This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
In this lecture, we will explore the possibility to obtain logarithmic regret for non-strongly convex functions. Also, we explore a bit more the strategy of moving pieces of the losses inside the regularizer, as we did for the composite and strongly convex losses.
1. Online Newton Step
Last time, we saw that the notion of strong convexity allows us to build quadratic surrogate loss functions, on which Follow-The-Regularized-Leader (FTRL) has smaller regret. Can we find a more general notion of strong convexity that allows to get a small regret for a larger class of functions? We can start from strong convexity and try to generalize it. So, instead of asking that the function is strongly convex w.r.t. a norm, we might be happy requiring strong convexity holds in a particular point w.r.t. a norm that depends on the points itself.
In particular, we can require that for each loss 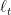
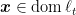
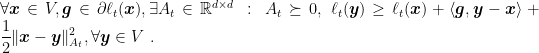
where 

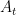
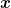
The rationale of this new definition is that it still allows us to build surrogate loss functions, but without requiring to have strong convexity over the entire space. Hence, we can think to use FTRL on the surrogate losses
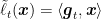
and the proximal regularizers 
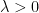

Remark 1 Note that
is a norm because
is Positive Definite (PD) and
is
-strongly convex w.r.t.
defined as
(because the Hessian is
). Also, the dual norm of
.
From the above remark, we have that the regularizer 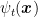
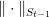

So, reordering the terms we have
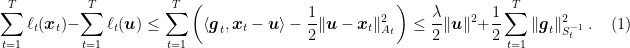
Note how the proof and the algorithm mirror what we did in FTRL with strongly convex losses in the last lecture.
Remark 2 It is possible to generalize our Lemma of FTRL for proximal regularizers to hold in this generalized notion of strong convexity. This would allow to get exactly the same bound running FTRL over the original losses with regularizer
.
Let’s now see a practical instantiation of this idea. Consider the case that the sequence of loss functions we receive satisfy
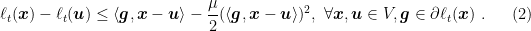
In words, we assume to have a class of functions that can be lower bounded by a quadratic that depends on the current subgradient. In particular, these functions posses some curvature only in the direction of (any of) the subgradients. Denoting by 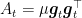
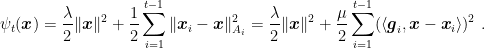
Hence, the update rule would be
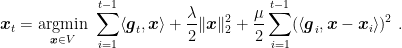
We obtain the following algorithm, called Online Newton Step (ONS).

Denoting by 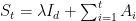

To bound the last term, we will use the following Lemma.
Lemma 1 (Cesa-Bianchi, N. and Lugosi, G. , 2006, Lemma 11.11 and Theorem 11.7) Let
a sequence of vectors in
and
. Then, the following holds
where
are the eigenvalues of
.

Putting all together and assuming 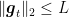
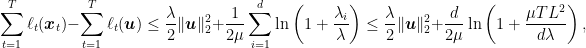
where in the second inequality we used the inequality of arithmetic and geometric means, 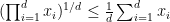
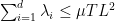
Hence, if the losses satisfy (2), we can guarantee a logarithmic regret. However, differently from the strongly convex case, here the complexity of the update is at least quadratic in the number of dimensions. Moreover, the regret also depends linearly on the number of dimensions.
Remark 3 Despite the name, the ONS algorithm should not be confused with the Netwon algorithm. They are similar in spirit because they both construct quadratic approximation to the function, but the Netwon algorithm uses the exact Hessian while the ONS uses an approximation that works only for a restricted class of functions. In this view, the ONS algorithm is more similar to Quasi-Newton methods.
Let’s now see an example of functions that satisfy (2).
Example 1 (Exp-Concave Losses) Defining
convex, we say that a function
is
-exp-concave if
is concave.
Choose
such that
for all
and
. Note that we need a bounded domain for
to exist. Then, this class of functions satisfy the property (2). In fact, given that
is
-exp-concave. Hence, from the definition we have
that is
that implies
where we used the elementary inequality
, for
.
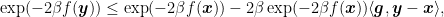


