In this post, we will explain how Gradient Descent (GD) works and why it can converge very slowly.
The simplest first-order optimization algorithm is Gradient Descent. It is used to minimize a convex differentiable function over 


Last time we saw that Subgradient Descent (SD) is not a descent method. What about GD? GD with an appropriate choice of the stepsizes is a descent method, that is 
Condition Number. To better understand this concept we will use a nice property of gradients, often overlooked. First, let’s define what is the level set of a function, that is the set of all the points 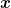

Definition 1 The
-level set of a function
.
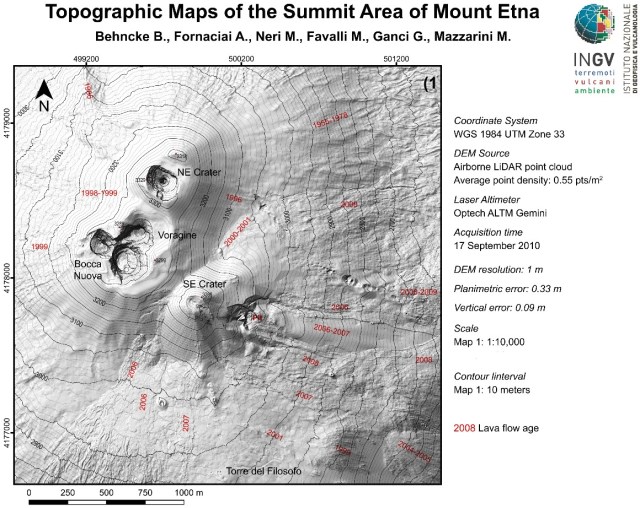
To visualize the level set, consider the two-dimensional example of a topographic map in Figure 1. The black lines are exactly the level sets corresponding to different values of the 2-d function, that in this case are just the altitudes.
We can now state the following proposition.
Proposition 2 Let
and
. Then,
is orthogonal to the level set
at
We will not prove it, because there is not much to learn from the proof for us.
What does it mean in words? It means that if I draw the level sets of a function, I know immediately in which direction the gradient goes. This is very powerful to develop a geometric intuition of how GD works. For example, if we take even simple convex two-dimensional functions, we can see that the negative gradient does not really point where we would like it to point.
Let’s see an example. Consider the 2-d function 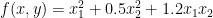
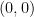


Figure 2. Gradient, level set, and behavior of GD.
The negative gradient in the point 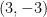

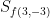
Should we be worried about it? Definitely! The fact that the negative gradient does not point directly to the minimum is exactly what slows down the convergence of GD. In fact, even selecting the step size in the optimal way, i.e. choosing the stepsize that guarantees the maximum decrease of the function at each step, we obtain the behavior in Figure 2. Did you expect the sawtooth path of GD?

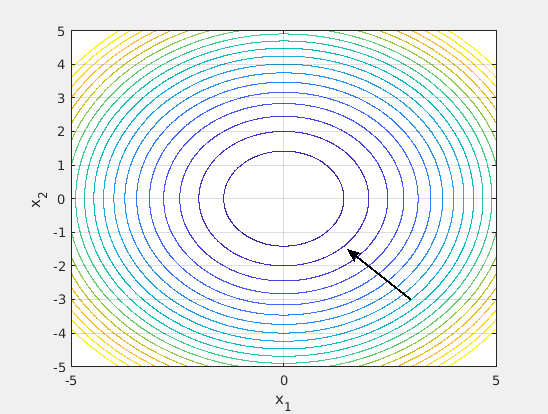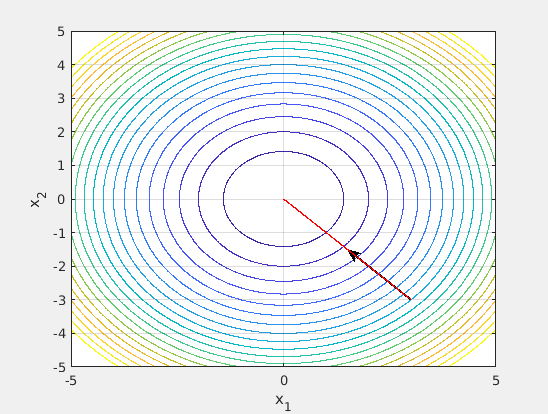
Figure 3. The negative gradient sometimes does point towards the minimum.
On the other hand, if we consider the function 
Can we capture in some way the difference between these two cases? Yes, with the condition number, exactly that obscure concept that Ali Rahimi mentioned in his very controversial talk.
We will define the condition number as the maximum eigenvalue divided by the minimum one of the Hessian of a function. We can show that a high condition number corresponds to a slow convergence, while a low condition number (the minimum is of course 1) corresponds to a fast convergence. Note that for a two-dimensional quadratic function, the maximum and minimum eigenvalue are proportional to the length of the axes of the ellipses formed by the level sets. So, it exactly captures the geometry of our two examples above.
Convergence Guarantee. It is now time for some math and to put all this together and to prove the convergence rate of gradient descent, that we expect to depend on the condition number. The proof works by showing that in each step we decrease the value of the objective function proportional to the norm of the gradient, and that the norm of the gradient itself depends on the suboptimality gap.
Theorem 3 Let
the maximum eigenvalue of its Hessian and
the minimum one. Set
. Then we have

Proof: Denoting by 

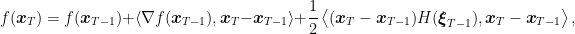
for some 

Note that our definition of the step size 

Now, using again the Taylor expansion, for some 

where in the last inequality we used the elementary inequality 

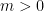
Putting (1) this inequality together and subtracting 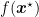
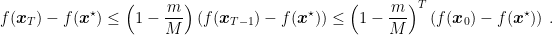

