In this blog (and in our ICML 2020 tutorial) we have often discussed the issue of how to tune learning rates in Stochastic (sub)Gradient Descent (SGD). This issue is delicate and sometimes a student might not realize its complexity due to the use of the simplifying assumption of bounded domains.

Don’t get me wrong: assuming bounded domains is perfectly fine and justified most of the time. However, sometimes it is unnecessary and it might also obscure critical issues in the analysis, as in this case. So, to balance the universe of first-order methods, I decided to show how to easily prove the convergence of the iterates in SGD, even in unbounded domains.
Technically speaking, the following result might be new, but definitely not worth a fight with Reviewer 2 to publish it somewhere.
1. Setting
First, let’s define our setting. We want to solve the following optimization problem

where 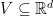




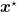
We also assume to have access to a first-order stochastic oracle that returns stochastic sub-gradients of 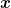

![{\mathop{\mathbb E}_\xi[{\boldsymbol g}({\boldsymbol x},\xi)] \in \partial F({\boldsymbol x})}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%5Cxi%5B%7B%5Cboldsymbol+g%7D%28%7B%5Cboldsymbol+x%7D%2C%5Cxi%29%5D+%5Cin+%5Cpartial+F%28%7B%5Cboldsymbol+x%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Here, for didactic reasons, we will assume that ![{{\mathop{\mathbb E}}_\xi[\|{\boldsymbol g}({\boldsymbol x},\xi)\|^2_2]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathop%7B%5Cmathbb+E%7D%7D_%5Cxi%5B%5C%7C%7B%5Cboldsymbol+g%7D%28%7B%5Cboldsymbol+x%7D%2C%5Cxi%29%5C%7C%5E2_2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The algorithm we want to focus on is SGD. So, what is SGD? SGD is an incredibly simple optimization algorithm, almost primitive. Indeed, part of its fame depends critically on its simplicity. Basically, you start from a certain 
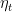
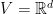
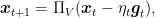
where 

2. Convergence of the Average of the Iterates
Now, the most common analysis of SGD can be done in two different ways: constant learning rate and non-increasing learning rate. We already saw both of them in my lecture notes on online learning, so let’s summarize here the one-step inequality for SGD we need:
![\displaystyle \label{eq:one_step} \eta_t {\mathop{\mathbb E}}[F({\boldsymbol x}_t) - F({\boldsymbol u})] \leq \frac{1}{2}{\mathop{\mathbb E}}[\|{\boldsymbol u}-{\boldsymbol x}_t\|^2] - \frac{1}{2}{\mathop{\mathbb E}}[\|{\boldsymbol u}-{\boldsymbol x}_{t+1}\|^2] + \eta^2_t {\mathop{\mathbb E}}[\|{\boldsymbol g}_t\|^2], \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Aone_step%7D+%5Ceta_t+%7B%5Cmathop%7B%5Cmathbb+E%7D%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29+-+F%28%7B%5Cboldsymbol+u%7D%29%5D+%5Cleq+%5Cfrac%7B1%7D%7B2%7D%7B%5Cmathop%7B%5Cmathbb+E%7D%7D%5B%5C%7C%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_t%5C%7C%5E2%5D+-+%5Cfrac%7B1%7D%7B2%7D%7B%5Cmathop%7B%5Cmathbb+E%7D%7D%5B%5C%7C%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_%7Bt%2B1%7D%5C%7C%5E2%5D+%2B+%5Ceta%5E2_t+%7B%5Cmathop%7B%5Cmathbb+E%7D%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C%5E2%5D%2C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
for all 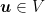

