“Go there” the Subgradient said. Photo by Jens Johnsson on Pexels.com
Subgradient descent (SD) is a very simple algorithm for minimizing a non-differentiable convex function. It proceeds iteratively updating the vector moving in the direction of a negative subgradient , but a positive factor called the stepsize. Also, we project onto the feasible set . The pseudocode is in Algorithm 1. It is similar to the gradient descent algorithm, but it has some important conceptual differences.
First, here, we do not assume differentiability of the function so we only have access to a subgradient in any point in , i.e. . Note that this situation is more common than one would think. For example, the hinge loss, , and the ReLU activation function used in neural networks, , are not differentiable.
A second difference, is that SD is not a descent method, that is, it can happen that . The objective function can stay the same or even increase over iterates, no matter what stepsize is used. In fact, a common misunderstanding is that in SD methods the subgradient tells us in which direction to go in order to decrease the value of the function. This wrong intuition often comes from thinking about one dimensional functions. Also, this makes the choice of the stepsizes critical to obtain convergence.
Let’s analyze these issues one at the time.
Subgradient. Let’s first define formally what is a subgradient. For a function , we define a subgradient of in as a vector that satisfies
Basically, a subgradient of in is any vector that allows us to construct a linear lower bound to . Note that the subgradient is not unique, so we denote the set of subgradients of in by . If the function is convex, differentiable in , and is finite in , we have that the subdifferential is composed by a unique element equal to (Rockafellar, R. T., 1970)[Theorem 25.1].
Now, we can take a look at the following examples that illustrate the fact that a subgradient does not always point in a direction where the function decreases.
Example 1
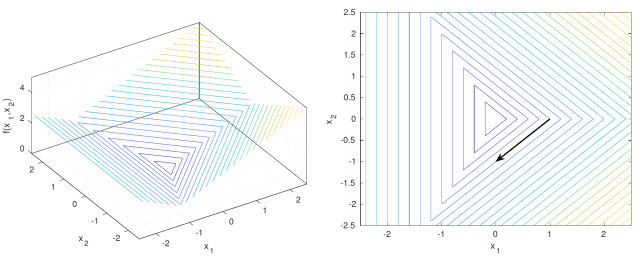
Figure 1. 3D plot (left) and level sets (right) of . The negative subgradient is indicated by the black arrow.Figure 2. 3D plot (left) and level sets (right) of . The negative subgradient is indicated by the black arrow.Let , see Figure 1. The vector is a subgradient in of . No matter how we choose the stepsize, moving in the direction of the negative subgradient will not decrease the objective function. An even more extreme example is in Figure 2, with the function . Here, in the point , any positive step in the direction of the negative subgradient will increase the objective function.
Another effect of the fact that the objective function is non-differentiable is that we cannot use a constant stepsize. This is easy to visualize, even for one-dimensional functions. Take a look for example at the function in Figure 3(left). For any fixed stepsize and any number of iterations, we will never converge to the minimum of the function. Hence, if you want to converge to the minimum, you must use a decreasing stepsize. The same does not happen for smooth functions, for example in Figure 3(right), where the same constant stepsize gives rise to an automatic slowdown in the vicinity of the minimum, because the magnitude of the gradient decreases.
Figure 3. The effect of a constant stepsize on non-differentiable (left) and smooth (right) functions.
Reintepreting the Subgradient Descent Algorithm. Given that SD does not work because it moves towards the minimum, let’s see how it actually works. So, first we have to correctly interpret its behavior.
A way to understand how SD algorithms work is to think that they minimize a local approximation of the original objective function. This is not unusual for optimization algorithms, for example the Netwon’s algorithm construct an approximation with a Taylor expansion truncated to the second term. Thanks to the definition of subgradients, we can immediately build a linear lower bound to the function around :
Unfortunately, minimizing a linear function is unlikely to give us a good optimization algorithm. Indeed, over unbounded domains the minimum of a linear function can be . Hence, the intuitive idea is to constraint the minimization of this lower bound only in a neighboorhood of , where we know that the approximation is more precise. Coding the neighboorhood constraint with a L2 squared distance from less than some positive number , we might think to use the following update
Equivalently, for some , we can consider the unconstrained formulation
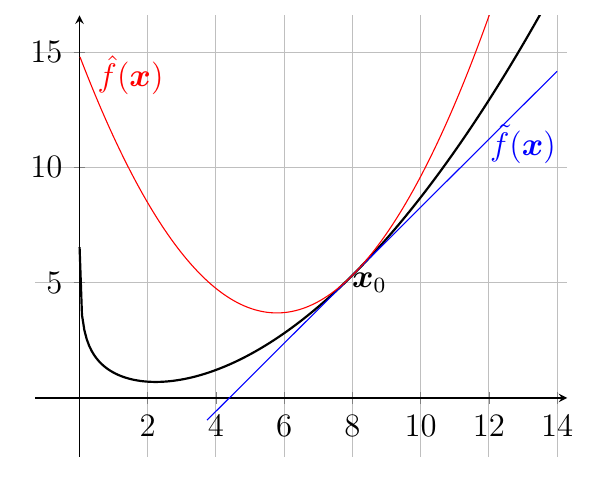
This is a well-defined update scheme, that hopefully moves closer to the optimum of . See Figure 4 for a graphical representation in one-dimension.
Figure 4. Approximations of .
Solving the argmin and completing the square, we get
where is the Euclidean projection onto , i.e. . This is exactly the update of SD in Algorithm 1.
Convergence Analysis. We have shown how to correctly intepret SD. Yet, its intepretation is not a proof of its convergence. Indeed, the interpretation above does not say anything about the stepsizes. So, here we will finally show its convergence guarantee.