So, we just proved that in GD the suboptimality gap shrinks exponentially fast! And the exponent depends on the condition number. Also, this rate is almost optimal, using acceleration we can depend on the square root of the condition number.
A curiosity: This rate of convergence is called linear, because when you plot the logarithm of the suboptimality with respect to the number of iterations you get a straight line.
How to Choose the Stepsizes for GD in Practice? In the above theorem we assumed the stepsize to be constant and equal to 
So, in order to set the stepsize, the theorem assumes that you know the maximum eigenvalue of the Hessian of the function that you are minimizing. Also, it implicitly assumes the maximum eigenvalue to be bounded. However, the boundedness assumption can be removed, observing that GD strictly decreases the function value, so we have to worry only about the maximum eigenvalue of the Hessian inside the set 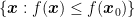
So, is this one another useless theorem? No, because the above theorem also holds if at each time step we select 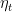
So, we just discovered that GD with a good line search method is a parameter-free algorithm! This is not so surprising: “batch” optimization is a very mature field, where the culture equally weights theoretical and empirical performance. Do you think that optimization people would be happy with algorithms that were not fully automatic? Parameter-free optimization algorithms are actually the norm and nobody would call them “parameter-free”. Instead, they would just say that this is the right way to do. And if you think about it, why would you want an optimization algorithm to have parameters? When is the last time you had to set a learning rate to invert a matrix in MATLAB/Octave/NumPy?
If you wonder why line search algorithms are not common in the machine learning literature, the reason is that we tend to prefer stochastic optimization methods, where the line search becomes non-trivial. Indeed, there are papers on this issue, but it is still an open problem. So, in the stochastic setting, we will have to use different techniques.
Now, we know what is the condition number and we know how it influences the convergence speed. Can we do something to converge faster in the case of functions with a high condition number? Yes, but we have to pay a cost. Intuitively, we could just do a change of coordinate in the examples above, to go from the difficult case to the easy case. What is the optimal transformation? It is the one that makes the new Hessian as close as possible to an identity matrix. And this is exactly what a Netwon’s algorithm does! So, under some smoothness conditions on the objective function, we can expect a Netwon algorithm to have a convergence rate that is independent of the condition number. Indeed, on convex quadratic functions, the Newton’s algorithm will always converge to the minimum in one step. However, we have to pay the computational price of running the Netwon algorithm: calculating the Hessian, inverting it, etc. Of course, we could use quasi-Netwon’s algorithms that approximate the Netwon update to keep the computation complexity low, but that is another story.

Very interesting !
I have nevertheless a lot of difficulties on many points I still don’t get even after spending hours and hours of research.
I had an optimization course saying the gradients are orthogonal to the contour plots, and one gradient direction will also be orthogonal to the next one. I understand why it’s orthogonal to the countour plots. For the orthogonality of the k-th gradient and k+1-th gradients, I saw that the reason was that at the k-th iteration, we have moved in the steepest descent regarding a certain neighborhood. If the next gradient wasn’t orthogonal, it would mean the previous one could have been moved a little bit differently to really be the direction of steepest descent.
I always thought and been told that the opposite of the gradient points towards the minimum when the function is convex but that’s false apparently and I have to thank you for pointing it out with your examples. Even when this minimum is unique, it is not necessarily the case that gradient points towards the min ?
Now what I’m struggling with is that when we are pointing in the direction of the minimum, we have a straight line, and no matter from which angle I look to the problem, how could the iterates of the gradient (k, k+1, etc) be orthogonal now ? They seem to be colinear. A very simple example : x². Derivative is 2x, the direction stay the same because we are, at the first iterate, already pointing towards the minimum so as the direction does not change the iterates of the gradient are not colinear anymore right ? I have the feeling that it is beacause now it’s just a question of magnitude, of the step we are taking towards the min, but gradient has stayed the same in fact, it’s when the iterates are different in termes of direction that there is orthogonality. Am I correct in my intuition ?
(If so I’d like to ask another question but my post is already elaborated haha)
Anyway thanks a lot and best regards
Geoffrey
LikeLike
Hi Geoffrey! The key point is that the property that two consecutive gradients are orthogonal is true only for a learning rate that minimizes the function along the direction of the negative gradient, not for a generic learning rate.
So, in the case that the gradients points exactly towards the minimum, setting the learning rate as the one the minimizes the function in the direction of the update will make you land on the minimum. So, the next gradient will be 0 and the inner product of two consecutive gradients will be 0. Does it make sense?
LikeLike
Hi Franceso,
Thank you for the interesting post and (to me at least) a different perspective on the linear convergence of gradient descent for (strongly) convex functions! I have a question regarding the proof. At the risk of not seeing the obvious, it is not clear to me how equation (2) follows from the preceding derivation and the fact that f(x^*) <= f(x_{t-1} – 1/mnabla f(x_{t-1}))? If anything, it seems to me that in order for (2) to hold, we would need the opposite inequality, i.e., f(x^*) >= f(x_{t-1} – 1/mnabla f(x_{t-1})). Thank you in advance!
Best,
Aleksandar
LikeLike
You are right, that part was wrong! I don’t know what I was thinking. I fixed it, please let me know if it seems good now.
Thanks,
Francesco
LikeLike
Everything seems correct, maybe just in the first two inequalities there should be a factor of m/2 instead of 1/(2m), but that’s a minor typo. Thank you for the clarification and a neat proof of linear convergence of GD!
LikeLike
Fixed, thanks!
LikeLike