If you plan to use 

![\displaystyle \sum_{t=1}^T \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)] - F({\boldsymbol x}^\star)\right) \leq \frac{\sqrt{T}}{2}\left(\frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{\alpha} + \alpha\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D+-+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%5Cright%29+%5Cleq+%5Cfrac%7B%5Csqrt%7BT%7D%7D%7B2%7D%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B%5Calpha%7D+%2B+%5Calpha%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where we set 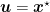
![\displaystyle \mathop{\mathbb E}[F(\bar{{\boldsymbol x}}_T)] \leq F({\boldsymbol x}^\star) + \frac{1}{2\sqrt{T}}\left(\frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{\alpha} + \alpha\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D+%5Cleq+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%2B+%5Cfrac%7B1%7D%7B2%5Csqrt%7BT%7D%7D%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B%5Calpha%7D+%2B+%5Calpha%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where 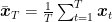
Constant learning rates are a bit annoying because they depends on how many iterations you plan to do, theoretically and empirically. So, let’s now take a look at non-increasing learning rates, 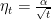
![\displaystyle \begin{aligned} \sum_{t=1}^T \eta_t \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)] - F({\boldsymbol x}^\star) \right) &\leq \frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{2} + \frac{1}{2} \sum_{t=1}^T \eta_t^2 \\ &\leq \frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{2} + \frac{\alpha^2}{2} (\ln T+1), & (2) \\\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D+-+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cright%29+%26%5Cleq+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B2%7D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t%5E2+%5C%5C+%26%5Cleq+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B2%7D+%2B+%5Cfrac%7B%5Calpha%5E2%7D%7B2%7D+%28%5Cln+T%2B1%29%2C+%26+%282%29+%5C%5C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where we set
![\displaystyle \sum_{t=1}^T \eta_t \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)] - F({\boldsymbol x}^\star) \right) \geq \eta_T \sum_{t=1}^T \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)] - F({\boldsymbol x}^\star) \right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D+-+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cright%29+%5Cgeq+%5Ceta_T+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D+-+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
because
![\displaystyle \mathop{\mathbb E}[F(\bar{{\boldsymbol x}}_T)] \leq F({\boldsymbol x}^\star) + \frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{2 \alpha \sqrt{T}} + \frac{\alpha (\ln T+1)}{2\sqrt{T}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_T%29%5D+%5Cleq+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%2B+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B2+%5Calpha+%5Csqrt%7BT%7D%7D+%2B+%5Cfrac%7B%5Calpha+%28%5Cln+T%2B1%29%7D%7B2%5Csqrt%7BT%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Note that if you like these sorts of games, you can even change the learning rate to shave a 
Another possibility is to use a weighted average:
![\displaystyle \begin{aligned} \mathop{\mathbb E}[F(\bar{{\boldsymbol x}}'_T)] &\leq F({\boldsymbol x}^\star) + \frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2 + \alpha^2 (\ln T+1)}{2 \sum_{t=1}^T \eta_t} \\ &\leq F({\boldsymbol x}^\star) + \frac{1}{4\sqrt{T+1}-4}\left(\frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{\alpha} + \alpha (\ln T+1)\right), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D%27_T%29%5D+%26%5Cleq+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%2B+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2+%2B+%5Calpha%5E2+%28%5Cln+T%2B1%29%7D%7B2+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t%7D+%5C%5C+%26%5Cleq+F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%2B+%5Cfrac%7B1%7D%7B4%5Csqrt%7BT%2B1%7D-4%7D%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B%5Calpha%7D+%2B+%5Calpha+%28%5Cln+T%2B1%29%5Cright%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where 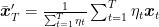
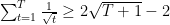
Let’s summarize what we have till now:
- Unbounded domains are fine with both constant and time-varying learning rates.
- The optimal learning rate depends on the distance between the optimal solution and the initial iterate, because the optimal setting of
is proportional to
.
- The weighted average is probably a bad idea and not strictly necessary.
- It seems we can only guarantee convergence for (weighted) averages of iterates.
The last point is a bit concerning: most of the time we take the last iterate of SGD, why we do it if the theory applies to the average?
3. Convergence of the Last Iterate
Actually, we do know that
- the last solution of SGD converges in unbounded domains with constant learning rate (Zhang, T., 2004).
- the last iterate of SGD converges in bounded domains with non-increasing learning rates (Shamir, O. and Zhang, T., 2013).
So, what about unbounded domains and non-increasing learning rate, i.e., 90% of the uses of SGD? It turns out that it is equally simple and I think the proof is also instructive! As surprising as it might sound, not dividing by 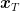

