
There is a popular interpretation of the Perceptron as a stochastic (sub)gradient descent procedure. I even found slides online with this idea. The thought of so many young minds twisted by these false claims was too much to bear. So, I felt compelled to write a blog post to explain why this is wrong… 😉
Moreover, I will also give a different and (I think) much better interpretation of the Perceptron algorithm.
1. Perceptron Algorithm
The Perceptron algorithm was introduced by Rosenblatt in 1958. To be more precise, he introduced a family of algorithms characterized by a certain architecture. Also, he considered what we call now supervised and unsupervised training procedures. However, nowadays when we talk about the Perceptron we intend the following algorithm:

In the algorithm, the couples 






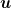

From an optimization point of view, this is called a feasibility problem, that is something like

where 
In the Perceptron case, we can restate the problem as
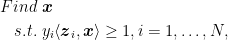
where the “1” on the r.h.s. is clearly arbitrary and it can be changed through rescaling of 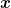
2. Issues with the SGD Interpretation
As said above, sometimes people refer to the Perceptron as a stochastic (sub)gradient descent algorithm on the objective function

I think they are many problems with this ideas, let me list some of them
- First of all, the above interpretation assumes that we take the samples randomly from
. However, this is not needed in the Perceptron and it was not needed in the first proofs of the Perceptron convergence (Novikoff, 1963). There is a tendency to call anything that receive one sample at a time as “stochastic”, but “arbitrary order” and “stochastic” are clearly not the same.
- The Perceptron is typically initialized with
. Now, we have two problems. The first one is that with a black-box first-order oracle, we would get a subgradient of a
, where
is drawn uniformly at random in
. A possible subgradient for any
. This means that SGD would not update. Instead, the Perceptron in this case does update. So, we are forced to consider a different model than the black-box one. Changing the oracle model is a minor problem, but this fact hints to another very big issue.
- The biggest issue is that
! So, there is nothing to minimize, we are already done in the first iteration. However, from a classification point of view, this solution seems clearly wrong. So, it seems we constructed an objective function we want to minimize and a corresponding algorithm, but for some reason we do not like one of its infinite minimizers. So, maybe, the objective function is wrong? So, maybe, this interpretation misses something?
There is an easy way to avoid some of the above problems: change the objective function to a parametrized loss that has non-zero gradient in zero. For example, something like this

Now, when 
To be honest, I am not sure this is a satisfying solution. Moreover, the stochasticity is still there and it should be removed.
Now, I already proved a mistake bound for the Perceptron, without any particular interpretation attached to it. As a matter of fact, proofs do not need interpretations to be correct. I showed that the Perceptron competes with a family of loss functions that implies that it does not just use the subgradient of a single function. However, if you need an intuitive way to think about it, let me present you the idea of pseudogradients.
3. Pseudogradients
Suppose we want to minimize a function 


In a very intuitive way,

where 
Note that (Polyak and Tsypkin, 1973) define the pseudogradients as a stochastic vector that satisfies the above inequality in conditional expectation and for a time-varying 
Let’s see how this would work. Let’s assume that 
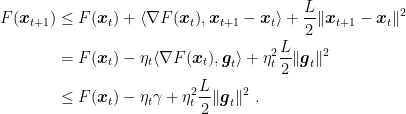
Now, if 

To get a rate of convergence, we should know something more about 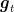


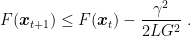
This is still not enough because it is clear that 
4. Pseudogradients for the Perceptron
How do we use this to explain the Perceptron? Suppose your set 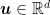
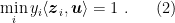
Note that the value of the margin is arbitrary, we can change it just rescaling
Remark 1. An equivalent way to restate this condition is to constrain
where

We would like to construct an algorithm to find 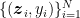

![{{\boldsymbol g}_t = -y_i {\boldsymbol z}_i \boldsymbol{1}[y_i \langle {\boldsymbol z}_i, {\boldsymbol x}_t\rangle \leq 0]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+g%7D_t+%3D+-y_i+%7B%5Cboldsymbol+z%7D_i+%5Cboldsymbol%7B1%7D%5By_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Cleq+0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
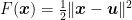
![\displaystyle \begin{aligned} \langle {\boldsymbol g}_t, \nabla F({\boldsymbol x}_t) \rangle &= \langle -y_i {\boldsymbol z}_i \boldsymbol{1}[y_i \langle {\boldsymbol z}_i, {\boldsymbol x}_t\rangle \leq 0], {\boldsymbol x}_t-{\boldsymbol u}\rangle \\ &= \boldsymbol{1}[y_i \langle {\boldsymbol z}_i, {\boldsymbol x}_t\rangle \leq 0](\langle -y_i {\boldsymbol z}_i, {\boldsymbol x}_t\rangle + y_i \langle {\boldsymbol z}_i, {\boldsymbol u}\rangle) \\ &\geq \boldsymbol{1}[y_i \langle {\boldsymbol z}_i, {\boldsymbol x}_t\rangle \leq 0], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%5Cnabla+F%28%7B%5Cboldsymbol+x%7D_t%29+%5Crangle+%26%3D+%5Clangle+-y_i+%7B%5Cboldsymbol+z%7D_i+%5Cboldsymbol%7B1%7D%5By_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Cleq+0%5D%2C+%7B%5Cboldsymbol+x%7D_t-%7B%5Cboldsymbol+u%7D%5Crangle+%5C%5C+%26%3D+%5Cboldsymbol%7B1%7D%5By_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Cleq+0%5D%28%5Clangle+-y_i+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%2B+y_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+u%7D%5Crangle%29+%5C%5C+%26%5Cgeq+%5Cboldsymbol%7B1%7D%5By_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Cleq+0%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where in the last inequality we used (2).
Let’s pause for a moment to look at what we did: We want to minimize 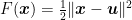
At this point we are basically done. In fact, observe that 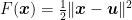
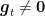
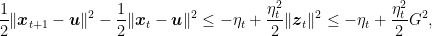
where in the last inequality we have assumed 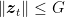
Setting 