Example 2 Let
. The logistic loss of a linear predictor
, where
is
-exp-concave.
2. Online Regression: Vovk-Azoury-Warmuth Forecaster
Let’s now consider the specific case that 
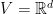
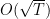
It turns out we can still get a logarithmic regret, if we make an additional assumption! We will assume to have access to 



As we did for composite losses, we look closely to the loss functions, to see if there are terms that we might move inside the regularizer. The motivation would be the same as in the composite losses case: the bound will depends only on the subgradients of the part of the losses that are outside of the regularizer.
So, observe that

From the above, we see that we could think to move the terms 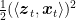
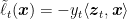
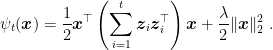
Note that the regularizer at time 

Using such procedure, the prediction can be written in a closed form:

Hence, using the regret we proved for FTRL with strongly convex regularizers and 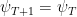

Noting that 

Remark 4 Note that, differently from the ONS algorithm, the regularizers here are not proximal. Yet, we get
in the bound because the current sample
that cannot be controlled without additional assumptions on
So, using again Lemma 1 and assuming 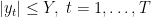

where 
If we assume that 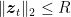

Putting all together, we have the following theorem.
Theorem 2 Assume
for
. Then, using the prediction strategy in Algorithm 2, we have

Remark 5 It is possible to show that the regret of the Vovk-Azoury-Warmuth forecaster is optimal up to multiplicative factors (Cesa-Bianchi, N. and Lugosi, G. , 2006, Theorem 11.9).
3. History Bits
The Online Newton Step algorithm was introduced in (Hazan, E. and Kalai, A. and Kale, S. and Agarwal, A., 2006) and it is described to the particular case that the loss functions are exp-concave. Here, I described a slight generalization for any sequence of functions that satisfy (2), that in my view it better shows the parallel between FTRL over strongly convex functions and ONS. Note that (Hazan, E. and Kalai, A. and Kale, S. and Agarwal, A., 2006) also describes a variant of ONS based on Online Mirror Descent, but I find its analysis less interesting from a didactical point of view. The proof presented here through the properties of proximal regularizers might be new, I am not sure.
The Vovk-Azoury-Warmuth algorithm was introduced independently by (K. S. Azoury and M. K. Warmuth, 2001) and (Vovk, V., 2001). The proof presented here is from (F. Orabona and K. Crammer and N. Cesa-Bianchi, 2015).
4. Exercises
Exercise 1 Prove the statement in Example 2.
Exercise 2 Prove that the losses
, where
,
, and
, are exp-concave and find the exp-concavity constant.