Lemma 1. Let
a non-increasing sequence of positive numbers and
. Then
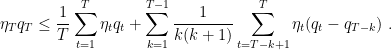
With the above Lemma, we can prove the following guarantee for the convergence of the last iterate of SGD.
Theorem 2. Assume the stepsizes deterministic and non-increasing. Then
![\displaystyle \label{eq:thm_last_one} \eta_T \left(\mathop{\mathbb E}[F({\boldsymbol x}_T)]-F({\boldsymbol x}^\star)\right) \leq \frac{1}{T} \sum_{t=1}^T \eta_t \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)]-F({\boldsymbol x}^\star)\right) + \frac{1}{2} \sum_{k=1}^{T-1} \frac{1}{k (k+1)}\sum_{t=T-k}^T \eta^2_t\mathop{\mathbb E}[\|{\boldsymbol g}_t\|^2_2]~. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Athm_last_one%7D+%5Ceta_T+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_T%29%5D-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%5Cright%29+%5Cleq+%5Cfrac%7B1%7D%7BT%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%5Cright%29+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Csum_%7Bk%3D1%7D%5E%7BT-1%7D+%5Cfrac%7B1%7D%7Bk+%28k%2B1%29%7D%5Csum_%7Bt%3DT-k%7D%5ET+%5Ceta%5E2_t%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C%5E2_2%5D%7E.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We use Lemma 1, with ![{q_t=\mathop{\mathbb E}[F({\boldsymbol x}_t)]-F({\boldsymbol x}^\star)}](https://s0.wp.com/latex.php?latex=%7Bq_t%3D%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \eta_T \left(\mathop{\mathbb E}[F({\boldsymbol x}_t)]-F({\boldsymbol x}^\star)\right) \leq \frac{1}{T} \sum_{t=1}^T \eta_t \mathop{\mathbb E}[F({\boldsymbol x}_t)-F({\boldsymbol x}^\star)] + \sum_{k=1}^{T-1} \frac{1}{k(k+1)} \sum_{t=T-k+1}^T \eta_t \mathop{\mathbb E}[F({\boldsymbol x}_t) - F({\boldsymbol x}_{T-k})]~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ceta_T+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29%5D-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%5Cright%29+%5Cleq+%5Cfrac%7B1%7D%7BT%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Ceta_t+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%5D+%2B+%5Csum_%7Bk%3D1%7D%5E%7BT-1%7D+%5Cfrac%7B1%7D%7Bk%28k%2B1%29%7D+%5Csum_%7Bt%3DT-k%2B1%7D%5ET+%5Ceta_t+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29+-+F%28%7B%5Cboldsymbol+x%7D_%7BT-k%7D%29%5D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we bound the sum in the r.h.s. of last inequality. Summing (1) from 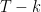
![\displaystyle \begin{aligned} \sum_{t=T-k}^T \eta_t \mathop{\mathbb E}[F({\boldsymbol x}_t)-F({\boldsymbol u})] \leq \frac12 \mathop{\mathbb E}[\|{\boldsymbol x}_{T-k}-{\boldsymbol u}\|^2] + \frac{1}{2}\sum_{t=T-k}^T \eta^2_t \mathop{\mathbb E}[\|{\boldsymbol g}_t\|^2_2]~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3DT-k%7D%5ET+%5Ceta_t+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29-F%28%7B%5Cboldsymbol+u%7D%29%5D+%5Cleq+%5Cfrac12+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+x%7D_%7BT-k%7D-%7B%5Cboldsymbol+u%7D%5C%7C%5E2%5D+%2B+%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bt%3DT-k%7D%5ET+%5Ceta%5E2_t+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C%5E2_2%5D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, setting 
![\displaystyle \sum_{t=T-k+1}^T \eta_t \mathop{\mathbb E}[F({\boldsymbol x}_t)-F({\boldsymbol x}_{T-k})] =\sum_{t=T-k}^T \eta_t \mathop{\mathbb E}[F({\boldsymbol x}_t)-F({\boldsymbol x}_{T-k})] \leq \frac{1}{2}\sum_{t=T-k}^T \eta^2_t \mathop{\mathbb E}[\|{\boldsymbol g}_t\|^2_2]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3DT-k%2B1%7D%5ET+%5Ceta_t+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29-F%28%7B%5Cboldsymbol+x%7D_%7BT-k%7D%29%5D+%3D%5Csum_%7Bt%3DT-k%7D%5ET+%5Ceta_t+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_t%29-F%28%7B%5Cboldsymbol+x%7D_%7BT-k%7D%29%5D+%5Cleq+%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bt%3DT-k%7D%5ET+%5Ceta%5E2_t+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C%5E2_2%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Putting all together, we have the stated bound.

