12/4/2021: In the previous version of this post there were some incorrect details that didn’t allow me to sleep well at night. So, I rewrote it in the correct formalism, but please let me know if you see mistakes.
In this post, we talk about solving saddle-point problems with online convex optimization (OCO) algorithms. Next time, I’ll show the connection to two-person zero-sum games and boosting.
1. Saddle-Point Problems
We want to solve the following saddle-point problem

Let’s say from the beginning that we need inf and sup rather than min and max because the minimum or maximum might not exist. Everytime we know for sure the inf/sup are attained, I’ll substitute them with min/max.
While for the minimization of functions is clear what it means to solve it, it might not be immediate to see what is the meaning of “solving” the saddle-point problem in (1). It turns out that the proper notion we are looking for is the one of saddle-point.
Definition 1. Let
,
, and
. A point
is a saddle-point of
in
if
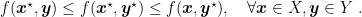
We will now state conditions under which there exists a saddle-point that solves (1). First, we need an easy lemma.
Lemma 2. Let
to
. Then,

Proof: For any 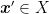




We can now state the following theorem.
Theorem 3. Let
is a saddle-point of
is attained at
, the infimum in
is attained at
, and these two expressions are equal.


Proof: If 

From Lemma 2, we have that these quantities must be equal, so that the three conditions in the theorem are satisfied.
For the other direction, if the conditions are satisfied, then we have
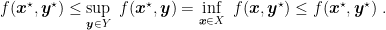
Hence,
Remark 1. The above theorem tells a surprising thing: If a saddle-point exists, then there might be multiple ones, and all of them must have the same minimax value. This might seem surprising, but it is due to the fact that the definition of saddle-point is a global and not a local property. Moreover, if the
and
problem have different values, no saddle-point exists.
Remark 2. Consider the case that the value of the
Let’s show a couple of examples that show that the conditions above are indeed necessary.

 does not have a saddle point.
does not have a saddle point.Example 1. Let
, and
. Then, we have
while
Indeed, from Figure 1 we can see that there is no saddle-point.


Example 2. Let
,
, and
. Then, we have
and
Here, even if inf sup is equal to sup inf, the saddle-point does not exist because the inf in the first expression is not attained in a point of
.
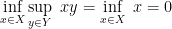

This theorem also tells us that in order to find a saddle-point of a function 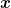



We might be tempted to use 

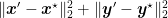

Observe that the Theorem 3 says one of the problems we should solve is

where 


We also have to find the maximizer in

where 


Finally, in case we are interested in studying the quality of a joint solution

where we assumed the existence of a saddle-point to say that 

Definition 4. Let
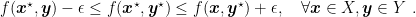
This definition is useful because we cannot expect to numerically calculate a saddle-point with infinite precision, but we can be find something that satisfies the saddle-point definition up to a
Now, the notion of 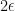
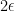
The above reasoning told us that finding the saddle-point of the function
Theorem 5. Let
be compact convex subsets of
and
respectively. Let
a continuous function, convex in its first argument, and concave in its second. Then, we have that

This theorem gives us sufficient conditions to have the min-max problem equal to the max-min one. So, for example, thanks to the Weierstrass theorem, the assumptions in Theorem 5, in light of Theorem 3, are sufficient conditions for the existence of a saddle-point.
We defer the proof of this theorem for a bit and we now turn ways to solve the saddle-point problem in (1).
2. Solving Saddle-Point Problems with OCO
Let’s show how to use Online Convex Optimization (OCO) algorithms to solve saddle-point problems.

Suppose to use an OCO algorithm fed with losses 


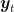
Theorem 6. Let
be convex in the first argument and concave in the second. Then, with the notation in Algorithm 2, for any
, we have
where
.
For any
where
.
Also, if
for any
and
.

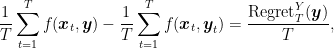
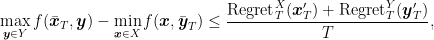
Proof: The first two equalities are obtained simply observing that 
For the inequality, using Jensen’s inequality, we obtain
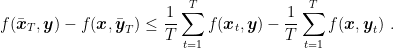
Summing the first two equalities, using the above inequality, and taking 

From this theorem, we can immediately prove the following corollary.
Corollary 7. Let

Example 3. Consider the saddle-point problem
The saddle-point of this problem is
. We can find it using, for example, Projected Online Gradient Descent. So, setting
, we have the iterations
According to Theorem 6, the duality gap in
converges to 0.
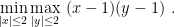
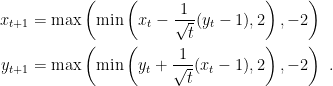
Surprisingly, we can even prove a (simpler version of the) minimax theorem from the above result! In particular, we will use the additional assumption that there exist OCO algorithms that minimize 

