This post is part of the lecture notes of my class “Introduction to Online Learning” I taught at Boston University during Fall 2019.
You can find the other lectures here.
In this lecture, we will explore the link between Online Learning and and Statistical Learning Theory.
1. Agnostic PAC Learning
We now consider a different setting from what we have seen till now. We will assume that we have a prediction strategy 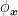
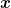





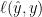
![\displaystyle \min_{{\boldsymbol x} \in V} \ \mathop{\mathbb E}_{({\boldsymbol z},y)\sim\rho}[\ell(\phi_{{\boldsymbol x}}({\boldsymbol z}), y)]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cmathop%7B%5Cmathbb+E%7D_%7B%28%7B%5Cboldsymbol+z%7D%2Cy%29%5Csim%5Crho%7D%5B%5Cell%28%5Cphi_%7B%7B%5Cboldsymbol+x%7D%7D%28%7B%5Cboldsymbol+z%7D%29%2C+y%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
In machine learning terms, the object above is nothing else than the test error and our predictor.
Note that the above setting assumes labeled samples, but we can generalize it even more considering the Vapnik’s general setting of learning, where we collapse the prediction function and the loss in a unique function. This allows, for example, to treat supervised and unsupervised learning in the same unified way. So, we want to minimize the risk
![\displaystyle \min_{{\boldsymbol x} \in V} \ \left(\text{Risk}({\boldsymbol x}):=\mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho} [f({\boldsymbol x},{\boldsymbol \xi})]\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5C+%5Cleft%28%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D%29%3A%3D%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D+%5Bf%28%7B%5Cboldsymbol+x%7D%2C%7B%5Cboldsymbol+%5Cxi%7D%29%5D%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where 



Example 1. In a linear regression task where the loss is the square loss, we have
and
. Hence,
.
Example 2. In linear binary classification where the loss is the hinge loss, we have
and
. Hence,
.
Example 3. In binary classification with a neural network with the logistic loss, we have
and
.
The key difficulty of the above problem is that we don’t know the distribution 

where 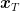
It should be clear that this is just an optimization problem and we are interested in upper bounding the suboptimality gap. In this view, the objective of machine learning can be considered as a particular optimization problem.
Remark 1. Note that this is not the only way to approach the problem of learning. Indeed, the regret minimization model is an alternative model to learning. Moreover, another approach would be to try to estimate the distribution
Given that we have access to the distribution
Quantifying the dependency of precision and probability of failure on the number of samples used is the objective of the Agnostic Probably Approximately Correct (PAC) framework, where the keyword “agnostic” refers to the fact that we don’t assume anything on the best possible predictor. More in details, given a precision parameter 


Definition 1. We will say that a function class
is Agnostic-PAC-learnable if there exists an algorithm
and a function
such that when
samples drawn from
Note that the Agnostic PAC learning setting does not say what is the procedure we should follow to find such sample complexity. The approach most commonly used in machine learning to solve the learning problem is the so-called Empirical Risk Minimization (ERM) problem. It consist of drawing