There are a couple of nice tricks in the proof that might be interesting to study carefully. First, we use the fact that one-step inequality in (1) holds for any 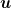



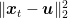
Now we have all the ingredients and we only have to substitute a particular choice of the learning rate.
Corollary 3. Assume
,
and
. Then, we have
![\displaystyle \mathop{\mathbb E}[F({\boldsymbol x}_T)]-F({\boldsymbol x}^\star) \leq \frac{1}{2\sqrt{T}} \left(\frac{\|{\boldsymbol x}^\star-{\boldsymbol x}_1\|^2}{\alpha} + \alpha (\ln T+1)\right) + \frac{3\alpha}{2} \frac{1+\log(T-1)}{\sqrt{T}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_T%29%5D-F%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29+%5Cleq+%5Cfrac%7B1%7D%7B2%5Csqrt%7BT%7D%7D+%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D%5E%5Cstar-%7B%5Cboldsymbol+x%7D_1%5C%7C%5E2%7D%7B%5Calpha%7D+%2B+%5Calpha+%28%5Cln+T%2B1%29%5Cright%29+%2B+%5Cfrac%7B3%5Calpha%7D%7B2%7D+%5Cfrac%7B1%2B%5Clog%28T-1%29%7D%7B%5Csqrt%7BT%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: First, observe that

Now, considering the last term in (3), we have
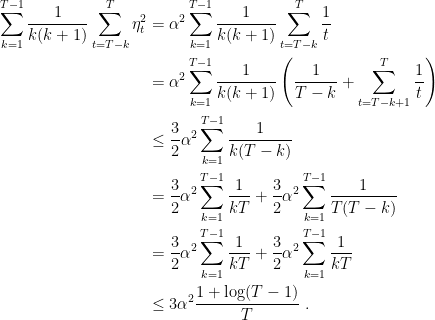
Using (2) and dividing by 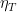
Note that the above proof works similarly if 
4. History Bits
The first finite-time convergence proof for the last iterate of SGD is from (Zhang, T., 2004), where he considered the constant learning rate case. It was later extended in (Shamir, O. and Zhang, T., 2013) for time-varying learning rates but only for bounded domains. The convergence rate for the weighted average in unbounded domains is from (Zhang, T., 2004). The observation that the weighted average is not needed and the plain average works equally well for non-increasing learning rates is from (X. Li and F. Orabona, 2019), where we needed it for the particular case of AdaGrad learning rates. The idea of analyzing SGD without dividing by the learning rate is by (Zhang, T., 2004). Lemma 1 is new but actually hidden in the the convergence proof of the last iterate of SGD with linear predictors and square losses in (Lin, J. and Rosasco, L. and Zhou, D.-X., 2016), that in turn is based on the one in (Shamir, O. and Zhang, T., 2013). As far as I know, Corollary 3 is new, but please let me know if you happen to know a reference for it! It is possible to remove the logarithmic term in the bound using a different learning rate, but the proof is only for bounded domains (Jain, P. and Nagaraj, D. and Netrapalli, P., 2019).
5. Exercises
Exercise 1. Generalize the above proofs to the Stochastic Mirror Descent case.
Exercise 2. Remove the assumption of expected bounded stochastic subgradients and instead assume that
-smooth, i.e., has
6. Appendix
Proof of Lemma 1: Define 

that implies

Now, from the definition of 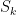

that implies
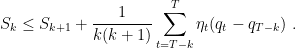
Unrolling the inequality, we have
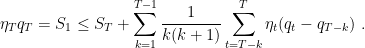
Using the definition of 


EDIT: inspired by the discussion on Twitter, I added exercise 2.
LikeLike
Very interesting! My first guess for why the last iterate should converge was that $x_T$ is close to $\bar x_T$. However for a simple one dimensional case where all $g_t = 1$, it can be shown that $x_T- \bar x_T = O(\sqrt(T))$.
LikeLike
Interesting! Can you sketch your construction?
LikeLike
I was thinking $x_T = -\sum_{t=1}^{T-1} \alpha g_t/\sqrt{t}$. Then we get $\bar x_T =-1/T\sum_{k=1}^T\sum_{t=1}^{k-1} \alpha g_t/\sqrt{t}$. Now by assuming $g_t=1$ and simplifying $x_t- \bar x_T$ it is easy to show that it is of the order $O(\sqrt{T})$. Though the problem is the loss functions seems unbounded and $\bar x_t$ actually doesn’t converge! So I was totally wrong.
LikeLiked by 1 person