Proof with OCO assumption: From Lemma 2, we have one inequality. Hence, we now have to prove the other inequality.
We will use a constructive proof. Let’s use Algorithm 2 and Theorem 6. For the first player, for any

Observe that
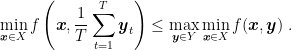
Hence, using an OCO algorithm that has 
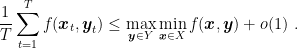
In the same way, we have
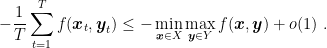
Summing the two inequalities, taking 
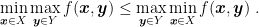
2.1. Variations with Best Response and Alternation
In some cases, it is easy to compute the max with respect to 

In this case, the
Corollary 8. Let
for any
.
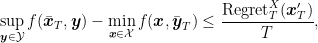
This alternative seems interesting from a theoretical point of view because it allows to avoid the complexity of learning in the

There is a third variant, very used in empirical implementations, especially of Counterfactual Regret Minimization (CFR) (Zinkevich et al., 2007). It is called alternation and it breaks the simultaneous reveal of the actions of the two players. Instead, we use the updated prediction of the first player to construct the loss of the second player. Empirically, this variant seems to greatly speed-up the convergence of the duality gap.

For this version, Theorem 6 does not hold anymore because the terms 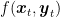

Theorem 9. Let
and any
we have
where

Proof: Note that 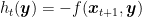

Taking
Remark 3. In the case that
is linear in the first argument, using OMD for the
. Hence, in this case the additional term in Theorem 9 is negative, showing a (marginal) improvement to the convergence rate.
Next post, we will show how to connect saddle-point problems with Game Theory.
3. History Bits
Theorem 3 is (Rockafellar, 1970, Lemma 36.2).
The proof of Theorem 6 is from (Liu and Orabona, 2021) and it is a minor variation on the one in (Abernethy and Wang, 2017): (Liu and Orabona, 2021) stressed the dependency of the regret on a competitor that can be useful for refined bounds, as we will show next time for Boosting. It is my understanding that different variant of this theorem are known in the game theory community as “Folk Theorems”, because such result was widely known among game theorists in the 1950s, even though no one had published it.
The celebrated minimax theorem for zero-sum two-person games was first discovered by John von Neumann in the 1920s (von Neumann, 1928)(von Neumann and Morgenstern, 1944). The version is state here is a simplification of the generalization due to (Sion, 1958). The proof here is from (Abernethy and Wang, 2017). A similar proof is in (Cesa-Bianchi and Lugosi, 2006) based on a discretization of the space that in turn is based on the one in (Freund, Y. and Schapire, 1996)(Freund, Y. and Schapire, 1999).
Algorithms 2 and 3 are a generalization of the algorithm for boosting in (Freund and Schapire, 1996)(Freund and Schapire, 1999). Algorithm 2 was also used in (Abernethy and Wang, 2017) to recover variants of the Frank-Wolfe algorithm (Frank and Wolfe, 1956).
It is not clear who invented alternation. Christian Kroer told me that it was a known trick used in implementations of CFR for the computer poker competition from 2010 or so. Note that in CFR the method of choice is Regret Matching (Hart and Mas-Colell, 2000). However, (Kroer, 2020) empirically shows that alternation improves a lot even OGD for solving bilinear games. (Tammelin et al., 2015) explicitly include this trick in their implementation of an improved version of CFR called CFR+, claiming that it would still guarantee convergence. However, (Farina et al., 2019) pointed out that averaging of the iterates in alternation might not produce a solution to the min-max problem, providing a counterexample. Theorem 9 is from (Burch et al., 2019) (see also (Kroer, 2020)).
There is also a complementary view on alternation: (Zhang et al., 2021) link alternating updates to Gauss-Seidel methods in numerical linear algebra, in contrast to the simultaneous updates of the Jacobi method. Also, they provide a good review of the optimization literature on the advantages of alternation, but this paper and the papers they cite do not seem to be aware of the use of alternation in CFR.
Acknowledgements
Thanks to Christian Kroer for the history of alternation in CFR, and to Gergely Neu for the references on alternation in the optimization community. Thanks to Nicolò Campolongo for hunting down my typos. Also, thanks to Christian Kroer for his great lecture notes that helped me getting started on this topic.
