This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
In this lecture, we will explore a bit more under which conditions we can get better regret upper bounds than 
1. Adaptive Learning Rates for Online Subgradient Descent
Consider the minimization of the linear regret

Using Online Subgradient Descent (OSD), we said that the regret for bounded domains can be upper bounded by

With a fixed learning rate, the learning rate that minimizes this upper bound on the regret is

Unfortunately, as we said, this learning rate cannot be used because it assumes the knowledge of the future rounds. However, we might be lucky and we might try to just approximate it in each round using the knowledge up to time 
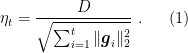
Observe that 

Now let’s see what we obtain with our approximation.

We need a way to upper bound that sum. The way to treat these sums, as we did in other cases, is to try to approximate them with integrals. So, we can use the following very handy Lemma that generalizes a lot of similar specific ones.
Lemma 1 Let
and
a nonincreasing function. Then

Proof: Denote by 
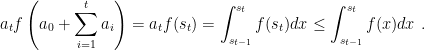
Summing over 

Using this Lemma, we have that

Surprisingly, this term is only a factor of 2 worse than what we would have got from the optimal choice of 

Note that it is possible improve the constant in front of the bound to 

Theorem 2 Let
a closed non-empty convex set with diameter
, i.e.
. Let
an arbitrary sequence of convex functions
subdifferentiable in open sets containing
for
. Pick any
and
. Then,
, the following regret bound holds
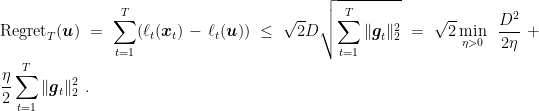
The second equality in the theorem clearly show the advantage of this learning rates: We obtain (almost) the same guarantee we would have got knowing the future gradients!
This is an interesting result on its own: it gives a principled way to set the learning rates with an almost optimal guarantee. However, there are also other consequences of this simple regret. First, we will specialize this result to the case that the losses are smooth.
2. Convex Analysis Bits: Smooth functions
We now consider a family of loss functions that have the characteristic of being lower bounded by the squared norm of the subgradient. We will also introduce the concept of dual norms. While dual norms are not strictly needed for this lecture, they give more generality and at the same time they allows me to slowly introduce some of the concepts that will be needed for the lectures on Online Mirror Descent.
Definition 3 The dual norm
of a norm
is defined as
.
Example 1 The dual norm of the L2 norm is the L2 norm. Indeed,
by Cauchy-Schwartz inequality. Also, set
, so
.
If you never saw it before, the concept of dual norm can be a bit weird at first. One way to understand it is that it is a way to measure how “big” are linear functionals. For example, consider the linear function 


Remark 1 The definition of dual norm immediately implies
.
Now we can introduce smooth functions, using the dual norms defined above.
Definition 4 Let
differentiable. We say that
is
-smooth w.r.t.
for all
.
Keeping in mind the intuition above on dual norms, taking the dual norm of a gradient makes sense if you associate each gradient with the linear functional 
Smooth functions have many properties, for example a smooth function can be upper bounded by a quadratic. However, in the following we will need the following property.
Theorem 5 (e.g. Srebro, N. and Sridharan, K. and Tewari, A., 2010, Lemma 4.1) Let
be


3. 
Assume now that the loss functions 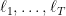

This is an implicit bound, in the sense that 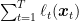
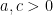 ,
,  , and
, and  such that
such that  . Then
. Then  .
. So, we have the following theorem
Theorem 7 Let
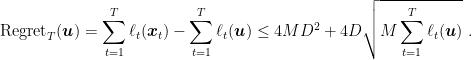
This regret guarantee is very interesting because in the worst case it is still of the order 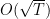
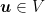
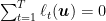
These kind of guarantees are called
4. AdaGrad
We now present another application of the regret bound in (2). AdaGrad, that stands for Adaptive Gradient, is an Online Convex Optimization algorithm proposed independentely by (H. B. McMahan and M. J. Streeter, 2010) and (J. Duchi and E. Hazan and Y. Singer, 2010). It aims at being adaptive to the sequence of gradients. It is usually known as a stochastic optimization algorithm, but in reality it was proposed for Online Convex Optimization (OCO). To use it as a stochastic algorithm, you should use an online-to-batch conversion, otherwise you do not have any guarantee of convergence.
We will present a proof that only allows hyperrectangles as feasible sets
AdaGrad has key ingredients:
- A coordinate-wise learning process;
- The adaptive learning rates in (1).
For the first ingredient, as we said, the regret of any OCO problem can be upper bounded by the regret of the Online Linear Optimization (OLO) problem. That is,
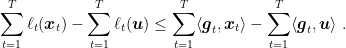
Now, the essential observation is to explicitely write the inner product as a sum of product over the single coordinates:
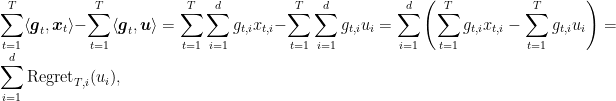
where we denoted by 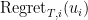

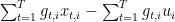

A good candidate for the 1-dimensional problems is OSD with the learning rates in (1). We can specialize the regret in (2) to the 1-dimensional case for linear losses, so we get for each coordinate

This choice gives us the AdaGrad algorithm in Algorithm 1.

