This time we consider an application of Online Mirror Descent (OMD) to the problem of prediction with multi-scale expert advice.
In this setting, at each time step 


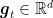

![{[-0.1, 0.1]}](https://s0.wp.com/latex.php?latex=%7B%5B-0.1%2C+0.1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-100, 100]}](https://s0.wp.com/latex.php?latex=%7B%5B-100%2C+100%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
A standard and effective algorithm for this problem is the Exponentiated Gradient (EG) algorithm, which we saw previously as an instance of OMD. The EG algorithm has a regret bound that scales with the largest range of the loss coordinates, so it is not suitable for this problem. We need a different algorithm.
In this setting, we assume that we have prior knowledge of the approximate scale of losses for each expert. Specifically, for each expert 


![{[-c_i, c_i]}](https://s0.wp.com/latex.php?latex=%7B%5B-c_i%2C+c_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Here, we derive an algorithm for this setting as an instance of OMD with a specific choice of surrogate losses. In particular, we run OMD with distance generating function 

Theorem 1. Let
such that
for all
and
. In Algorithm 1, set
. Then, we have


Using the local norm regret upper bound for OMD, we obtain

where 


So, we can upper bound each 

Using again (1), we have that the right hand side of the regret upper bound becomes

Observe that

So, we obtain

Simplifying, we have the stated result.

Let’s now see how we can choose the prior 


Define 





Now, set 





On the other hand, for 

Hence, the previous bound also holds for all 


Note that if 

1. Tuning the Learning Rate using a Multi-scale Algorithm
We now show an interesting application of the multi-scale expert algorithm.
In our analysis of Online Subgradient Descent (OSD), we have seen that the choice of the learning rate 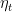


In this section, we demonstrate how to use a multi-scale expert algorithm to design a meta-algorithm that automatically adapts to the best learning rate from a given set, paying only a small price in the regret. The core idea is to treat each instance of an online learning algorithm with a fixed learning rate as an “expert”. We then use a multi-scale expert algorithm to combine the predictions of these experts. The resulting ensemble algorithm will have a regret guarantee that is close to the regret of the best expert—and thus the best learning rate—in hindsight.
Let us consider running 
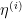




A straightforward approach would be to compute the loss 

To create an efficient algorithm that requires only one subgradient evaluation per round, we can use the following linearization technique. The controller algorithm forms its combined prediction 


Because all experts receive the same linear loss function, they all use the same subgradient 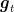


We can now prove a regret bound for this ensemble algorithm.
Theorem 2. Let
and fix
the number of rounds. With the notation in Algorithm 2, assume that the losses
are
-Lipschitz with respect to
. Let
be the set of learning rates for the OSD experts,
, and the learning rate of the Multi-scale Expert algorithm
. Then, Algorithm 2 satisfies
![\displaystyle \sum_{t=1}^T (\ell_t({\boldsymbol x}_t) - \ell_t({\boldsymbol u})) \leq \max(2\|{\boldsymbol u}\|_2, R) L \left[\sqrt{T}\left(1 + 2\sqrt{3+\ln\sqrt{T}}\right)+ 15+5\ln \sqrt{T}\right], \quad \forall {\boldsymbol u}: \|{\boldsymbol u}\|_2 \leq R \sqrt{T} ~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%28%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+-+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29%29+%5Cleq+%5Cmax%282%5C%7C%7B%5Cboldsymbol+u%7D%5C%7C_2%2C+R%29+L+%5Cleft%5B%5Csqrt%7BT%7D%5Cleft%281+%2B+2%5Csqrt%7B3%2B%5Cln%5Csqrt%7BT%7D%7D%5Cright%29%2B+15%2B5%5Cln+%5Csqrt%7BT%7D%5Cright%5D%2C+%5Cquad+%5Cforall+%7B%5Cboldsymbol+u%7D%3A+%5C%7C%7B%5Cboldsymbol+u%7D%5C%7C_2+%5Cleq+R+%5Csqrt%7BT%7D+%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: The choice of 





By the definition of subgradient, the regret of the ensemble algorithm can be bounded by the regret on the linearized losses:

We can now decompose the regret as

The second term is the regret of the best OSD expert on the sequence of linear losses 


For the first term, we have

This is the regret of the Multi-scale Expert algorithm against the expert 






Combining the bounds for both terms completes the proof.
This result shows that by combining OSD instances, we can achieve a regret that is close to the one obtained by the best learning rate in the chosen set. The constraint on 
This technique provides a principled method for automating the selection of learning rates in an online fashion. However, its interest is mostly theoretical: it shows that such adaptivity to
2. History Bits
The multi-scale setting was introduced independently (Dylan Foster, personal communication, 2026) and around the same time by Bubeck et al. (2017), Bubeck et al. (2019) and Foster et al. (2017). Bubeck et al. (2017), Bubeck et al. (2019) propose two algorithms, one for non-positive losses and one for generic losses. Unfortunately, their proof for the generic losses appears to be wrong and not easily fixable. Their bound is similar to the one we proved here. Foster et al. (2017) proved a stronger result, where the term in the logarithm depends on 

The algorithm I describe here is a simplification of the one in Chen et al. (2021). The bound is worse than the one in Cutkosky&Orabona (2018) and Foster et al. (2017), but it is simpler to describe, and it also allowed me to describe the method of the shifted surrogate loss.
The use of shifted surrogate losses in learning with expert advice was proposed in Hazan and Kale (2008), Hazan&Kale (2010) and later used in Steinhardt&Liang (2014). Interestingly, these shifted surrogates can be understood as an approximation of the coin-betting instantaneous log wealth, as one can see by comparing the update of Squint (Koolen&van Erven, 2015) with the update of the KT-based parameter-free algorithm for learning with expert advice.
The idea of running multiple OSD algorithms and aggregating them with a Multi-scale Expert algorithm is from Foster et al. (2017), but they require