We can now show the convergence guarantee for SD. In particular we want to show that
that is optimal for this setting. Keeping in mind that SD is not a descent method, the proof of convergence cannot aim at proving that at each step we descrease the function by a minimum amount. Instead, we show that the suboptimality gap at each step is upper bounded by a term, whose sum grows sublinearly. This means, that the average, and so the minimum, of the suboptimality gaps decreases with the number of iterations.
First, we show the following two Lemmas. The first lemma proves that Euclidean projections always decrease the distance with points inside the set.
Proposition 1 Let and , where is a closed convex set. Then, .
Proof: By the convexity of , we have that for all . Hence, from the optimality of , we have
Rearranging, we obtain
Taking the limit , we get that
Therefore,
The next lemma upper bounds the suboptimality gap in one iteration.
Lemma 2 Let a closed non-empty convex set and a convex function from to . Set . Then, , the following inequality holds
Proof: From Proposition 1 and the definition of subgradient, we have that
Reordering, we have the stated bound.
Theorem 3 Let a closed non-empty convex set with diameter , i.e. . Let a convex function from to . Set . Set . Then, , the following convergence bound hold
Proof: Dividing the inequality in Lemma 2 by and summing over , we have
Dividing both terms by , we have
This is almost a convergence rate, but we need to extract one of the in some way. Hence, we just use Jensen’s inequality on the lhs.
For the second statement, consider the inequality in Lemma 2, divide both sides by 2, and sum over .
Then, again use Jensen’s inequality.
For the third statement, use the fact that
We can immediately observe few things. First, the most known convergence bound for SD (first bound in the theorem) need a bounded domain . In most of the machine learning applications, this assumptions is false. In general, we should be very worried when we use a theorem whose assumptions are clearly false. It is like using a new car that is guaranteed to work only when the outside temperature is above 68 Degrees Fahrenheit, and in the other cases “it seems to work, but we are not sure about it”. Would you drive it?
So, for unbounded domains, we have to rely on the lesser-known second and third guarantees, see, e.g., Zhang, T. (2004).
The other observation is that the above guarantees do not justify the common heuristic of taking the last iterate. Indeed, as we said, SD is not a descent method so the last iterate is not guaranteed to be best one. In the following posts, we will see that we can still prove that the last iterate converges, even in the unbounded case, but the convergence rate gets an additional logarithmic factor.
Another important observation is to use the convergence guarantee to choose the stepsizes. Indeed, it is the only guideline we have. Any other choice that is not justified by a convergence analysis it is not justified at all. A simple choice is to find the constant stepsize that minimizes the bounds for a fixed number of iterations. For simplicity, let’s assume that the domain is bounded. So, in all cases, we have to consider the expression
and minimize with respect to . It is easy to see that the optimal is . See how that gives the regret bound
and the convergence rate
However, we have a problem: in order to use this stepsize, we should know the future subgradients! This is exactly the core idea of adaptive algorithms: how the obtain the best possible guarantee without knowning impossible quantities?
We will see many adaptive strategies, but, for the moment, we can observe that we might be happy to minimize a looser upper bound. In particular, assuming that the functions are -Lischtiz, we have that . Hence, we have
Thanks for the nice explanations. If you don’t mind me asking as silly question. In algorithm 2 in the step of completing the square and solving argmin is there a missing negative (eta_t*gt)^2 term? Shouldn’t we keep the balance when completing the square? (ax^2+bx = x^2+bxa/2+(bxa/2)^2-(bxa/2)^2)? Thanks
Hi Max, sure you could keep that term around, but the argmin would not change because it does not depend on x. Indeed, the argmin is the position of the minimum that does not change if you add a constant term to the function.
Hi Professor Orabona,
Thank you for this page! I would like to cite the results on this post, is there any paper I could refer to? I can’t seem to find these results anywhere else.
Hi Denizap, I am glad you liked this post!
The fact that subgradient descent is not a descent method I guess it is a known result in convex optimization, I am not even sure where I read it for the first time. But if you want a citation, you can cite my monograph on online learning: https://arxiv.org/pdf/1912.13213.pdf You can find the negative examples on this page in Section 6.1 and the theorems in Chapter 6. It is online learning rather than batch, but the theorems are the same. There you can also find the correct citations.


