I am back! I finally found some spare time to write something interesting.
A lot of people told me that they like this blog because I present “new” results. Sometimes the results I present are so “new” that people cite me in papers. This makes me happy: Not only you learned something reading my posts, but you also found a use for them! So, this post is again one of these things that many people will think as “new” but in reality I had it in 2018 and I never knew what to do with it. The result this time is obvious from Levy (2017). But in order to see it, you must know online learning. Now, classic optimization people usually do not know online learning. This means that if you know classic optimization, I bet you probably did not know about this result: Let me know if I was wrong!
This time I will try an experiment: I will publish this post here and in a few days I’ll submit a slightly more serious version to arXiv. So, in case you need it, this time you’ll have an arXiv paper to cite.
EDIT: This actually took few months to do it, but it is now on Arxiv.
1. Introduction
Here, I present some very easy results about the use of normalized gradients. Nothing is really new, there is only one bit about adapting to Hölder smoothness using a new inequality, but the core idea is very well-known from Levy (2017), at least to online learning people. The main result is the ability to adapt to Hölder smoothness without knowing the Hölder exponent essentially for free using normalized gradients. The reduction is very generic, so we will apply it to OGD, Dual Averaging, and parameter-free algorithms. But first I’ll show that a similar rate can be obtained by AdaGrad-norm stepsizes, that is an even easier proof.
Let’s first describe Hölder smoothness.
2. Hölder smoothness
For the following definition, see Nesterov (2015).
Definition 1. Let
and define the class of
-Hölder smooth functions with respect to
the ones that satisfy
where
is the dual norm of

This definition is useful because it allows us to capture a wide range of function in a unified way. It is a generalization of smoothness and Lipschitzness, in fact for smooth functions 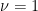
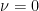
We can prove the following well-known result for this class of functions, see, for example, Nesterov (2015).
Theorem 2. Let
with
-Hölder continuous gradients with respect to
and
, we have

Proof:

Therefore,


I could not find the following Corollary in any paper, but I am sure this is also well-known.
Cor 3. Let
. Then, for any


Proof: Let 




So, for any 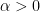

With the optimal setting of 

Reordering, we have the stated bound.
3. AdaGrad-Norm Adapts to Hölder Smoothness
Our objective is to minimize a convex Hölder smooth function 

It should be easy to see that the optimal learning rate 




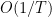

From this reasoning, you should see that the optimal rate that gradient descent (without acceleration) can achieve on Hölder smooth functions depend on 
Now, our objective is simple: We want to achieve the above rate without knowing
Let’s now warm up a bit considering the so-called AdaGrad-norm stepsizes, that is 
It is known that gradient descent with the AdaGrad-norm stepsizes gets a faster rate on smooth function, that is
We will consider the Follow-The-Regularized-Leader (FTRL) with linearized losses (or as it is know in the optimization community Dual Averaging (DA)) version of AdaGrad to have a simpler proof, but the analysis in the gradient descent case is also possible and easy (hint: consider the guarantee on 

