In the latest posts, we saw that it is possible to solve convex/concave saddle-point optimization problems using two online convex optimization algorithms playing against each other. We obtained a rate of convergence for the duality gap of 
1. Faster Rates Through Optimism
Assume that 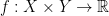



where 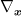


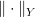



Remark 1. At this point, one might be tempted to consider the maximum between the three quantities “to simplify the math”, but the units are different!
Let’s use again two online algorithms to solve the saddle-point problem 
For example, use two Optimistic FTRL algorithms with fixed strongly convex regularizers and hint at time 

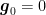
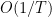

From the regret of Optimistic FTRL, for the

From the Fenchel-Young inequality, we have 

Note that there are multiple choices of the coefficient in the Fenchel-Young inequality, but without additional information all choices are equally good.
Now, using the smoothness assumption, for 

We can proceed in the exact same way for the
Summing the regret of the two algorithms, we have
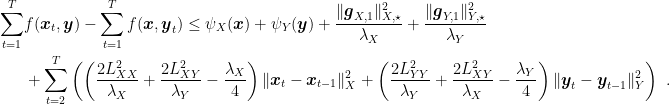
Choosing 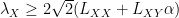

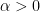

and similarly for the other term. One might wonder why we need to introduce 
Assuming that the regularizers are bounded over 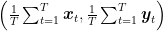
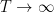
Overall, we can state the following theorem.
Theorem 1. With the notation in Algorithm 1, let
convex in the first argument and concave in the second, satisfying assumptions (1)–(4). For a fixed
be
-strongly convex w.r.t.
and
be
-strongly convex w.r.t.
and
non-empty. Then, we have
for any
and
.
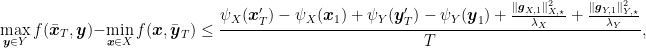
Looking back at the proof of the algorithm, we have a faster convergence because regret of one player depends on the “stability” of the other player, measured by the terms 

In fact, setting for example 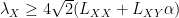


and
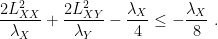
Hence, using the fact that the existence of a saddle-point 


Plugging this guarantee back in the regret of each algorithm, we have that their regret is bounded and independent of 

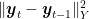
Version with Optimistic OMD The exact same reasoning holds for Optimistic OMD, because the key terms of its regret bound are exactly the same of the one of Optimistic FTRL. To better show this fact, we also instantiate the Optimistic OMD with stepsizes equal to 

Theorem 2. With the notation in Algorithm 1, let
-strongly convex w.r.t.
for any


Example 1. Consider the bilinear saddle-point problem
In this case, we have that
,
,
,
, and
where
is the operator norm of the matrix
. The specific shape of the operator norm depends on the norms we use on
and
as in the two-person zero-sum games, then the operator norm of a matrix

2. Prescient Online Mirror Descent and Be-The-Regularized-Leader
The above result is interesting from a game-theoretic point of view, because it shows that two player can converge to an equilibrium without any “communication”, if instead we only care about converging to the saddle-point, we can easily do better. In fact, we can use the fact that it is fine if one of the two players “cheats” by looking at the loss at the beginning of each round, making its regret non-positive.
For example, we saw the use of Best Response. However, Best Response only guarantees non-positive regret, while for the optimistic proof above we need some specific negative terms. This is not only an artifact of the proof: Best Response is very unstable and it would ruin the “stabilization loop” we have discussed above. It turns out there is an alternative: Prescient Online Mirror Descent, that predicts in each round with 

Theorem 3. Let
differentiable in
, closed, and strictly convex. Let
a non-empty closed convex set. Assume
,
subdifferentiable in
, and
, for
. Then,
, the following inequality holds
Moreover, if
is constant, i.e.,
, we have
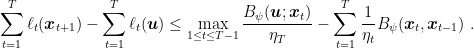

Proof: From the first-order optimality condition on the update, we have that there exists 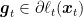

Hence, we have

where in the last equality we used the 3-points equality for Bregman divergences. Dividing by

where we denoted by 
The second statement is left as exercise.

The regret of Prescient Online Mirror Descent contains the negative terms we needed from the optimistic algorithms.
Analogously, we can obtain a version of FTRL that uses the knowledge of the current loss: Be-The-Regularized-Leader (BTRL), that predicts in each time step with 


Theorem 4. Let
be convex, closed, and non-empty. Assume for
is proper, closed, and
-strongly convex w.r.t.
. Then, for all
we have

Remark 2. In the Be-The-Leader algorithm, if all the
, then the theorem states that the regret is non-positive.
Notably, the non-negative gradients terms are missing in the bound of BTRL, but we still have the negative ones associated to the change in 
Using, for example, BTRL for the
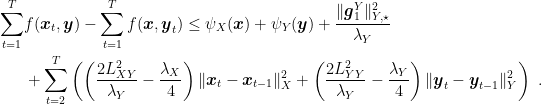
3. Code and Experiments
This time I will also show some empirical experiments. In fact, I decided to write a small online learning library in Python, to quickly test old and new algorithms. It is called PyOL (Python Online Learning) and you can find it on GitHub and on PyPI, and install it with pip. I designed it in a modular way: you can use FTRL or OMD and choose the projection you want, the learning rates, the hints, etc. I implemented some online learning algorithms, projections, learning rate, reductions, but I plan to add more. At the moment there is no documentation, but I plan to add it and probably I’ll also blog about it.
The Python notebook below will show the effect of optimism in Exponentiated Gradient when used to solve a 2×2 bilinear saddle-point problem with simplex contraints. You can see as the optimistic algorithm converges faster, with both and averaged last solutions. Moreover, even if we did not prove it, the last iterate of the optimistic algorithm converges to the saddle point, while the one of the non-optimistic algorithm goes farther and farther away from the saddle-point.
That’s all for this time!
We won’t see other saddle-point results for a while, time to cover new topics.
4. History Bits
Daskalakis et al. (2011) proposed the first no-regret algorithm that achieved a rate of 
The use of Prescient Online Mirror Descent in saddle-point optimization is from Wang et al. (2021), but renaming 
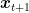
There is also a tight connection between optimistic updates using the previous gradients and classic approaches to solve saddle-point optimization. In fact, Gidel et al. (2019) showed that using two optimistic gradient descent algorithms to solve a saddle-point problem can be seen as a variant of the Extra-gradient updates (Korpelevich, G. M., 1976), while Mokhtari et al. (2020) show that they can be interpreted as an approximated proximal point algorithm.
Regarding the convergence of the iterations of optimistic algorithms, Daskalakis et al. (2018) proved the convergence of the last iterate to a neighboorhood of the saddle-point in the unconstrained case when using two optimistic online gradient descent algorithms with fixed and small enough stepsizes. Liang and Stokes (2019) improved their result showing that if in addition the matrix 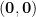
Acknowledgements
Thanks to Haipeng Luo and Aryan Mokhtari for comments and references.

thanks for this series, they are super useful !
LikeLiked by 1 person
Thank you Fabian! Your blog is also fantastic!
LikeLike