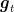
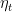








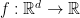


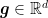

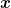


. The negative subgradient is indicated by the black arrow.
. The negative subgradient is indicated by the black arrow.
, see Figure 1. The vector
is a subgradient in
of
. No matter how we choose the stepsize, moving in the direction of the negative subgradient will not decrease the objective function. An even more extreme example is in Figure 2, with the function
. Here, in the point
, any positive step in the direction of the negative subgradient will increase the objective function.

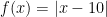











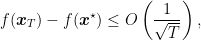
, where
is a closed convex set. Then,
.
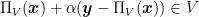
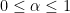
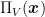

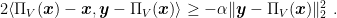


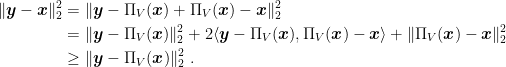

a closed non-empty convex set and
to
. Set
. Then,
, the following inequality holds
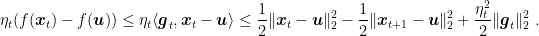
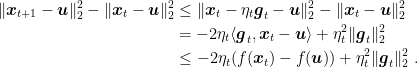
, i.e.
. Let
. Set


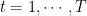
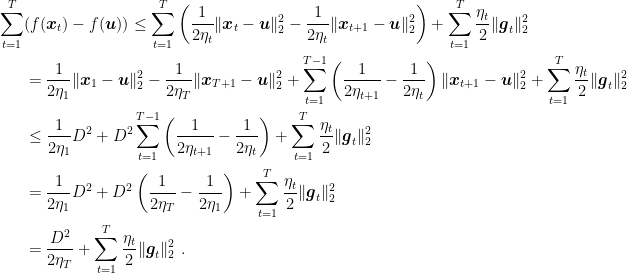

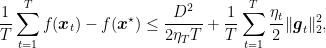






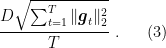





Thanks for the nice explanations. If you don’t mind me asking as silly question. In algorithm 2 in the step of completing the square and solving argmin is there a missing negative (eta_t*gt)^2 term? Shouldn’t we keep the balance when completing the square? (ax^2+bx = x^2+bxa/2+(bxa/2)^2-(bxa/2)^2)? Thanks
LikeLike
Hi Max, sure you could keep that term around, but the argmin would not change because it does not depend on x. Indeed, the argmin is the position of the minimum that does not change if you add a constant term to the function.
LikeLike
Grazie mille, Francesco for the clarification.
LikeLiked by 1 person
Hi Professor Orabona,
Thank you for this page! I would like to cite the results on this post, is there any paper I could refer to? I can’t seem to find these results anywhere else.
LikeLike
Hi Denizap, I am glad you liked this post!
The fact that subgradient descent is not a descent method I guess it is a known result in convex optimization, I am not even sure where I read it for the first time. But if you want a citation, you can cite my monograph on online learning: https://arxiv.org/pdf/1912.13213.pdf You can find the negative examples on this page in Section 6.1 and the theorems in Chapter 6. It is online learning rather than batch, but the theorems are the same. There you can also find the correct citations.
LikeLike