of the first class, but now change the loss function to the absolute loss of the difference:
. Now we will need to use Online Subgradient Descent, because the functions are non-differentiable. We can easily see that
Again, running Online Subgradient Descent with the optimal learning rate on this problem will give us immediately a regret of
![\displaystyle \partial \ell_t(x) =\begin{cases} \{1\}, & x>y_t\\ [-1,1], & x=y_t\\ \{-1\}, & x<y_t~. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpartial+%5Cell_t%28x%29+%3D%5Cbegin%7Bcases%7D+%5C%7B1%5C%7D%2C+%26+x%3Ey_t%5C%5C+%5B-1%2C1%5D%2C+%26+x%3Dy_t%5C%5C+%5C%7B-1%5C%7D%2C+%26+x%3Cy_t%7E.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
4. Online-to-Batch Conversion
It is a good moment to take a break from online learning theory and see some application of online learning to other domains. For example, we may wonder what is the connection between online learning and stochastic optimization. Given that Projected Online (Sub)Gradient Descent looks basically the same as Projected Stochastic (Sub)Gradient Descent, they must have something in common. Indeed, we can show that, for example, we can reduce stochastic optimization of convex functions to OCO. Let’s see how.
Theorem 8 Let
where the expectation is w.r.t.
drawn from
over some vector space
and
is convex in the first argument. Draw
samples
i.i.d. from
, where
are deterministic. Run any OCO algorithm over the losses
. Then, we have
where the expectation is with respect to
.
![\displaystyle \mathop{\mathbb E}\left[F\left(\frac{1}{\sum_{t=1}^T \alpha_t}\sum_{t=1}^T \alpha_t {\boldsymbol x}_t\right)\right] \leq F({\boldsymbol u}) + \frac{\mathop{\mathbb E}[\text{Regret}_T({\boldsymbol u})]}{\sum_{t=1}^T \alpha_t}, \ \forall {\boldsymbol u} \in {\mathbb R}^d,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5BF%5Cleft%28%5Cfrac%7B1%7D%7B%5Csum_%7Bt%3D1%7D%5ET+%5Calpha_t%7D%5Csum_%7Bt%3D1%7D%5ET+%5Calpha_t+%7B%5Cboldsymbol+x%7D_t%5Cright%29%5Cright%5D+%5Cleq+F%28%7B%5Cboldsymbol+u%7D%29+%2B+%5Cfrac%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Ctext%7BRegret%7D_T%28%7B%5Cboldsymbol+u%7D%29%5D%7D%7B%5Csum_%7Bt%3D1%7D%5ET+%5Calpha_t%7D%2C+%5C+%5Cforall+%7B%5Cboldsymbol+u%7D+%5Cin+%7B%5Cmathbb+R%7D%5Ed%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
We will prove it next time, let’s see now an application for it: Let’s now see how to use the above theorem to transform Online Subgradient Descent in Stochastic Subgradient Descent to minimize the training error of a classifier.
Example 6 Consider a problem of binary classification, with inputs
and outputs
. The loss function is the hinge loss:
. Suppose that you want to minimize the training error over a training set of
samples,
. Also, assume the maximum L2 norm of the samples is
. That is, we want to minimize
Run the reduction described in Theorem 8 for
sampling a training point uniformly at random from
to
and
. We have that
In words, we used an OCO algorithm to stochastically optimize a function, transforming the regret guarantee into a convergence rate guarantee.

![\displaystyle \mathop{\mathbb E}\left[F\left(\frac{1}{T}\sum_{t=1}^T {\boldsymbol x}_t\right)\right] - F({\boldsymbol x}^\star) \leq R\frac{\|{\boldsymbol x}^\star\|^2 + 1}{2\sqrt{T}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5BF%5Cleft%28%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+x%7D_t%5Cright%29%5Cright%5D+-+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cleq+R%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar%5C%7C%5E2+%2B+1%7D%7B2%5Csqrt%7BT%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Next time we will prove the Online-to-Batch theorem and show many more examples on how to use it.
5. History Bits
The specific shape of Theorem 8 is new, but I wouldn’t be surprised if it appeared somewhere in the literature. In particular, the uniform averaging is from (N. Cesa-Bianchi and A. Conconi and Gentile, C. , 2004), but was proposed for the absolute loss in (Blum, A. and Kalai, A. and Langford, J., 1999). The non-uniform averaging, that we will use next time, is from (Zhang, T., 2004), even if there it is not proposed explicitly as a online-to-batch conversion.
6. Exercises
Exercise 1 Calculate the subdifferential set of the
-insensitive loss:
. It is a loss used in regression problems where we don’t want to penalize predictions
within
of the correct value
.
Exercise 2 Consider Projected Online Subgradient Descent for the example in the previous lecture about the failure of Follow-the-Leader: Can we use it on that problem? Would it guarantee sublinear regret? How the behaviour of the algorithm would differ from FTL?
Exercise 3 Implement the algorithm in 6 in any language you like: implementing an algorithm is the perfect way to see if you understood all the details of the algorithm.

Hi, in definition 6 for the Lipshitz functions I think there is a missing $L$ in the equation: {|f({\boldsymbol x})-f({\boldsymbol y})|\leq \|{\boldsymbol x}-{\boldsymbol y}\|
Also, in Example 6 it’s written “training set of N samples {\{({\boldsymbol x}_i,y_i)\}_{i=1}^N}”, but we said before that our inputs are {\boldsymbol z}_i \in R^d
I think I’m missing something in the second implication of Theorem 7, i.e. assuming {\|{\boldsymbol g}\|_2\leq L} then the function is $L$-Lipshitz. If we use the definition of subgradient we get
\displaystyle f({\boldsymbol x})-f({\boldsymbol y}) \leq \langle {\boldsymbol g}, \|{\boldsymbol x}-{\boldsymbol y}
why does it hold for the absolute value as well?
Thanks,
Nicolò
LikeLike
Thanks for finding the typos! I fixed them now.
For the proof of Theorem 7, I was indeed a bit sloppy. I changed the proof: you just do the same reasoning twice, swapping the role of x and y. Does it work now?
LikeLike
Right, thank you!
LikeLiked by 1 person
In example 6, shouldn’t the sqrt(T) be in the numerator and not the denominator?
Thanks!
LikeLike
I think it is correct: the regret is sqrt{T} and the online-to-batch conversion divides the regret by T, right?
LikeLike