where 

From its known guarantee, we have

Now, we want to transform the terms 


Setting 


If the function 
![\displaystyle \begin{aligned} \sum_{t=1}^T (f({\boldsymbol x}_t)-f({\boldsymbol x}^\star)) &\leq \left(\frac{\|{\boldsymbol x}_1-{\boldsymbol x}^\star\|_2^2}{2\alpha} + \alpha\right) \sqrt{G^2+\sum_{t=1}^T \|{\boldsymbol g}_t\|_2^2} \\ &\leq \left(\frac{\|{\boldsymbol x}_1-{\boldsymbol x}^\star\|_2^2}{2\alpha} + \alpha\right) \left(G+T^\frac{-\nu+1}{2(\nu+1)}\left(\sum_{t=1}^T \|{\boldsymbol g}_t\|_2^{1+\frac{1}{\nu}}\right)^\frac{\nu}{\nu+1}\right) \\ &\leq \left(\frac{\|{\boldsymbol x}_1-{\boldsymbol x}^\star\|_2^2}{2\alpha} + \alpha\right) \left(G+T^\frac{-\nu+1}{2(\nu+1)}\left[(1/\nu+1)L_\nu^{1/\nu} \sum_{t=1}^T (f({\boldsymbol x}_t)-f({\boldsymbol x}^\star)) \right]^\frac{\nu}{\nu+1}\right)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%28f%28%7B%5Cboldsymbol+x%7D_t%29-f%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%29+%26%5Cleq+%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+x%7D%5E%5Cstar%5C%7C_2%5E2%7D%7B2%5Calpha%7D+%2B+%5Calpha%5Cright%29+%5Csqrt%7BG%5E2%2B%5Csum_%7Bt%3D1%7D%5ET+%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_2%5E2%7D+%5C%5C+%26%5Cleq+%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+x%7D%5E%5Cstar%5C%7C_2%5E2%7D%7B2%5Calpha%7D+%2B+%5Calpha%5Cright%29+%5Cleft%28G%2BT%5E%5Cfrac%7B-%5Cnu%2B1%7D%7B2%28%5Cnu%2B1%29%7D%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_2%5E%7B1%2B%5Cfrac%7B1%7D%7B%5Cnu%7D%7D%5Cright%29%5E%5Cfrac%7B%5Cnu%7D%7B%5Cnu%2B1%7D%5Cright%29+%5C%5C+%26%5Cleq+%5Cleft%28%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+x%7D%5E%5Cstar%5C%7C_2%5E2%7D%7B2%5Calpha%7D+%2B+%5Calpha%5Cright%29+%5Cleft%28G%2BT%5E%5Cfrac%7B-%5Cnu%2B1%7D%7B2%28%5Cnu%2B1%29%7D%5Cleft%5B%281%2F%5Cnu%2B1%29L_%5Cnu%5E%7B1%2F%5Cnu%7D+%5Csum_%7Bt%3D1%7D%5ET+%28f%28%7B%5Cboldsymbol+x%7D_t%29-f%28%7B%5Cboldsymbol+x%7D%5E%5Cstar%29%29+%5Cright%5D%5E%5Cfrac%7B%5Cnu%7D%7B%5Cnu%2B1%7D%5Cright%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Assuming the term

The online-to-batch conversion completes the convergence rate:

where 

So, we obtained that AdaGrad-norm stepsizes will give a
In the next section, we see that we can generalize this idea a bit more and we can get rid of the knowledge of 
4. Adapting to Local Hölder Smoothness with Normalized Gradients
AdaGrad-norm stepsizes are nice, but they are a bit restrictive. Can I use different stepsizes in a different first-order optimization algorithm and still get the same rate?
It turns out this is very simple: Just use normalized gradients and evaluate the function on a weighted average of the iterates. That’s it. Moreover, the result is stronger: here we will adapt to a certain notion of “local” Hölder smoothness. And the proof is particularly simple too! Moreover, it is a black-box reduction: you can use it with any online optimization algorithm that guarantees a regret. No need to know what the online optimization algorithm does! This procedure is summarized in Algorithm 1.

Let’s see the details in the following theorem.
Theorem 4. Suppose you have an online linear optimization algorithm
that guarantees
when fed with linear losses
where
for all
, for some function
and any
. Let
such that for all
Then, Algorithm 1 guarantees



So, in words, the algorithm does not need to know anything about the function 
![{\alpha^\nu\leq \left(1+\frac{1}{\nu}\right)^\nu\in[1,2]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha%5E%5Cnu%5Cleq+%5Cleft%281%2B%5Cfrac%7B1%7D%7B%5Cnu%7D%5Cright%29%5E%5Cnu%5Cin%5B1%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

To prove it, we will use the HM-GM-AM inequality
Lemma 5. Let
positive numbers. Then, we have

We can now prove our main Theorem. The proof is immediate from the results in Levy (2017), but kind of hidden. Again, if you know online learning and you read the paper, I assure you the following proof will be evident, at least for
Proof: In the case that 
For shortness of notation, denote by 


Now, from the definition

Hence, we have

where we used Lemma 5 in the second inequality, Corollary 3 in the third one, the assumption on the online learning algorithm in the last one.
We now consider some examples.
Online Gradient Descent Consider online gradient descent with constant learning rate 

Then, from very standard online learning results, we have immediately have

So, using Theorem 4 and assuming the function

So, we get
But we can do even better! From (1), using the fact that 

Hence, the iterates are bounded (nope, this is not new, this is also well-known, see for example Xiao (2010, Corollary 2.b)). This means that the Hölder smoothness only have to hold on a ball around the initial point. So, this result generalizes the one in Mishchenko and Malitsky (2020) because they only consider the usual notion of smoothness.
FTRL/DA With enough math, we could even prove the same thing for OGD a time-varying learning rate. However, given that I am not religious about OGD, we can do it in a much simpler way using FTRL with linearized losses / DA.
In this case, the update is