In words, ERM is nothing else than minimize the error on a training set. However, in many interesting cases we can have that 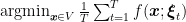
![{\mathop{\mathrm{argmin}}_{{\boldsymbol x} \in V} \mathop{\mathbb E}[f({\boldsymbol x};{\boldsymbol \xi})]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathrm%7Bargmin%7D%7D_%7B%7B%5Cboldsymbol+x%7D+%5Cin+V%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%7B%5Cboldsymbol+x%7D%3B%7B%5Cboldsymbol+%5Cxi%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The ERM approach is so widespread that machine learning itself is often wrongly identified with some kind of minimization of the training error. We now show that ERM is not the entire world of ML, showing that the existence of a no-regret algorithm, that is an online learning algorithm with sublinear regret, guarantee Agnostic-PAC learnability. More in details, we will show that an online algorithm with sublinear regret can be used to solve machine learning problems. This is not just a curiosity, for example this gives rise to computationally efficient parameter-free algorithms, that can be achieved through ERM only running a two-step procedure, i.e. running ERM with different parameters and selecting the best solution among them.
We already mentioned this possibility when we talked about the online-to-batch conversion, but this time we will strengthen it proving high probability guarantees rather than expectation ones.
So, we need some more bits on concentration inequalities.
2. Bits on Concentration Inequalities
We will use a concentration inequality to prove the high probability guarantee, but we will need to go beyond the sum of i.i.d.random variables. In particular, we will use the concept of martingales.
Definition 2. A sequence of random variables
is called a martingale if for all
it satisfies:
![\displaystyle \begin{aligned} &\mathop{\mathbb E}[|X_t|]< \infty, &\mathop{\mathbb E}[X_{t+1}|X_1, \dots, X_t] = X_t~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26%5Cmathop%7B%5Cmathbb+E%7D%5B%7CX_t%7C%5D%3C+%5Cinfty%2C+%26%5Cmathop%7B%5Cmathbb+E%7D%5BX_%7Bt%2B1%7D%7CX_1%2C+%5Cdots%2C+X_t%5D+%3D+X_t%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Example 4. Consider a fair coin
and a betting algorithm that bets
money on each round on the side of the coin equal to
. We win or lose money 1:1, so the total money we won up to round
is
.
is a martingale. Indeed, we have
![\displaystyle \mathop{\mathbb E}[Z_t|Z_1, \dots, Z_{t-1}] =\mathop{\mathbb E}[Z_{t-1} + x_t c_t|Z_1, \dots, Z_{t-1}] =Z_{t-1} + \mathop{\mathbb E}[x_t c_t|Z_1, \dots, Z_{t-1}] =0~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BZ_t%7CZ_1%2C+%5Cdots%2C+Z_%7Bt-1%7D%5D+%3D%5Cmathop%7B%5Cmathbb+E%7D%5BZ_%7Bt-1%7D+%2B+x_t+c_t%7CZ_1%2C+%5Cdots%2C+Z_%7Bt-1%7D%5D+%3DZ_%7Bt-1%7D+%2B+%5Cmathop%7B%5Cmathbb+E%7D%5Bx_t+c_t%7CZ_1%2C+%5Cdots%2C+Z_%7Bt-1%7D%5D+%3D0%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
For bounded martingales we can prove high probability guarantees as for bounded i.i.d. random variables. The following Theorem will be the key result we will need.
Theorem 3 (Hoeffding-Azuma inequality). Let
be a martingale of
almost surely. Then, we have
Also, the same upper bounds hold on
.
![\displaystyle \mathop{\mathbb P}[Z_T - Z_0 \geq \epsilon] \leq \exp\left(-\frac{\epsilon^2}{2 B^2 T}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+P%7D%5BZ_T+-+Z_0+%5Cgeq+%5Cepsilon%5D+%5Cleq+%5Cexp%5Cleft%28-%5Cfrac%7B%5Cepsilon%5E2%7D%7B2+B%5E2+T%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
3. From Regret to Agnostic PAC
We now show how the online-to-batch conversion we introduced before gives us high probability guarantee for our machine learning problem.
Theorem 4. Let
, where the expectation is w.r.t.
drawn from
. Draw
i.i.d. from
. Run any online learning algorithm over the losses
, to construct the sequence of predictions
. Then, we have with probability at least

Proof: Define 
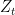
![\displaystyle \mathop{\mathbb E}[\ell_t({\boldsymbol x}_t)|{\boldsymbol \xi}_1, \dots, {\boldsymbol \xi}_{t-1}] = \mathop{\mathbb E}[ f({\boldsymbol x}_t, {\boldsymbol \xi}_t)|{\boldsymbol \xi}_1, \dots, {\boldsymbol \xi}_{t-1}] = \text{Risk}({\boldsymbol x}_t),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29%7C%7B%5Cboldsymbol+%5Cxi%7D_1%2C+%5Cdots%2C+%7B%5Cboldsymbol+%5Cxi%7D_%7Bt-1%7D%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5B+f%28%7B%5Cboldsymbol+x%7D_t%2C+%7B%5Cboldsymbol+%5Cxi%7D_t%29%7C%7B%5Cboldsymbol+%5Cxi%7D_1%2C+%5Cdots%2C+%7B%5Cboldsymbol+%5Cxi%7D_%7Bt-1%7D%5D+%3D+%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D_t%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where we used the fact that 