Hi,
There are some typos in the proof after remark 4.
1) y^2_t is missing
2) sum^T_{t=1} \lambda_i should be changed to sum^d_{i=1} \lambda_i
LikeLiked by 1 person
Fixed, thanks!
LikeLike
Nice post! I think I found some typos:
– In algo 1, after the for loop it’s written we receive $z_t$, which is not mentioned anywhere in the remainder.
– In the Vovk-Azoury-Warmuth section, after you say: “Using such procedure, the prediction can be written in a closed form:” then the $z_t$ in the sum after the argmin should be $z_i$
– Also, in the last section when there is the regret bound for $\tilde{\ell}$ at some point there is a matrix A_T, which was not defined but I assume it’s $ \sum_{t=1}^T z_t z_t^\top, right? But then later, “Noting that {{\boldsymbol x}_1=\boldsymbol{0}} and reordering the terms we have” in the rhs of the first equation shouldn’t we have for the last term $ 1 / 2 u^\top A_T u $?
I also have some questions:
– Regarding the sum of the eigenvalues, how do get the bound TL^2? I get a slightly different result. My reasoning:
$$ \sum_i^d \lambda_i \leq d \lambda_{max} = d \| A_T \|_2 $$
where $ \| A \|_2 $ is the spectral norm of A_T, which in this case corresponds to the largest eigenvalue of A_T, since it is a symmetric matrix. Then,
\begin{align*}
d \| A_T \|_2 &= d \| \sum_{t=1}^T g_t g_t^\top \|_2 \\
& \leq d \sum_{t=1}^T \| g_t g_t^\top \|_2 \\
& \leq d \sum_{t=1}^T \lambda_{max}(g_t g_t^\top) \\
& = d \sum_{t=1}^T \| g_t \|_2^2 \\
& \leq d \sum_{t=1}^T L^2 \\
& = d T L^2
\end{align*}
Maybe I went wrong in some step?
– At the end of the section on ONS, you say “the complexity of the update is at least quadratic in the number of dimensions”. Why is that? I know that from the version of ONS given by Hazan you have to explicitly compute the inverse of the matrix A_t at each time-step, which normally would take O(d^3), but since we have a rank-one update in every step we can reduce it to O(d^2). However, in your version of the algorithm we are not computing any inverse, so where does the quadratic cost come from?
– In the Vovk-Azoury-Warmuth, it is not really clear to me why the assumption on having z_t revealed before the prediction helps us, what would change if we don’t have it?
Thank you,
Nicolò
LikeLiked by 1 person
Fixed all the typos, thanks!
For the TL^2 bound, the sum of the eigenvalues is the trace of the matrix that is equal to the sum of the traces of rank-1 matrices with eigenvalue bounded by L^2.
The quadratic cost comes from the matrix-vector multiplication. Note that the FTRL version of ONS is in the paper of Hazan et al. too, this is not “my” version.
Also, I expanded Remark 4 to explain the issue of the z_t in the regularizer.
Let me know if there are more doubts!
LikeLike
Clear now, thanks!
LikeLiked by 1 person
Great lecture notes!
Doesn’t equation (2) means the loss can be *lower* bounded by a quadratic approximation?
LikeLike
Yes! Typo fixed, thanks.
LikeLike
Thanks for the nice blog and great lectures!
A quick question about VAW vs. ridge regression, i.e., the *main* reason for including z_t in the regularizer.
For Remark 4, I think the term z_t^{\top} S_{t-1}^{-1} z_t can still be upper bounded using standard elliptical potential lemma (with some requirement on \lambda). It seems to me that the use of z_t in the regularizer helps to handle the term \psi_t(x_{t+1}) – \psi_{t+1}(x_{t+1}). If we did not include z_t in \psi, it may not be easy for us to cancel the inner product of z_t and x_t in the final step?
Nevertheless, I remember that even for online ridge regression, one can still obtain a log regret, which however depends not only on y_t but also on the predicted loss.
Correct me if I am wrong:)
Thanks for your time!
LikeLike
In Remark 4, the “without assumptions on z_t” is exactly what you mean: you have to choose lambda large enough, but to do that you have to know a bound on ||z_t|| or suffer a bound that is not scale-free anymore.
You are right that there exists a proof of online ridge regression that depends on the maximum loss incurred by the algorithm. I am 100% sure it can also be recovered with this approach, for the simple reason that we have an equality for the FTRL regret! However, on top of my head, I am not sure what is the most painless way to obtain it. Also, I never considered it an interesting bound. It becomes interesting only in the case that we know the range of y_t and we use truncation: there you can control the max loss of the algorithm. For this idea, see https://link.springer.com/chapter/10.1007/978-3-642-16108-7_32
LikeLike
Thanks a lot, Francesco!
Yes, I was also trying to see how to adapt the current proof to *easily* recover the one for ridge regression:)
For Remark 4 on z_t, it seems that the current final explicit bound for VAW also needs a bound on ||z_t||?
Thanks!
LikeLike
||z_t|| must indeed be bounded (even if you could use the tighter bound in terms of the eigenvalues of the covariance matrix too), but the important thing is that the algorithm does not need to know this bound. If we go with online ridge regression and we don’t assume the knowledge of ||z_t|| we would have to reason as in Lemma 14 in http://proceedings.mlr.press/v35/gaillard14.pdf. Probably you get an additional additive max_t y_t^2 ||z_t||^2/lambda in the regret (I am too lazy now to do the exact calculations 😉 )? While it does not seem big, in VAW max_t ||z_t||^2/lambda appears only in the log, while now this is also outside of the log.
LikeLike
Now, I see the difference: analysis vs. algorithm design!
Thanks!
LikeLiked by 1 person