As before, proving that the iterates are bounded is very easy (reason as above and use Exercise 7.2 in Orabona (2019)). So, using the known guarantee for FTRL and reasoning as above, we obtain

but this time we don’t need to know 
Parameter-free version In the above bounds, the optimal value of 
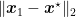
Remark 1. “Parameter-free” is a generic adjective but it is also a technical word like “universal”. So, it might be the case that I do not use it in the same you use it!
In my subfield, we call an optimization algorithm “parameter-free” if it can achieve the convergence rate (in expectation or high probability)
uniformly over all convex functions with bounded stochastic subgradients, with

However, the main disadvantage of parameter-free algorithms is the need to have bounded gradients. But normalized gradients are always bounded! In particular, consider again the Euclidean case and just use the parameter-free KT algorithm with normalized gradients:

In case you think that this is a weird algorithm, think again: it is very difficult to beat this algorithm, because it is designed exactly for the case in which all the vectors have norm equal to 1! Again, using Theorem 4 and the regret guarantee of KT, we immediately obtain

The advantage of this bound over the ones above is that this has almost the optimal dependency on 

I can hear at least one party pooper saying that this bound is not optimal in 


This is a beautiful guarantee: the algorithms adapts to
But wait, there is also another way! Just scale each gradient 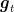

Note that in this case the bounded iterates are more delicate, but it can still be done using a parameter-free algorithm based on FTRL and reason as in Orabona and Pál (2021). So, yeah, everything solved.
5. Open Problems
That’s it! Easy, right? Two different reductions, rescaled gradients by AdaGrad-norm stepsizes and normalized gradients, to obtain adaptive rates. Also, if you know classic optimization and you don’t know online learning, I hope the short and elegant proofs above will convince you to study more about online learning: I happen to have written an (almost) complete draft book on online learning 😉
As I wrote above, everything was (essentially) known. So, what remains to be done? For sure the stochastic case. Indeed, the deterministic case is too easy to be interesting. In fact, Levy (2017) has an entire section about adaptive minibatches to use normalized gradients (minus the adaptation to
Another interesting direction is to obtain accelerated rates using parameter-free algorithms: it is still deterministic but I don’t know ways to do it (unless I am missing some very recent result).
6. History Bits
AdaGrad-norm stepsizes were proposed by Streeter and McMahan (2010) and widely used in the online learning community (e.g., Orabona and Pál, 2015) before being rediscovered in the stochastic optimization one by… us! (Li and Orabona, 2019) (yep, we were the first ones, check the arXiv date).
The idea of using normalized gradients goes back at least to Nesterov (2004, Section 3.2.3), where he gets adaptation to the Lipschitz constant. Reading his proof, it should be immediate to realize that the same trick works essentially for any algorithm. The majority of this blog post comes from reading and truly enjoying the underappreciated paper by Levy (2017). Levy (2017) presents his result for a particular algorithm, but if you look at his proof you should see that it applies to any online linear optimization algorithm, as I did. I am not sure where I took the trick about the geometric mean to adapt to
Some weaker and less general results appear in other papers too. Mishchenko and Malitsky (2020) proved that one can obtain 
The adaptation to smoothness in the parameter-free case by rescaling the gradients of a parameter-free algorithm (and actually of any FTRL/DA algorithm) by 



The first parameter-free algorithm to prove bounded iterates (with probability one) was in Orabona and Pál (2021) but without a precise bound. Ivgi, Hinder, and Carmon (2023) were the first one to design a parameter-free algorithm where 


Acknowledgments
Thanks to Yair Carmon, Benjamin Grimmer, Kfir Levy, Mingrui Liu, Nicolas Loizou, Yura Malitsky, and Aryan Mokthari for feedback and comments on a preliminary version of this blog post.
Versions
1.0: initial post
1.1: Fixed missing

great post as usual. I wonder if as for gradient descent, the theory can be tightened if we use the equivalent of
f(x) \leq f(y) + \langle \nabla f(x), x – y\rangle – \frac{1}{2 L}\|\nabla f(x) – \nabla f(y)\|^2
for Holder smoothness the same way that using the above instead of the more traditional L-smoothness and convexity separately allows to improve the convergence rate of gradient descent (as done for example in https://link.springer.com/article/10.1007/s10107-022-01899-0)
LikeLiked by 1 person
Thanks Fabian! Also, thanks for sharing that paper, I didn’t know about it, very cool results!
I would guess it is probably possible to use similar methods in the Hölder case. But if we want something that adapts to the smoothness, we should probably not start from the descent lemma, because we need something that works in the Lipschitz case too. Anyway, it would be interesting to see if the refined inequalities in that paper could find applications in other settings too.
LikeLike
…or at least I would not know how to start from the descent lemma to design adaptive strategies 🙂
LikeLike