![\displaystyle \mathop{\mathbb E}[Z_{t+1}|Z_1, \dots, Z_{t}]= Z_{t}+ \mathop{\mathbb E}[\text{Risk}({\boldsymbol x}_{t+1})-\ell_{t+1}({\boldsymbol x}_{t+1})|Z_1, \dots, Z_{t}] = Z_{t},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BZ_%7Bt%2B1%7D%7CZ_1%2C+%5Cdots%2C+Z_%7Bt%7D%5D%3D+Z_%7Bt%7D%2B+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29-%5Cell_%7Bt%2B1%7D%28%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%29%7CZ_1%2C+%5Cdots%2C+Z_%7Bt%7D%5D+%3D+Z_%7Bt%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
that proves our claim.
Hence, using Theorem 3, we have
![\displaystyle \mathop{\mathbb P}\left[ \sum_{t=1}^T \left(\text{Risk}({\boldsymbol x}_i)-\ell_i({\boldsymbol x}_i)\right)\geq \epsilon\right] =\mathop{\mathbb P}\left[ Z_T-Z_0\geq \epsilon\right] \leq \exp\left(-\frac{\epsilon^2}{2T}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D_i%29-%5Cell_i%28%7B%5Cboldsymbol+x%7D_i%29%5Cright%29%5Cgeq+%5Cepsilon%5Cright%5D+%3D%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B+Z_T-Z_0%5Cgeq+%5Cepsilon%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28-%5Cfrac%7B%5Cepsilon%5E2%7D%7B2T%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
This implies that, with probability at least 
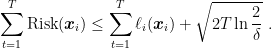
or equivalently

We now use the definition of regret w.r.t. any 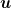

The last step is to upper bound with high probability 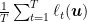




Putting all together and using the union bound, we have the stated bound.

The theorem above upper bounds the average risk of the 
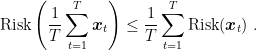
If the risk is not a convex function, we need a way to generate a single solution with small risk. One possibility is to construct a stochastic classifier that samples one of the

where the expectation in the definition of the risk of the stochastic classifier is also with respect to the random index. Yet another way, is to select among the 
Theorem 5. We have a finite set of predictors
and a dataset of
. Then, with probability at least

Proof: We want to calculate the probability that the hypothesis that minimizes the validation error is far from the best hypothesis in the set. We cannot do it directly because we don’t have the required independence to use a concentration. Instead, we will upper bound the probability that there exists at least one function whose empirical risk is far from the risk. So, we have
![\displaystyle \mathop{\mathbb P}\left[\exists {\boldsymbol x} \in S: |\text{Risk}({\boldsymbol x})-\widehat{\text{Risk}}({\boldsymbol x})| > \frac{\epsilon}{2}\right] \leq \sum_{i=1}^{|S|} \mathop{\mathbb P}\left[|\text{Risk}({\boldsymbol x}_i)-\widehat{\text{Risk}}({\boldsymbol x}_i)| > \frac{\epsilon}{2}\right] \leq |S| \exp\left(-\frac{\epsilon^2T}{2}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B%5Cexists+%7B%5Cboldsymbol+x%7D+%5Cin+S%3A+%7C%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D%29-%5Cwidehat%7B%5Ctext%7BRisk%7D%7D%28%7B%5Cboldsymbol+x%7D%29%7C+%3E+%5Cfrac%7B%5Cepsilon%7D%7B2%7D%5Cright%5D+%5Cleq+%5Csum_%7Bi%3D1%7D%5E%7B%7CS%7C%7D+%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B%7C%5Ctext%7BRisk%7D%28%7B%5Cboldsymbol+x%7D_i%29-%5Cwidehat%7B%5Ctext%7BRisk%7D%7D%28%7B%5Cboldsymbol+x%7D_i%29%7C+%3E+%5Cfrac%7B%5Cepsilon%7D%7B2%7D%5Cright%5D+%5Cleq+%7CS%7C+%5Cexp%5Cleft%28-%5Cfrac%7B%5Cepsilon%5E2T%7D%7B2%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, with probability at least


We are now able to upper bound the risk of 

where in the last inequality we used the fact that
Using this theorem, we can use 

It is important to note that with any of the above three methods to select one
Another important point is that the above guarantee does not imply the existence of online learning algorithms with sublinear regret for any learning problem. It just says that, if it exists, it can be used in the statistical setting too.
4. History Bits
Theorem 4 is from (N. Cesa-Bianchi and A. Conconi and Gentile, C. , 2004). Theorem 5 is nothing else than the Agnostic PAC learning guarantee for ERM for hypothesis classes with finite cardinality. (N. Cesa-Bianchi and A. Conconi and Gentile, C. , 2004) gives also an alternative procedure to select a single hypothesis among the