Putting all together, we have immediately the following regret guarantee.
Theorem 8 Let
with diameters along each coordinate equal to
. Let
. Then,

Is this a better regret bound compared to the one in Theorem 2? It depends! To compare the two we have to consider that

From Cauchy-Schwarz, we have that 

So, in the case that 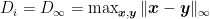
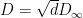


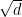
Note that the more general analysis of AdaGrad allows to consider arbitrary domains, but it does not change the general message that the best domains for AdaGrad are hypercubes. We will explore this issue of choosing the online algorithm based on the shape of the feasible set
Hidden in the guarantee is that the biggest advantage of AdaGrad is the property of being coordinate-wise scale-free. That is, if each coordinate of the gradients are multiplied by different constants, the learning rate will automatically scale them back. This is hidden by the fact that the optimal solution 
5. History Bits
The adaptive learning rate in (1) first appeared in (M. Streeter and H. B. McMahan, 2010). However, similar methods were used long time before. Indeed, the key observation to approximate oracle quantities with estimates up to time
AdaGrad was proposed in basically identically form independently by two groups at the same conference: (H. B. McMahan and M. J. Streeter, 2010) and (J. Duchi and E. Hazan and Y. Singer, 2010). The analysis presented here is the one in (M. Streeter and H. B. McMahan, 2010) that does not handle generic feasible sets and does not support “full-matrices”, i.e. full-matrix learning rates instead of diagonal ones. However, in machine learning applications AdaGrad is rarely used with a projection step (even if doing so provably destroys the worst-case performance (F. Orabona and D. Pál, 2018)). Also, in the adversarial setting full-matrices do not seem to offer advantages in terms of regret compared to diagonal ones.
Note that the AdaGrad learning rate is usually written as

where 

AdaGrad inspired an incredible number of clones, most of them with similar, worse, or no regret guarantees. The keyword “adaptive” itself has shifted its meaning over time. It used to denote the ability of the algorithm to obtain the same guarantee as it knew in advance a particular property of the data (i.e. adaptive to the gradients/noise/scale = (almost) same performance as it knew the gradients/noise/scale in advance). Indeed, in Statistics this keyword is used with the same meaning. However, “adaptive” has changed its meaning over time. Nowadays, it seems to denote any kind of coordinate-wise learning rates that does not guarantee anything in particular.
6. Exercises
Exercise 1 Prove that the dual norm of
is
, where
and
.
Exercise 2 Show that using online subgradient descent on a bounded domain with the learning rates
with Lipschitz, smooth, and strongly convex functions you can get
bounds.
Exercise 3 Prove that the logistic loss
, where
and
is
-smooth w.r.t.
.

Hi, nice post!
A few comments:
In theorem 8 I think there’s a typo in the definition of $\eta_{t, i}$: in the denominator the sum should be $\sum_{j=1}^t g_{j, i}^2$ as in Algorithm 1, right?
Also, I’m not totally clear about the comparison between Adagrad and OSD. When you say “It is immediate to see..”, why the first term is smaller or equal than the third term?
Based on my reasoning, if we apply Cauchy-Schwartz we get
$$ \sum_{i=1}^d \sqrt{ \sum_{t=1}^T g_{t, i}^2} \leq \sqrt{d} \sqrt{ \sum_{t=1}^T \| g_t \|_2^2 } $$
and then we can multiply both terms by $ D_\infty $. This would be fine if $ D = \sqrt{d} D_\infty $, but that should hold with inequality, i.e. $ D \leq \sqrt{d} D_\infty $. Indeed, assuming we use the definition of D given in lecture 2, $ D = \max_{x, y \in V} \| x – y \| = \| b – a \| = \sqrt{ \sum_{i=1}^d D_i^2} \leq D_\infty \sqrt{d} $. What am I missing?
LikeLike
Thanks for the finding the typo, I fixed it.
Also, there was some confusion in the text regarding hyperrectangles and hypercubes. I fixed it and made the comparison clearer: It is always better on hyperrectangles and on hypercubes you can might save a factor sqrt{d}. I hope it is better/correct now.
LikeLike
Any hint on how to solve Exercise 2? I followed a similar derivation used for the L* bounds in the notes, but cannot see how we can use the strong convexity to achieve a logarithmic bound
LikeLike
Hi Anirudh, first let me say that the learning rate in (1) won’t work as it is. You need a hybrid learning rate between the one for strongly convex functions and the one in (1). Start from the one for strongly convex functions and try to make it data-dependent.
LikeLike
Thanks for the reply! Will try it as you suggested
LikeLike
It seems there was an error in the text of exercise 2, sorry! I have now fixed it…
LikeLike
Thankss great blog post
LikeLiked by 1 person