where used the fact that
Now, there is the actual magic of the (parameter-free!) Perceptron update rule: as we explained here, the updates of the Perceptron are independent of 


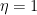
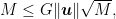
that is
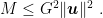
Now, observing that the r.h.s. is independent of
Are we done? Not yet! We can now improve the Perceptron algorithm taking full advantage of the pseudogradients interpretation.
5. An Improved Perceptron
This is a little known idea to improve the Perceptron. It can be shown with the classic analysis as well, but it comes very naturally from the pseudogradient analysis.
Let’s start from
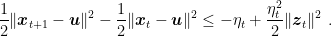
Now consider only the rounds in which 
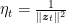
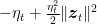

This means that now the update rule becomes
![\displaystyle {\boldsymbol x}_{t+1} = {\boldsymbol x}_t + \frac{y_i {\boldsymbol z}_i}{\|{\boldsymbol z}_i\|^2} \boldsymbol{1}[y_i \langle {\boldsymbol z}_i, {\boldsymbol x}_t \rangle \leq 0]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D+%3D+%7B%5Cboldsymbol+x%7D_t+%2B+%5Cfrac%7By_i+%7B%5Cboldsymbol+z%7D_i%7D%7B%5C%7C%7B%5Cboldsymbol+z%7D_i%5C%7C%5E2%7D+%5Cboldsymbol%7B1%7D%5By_i+%5Clangle+%7B%5Cboldsymbol+z%7D_i%2C+%7B%5Cboldsymbol+x%7D_t+%5Crangle+%5Cleq+0%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Now, summing (3) over time, we get
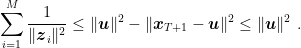
It is clear that this inequality implies the previous one because 
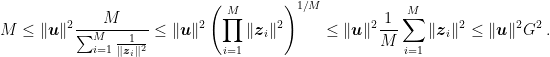
In words, the original Perceptron bound depends on the maximum squared norm of the samples on which we updated. Instead, this bound depends on the geometric or arithmetic mean of the squared norm of the samples on which we updated, that is less or equal to the maximum.
6. Pseudogradients and Lyapunov Potential Functions
Some people might have realized yet another way to look at this:
Moreover, the idea of the pseudogradients is more general because it applies to any smooth function, not only to the choice of
Overall, it is clear that all the good analyses of the Perceptron must have something in common. However, sometimes recasting a problem in a particular framework might have some advantages because it helps our intuition. In this view, I find the pseudogradient view particularly compelling because it aligns with my intuition of how an optimization algorithm is supposed to work.
7. History Bits
I already wrote about the Perceptron, so I will just add few more relevant bits.
As I said, it seems that the family of Perceptrons algorithms was intended to be something much more general than what we intend now. The particular class of Perceptron we use nowadays were called
I got the idea of smoothing the Perceptron algorithm with a scaled logistic loss from a discussion on Twitter with Maxim Raginsky. He wrote that (Aizerman, Braverrnan, and Rozonoer, 1970) proposed some kind of smoothing in a Russian book for the objective function in (1), but I don’t have access to it so I am not sure what are the details. I just thought of a very natural one.
The idea of pseudogradients and the application to the Perceptron algorithm is in (Polyak and Tsypkin, 1973). However, there the input/output samples are still stochastic and the finite bound is not explicitly calculated. As I have shown, stochasticity is not needed. It is important to remember that online convex optimization as a field will come much later, so there was no reason for these people to consider arbitrary or even adversarial order of the samples.
The improved Perceptron mistake bound could be new (but please let me know if it isn’t!) and it is inspired from the idea in (Graepel, Herbrich, and Williamson, 2001) of normalizing the samples to show a tighter bound.
Acknowledgements
Given the insane amount of mistakes that Nicolò Campolongo usually finds in my posts, this time I asked him to proofread it. So, I thank Nicolò for finding an insane amout of mistakes on a draft of this post 🙂

Shouldn’t the step 4 of algorithm 1 be in the opposite direction? I feel like if the classification is correct, then we shouldn’t change the weights anymore.
LikeLike
Yes, fixed, thanks!
LikeLike