This time we will introduce the Weighted Average Algorithm (WAA). I will do it my way: I am allergic to present for each algorithm a different analysis! From my blog it should be clear that we only have two main algorithms in online learning: OMD and FTRL. So, 99% of the online algorithms are instantiations of one or the other. In this case, I will show that WAA is nothing else than FTRL on distributions.
Next time, I will introduce the Aggregating Algorithm (AA) as a variant of the WAA.
1. Follow-the-Regularized-Leader with Distributions
Our analysis of the WAA will be based on a generalization of the FTRL algorithm with the entropic regularizer, to work with distributions with infinite support, either countable or continuous.
Let 
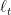


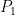


For some set of distributions 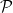

![{f_t(P):=\mathop{\mathbb E}_{{\boldsymbol x} \sim P}[\ell_t({\boldsymbol x})]}](https://s0.wp.com/latex.php?latex=%7Bf_t%28P%29%3A%3D%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P%7D%5B%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Note that the duality pairing is bi-linear but not symmetric, so it should not be confused with the inner product. Yet, it reduces to the inner product in some cases, for example, when 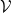

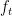

The above notation will greatly facilitate the generalization of FTRL to infinite distributions. Let’s use FTRL with regularizers 

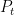

It is easy to see that the FTRL equality works even in this setting, so we have that
![\displaystyle \left\langle\sum_{t=1}^T - \ell_t,Q\right\rangle = \psi_{T+1}(Q) - \min_{M \in \mathcal{P}} \ \psi_{1}(M) + \sum_{t=1}^T [F_t(P_t) - F_{t+1}(P_{t+1}) ] + F_{T+1}(P_{T+1}) - F_{T+1}(Q), \ \forall Q \in \mathcal{P},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5Clangle%5Csum_%7Bt%3D1%7D%5ET+-+%5Cell_t%2CQ%5Cright%5Crangle+%3D+%5Cpsi_%7BT%2B1%7D%28Q%29+-+%5Cmin_%7BM+%5Cin+%5Cmathcal%7BP%7D%7D+%5C+%5Cpsi_%7B1%7D%28M%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5BF_t%28P_t%29+-+F_%7Bt%2B1%7D%28P_%7Bt%2B1%7D%29+%5D+%2B+F_%7BT%2B1%7D%28P_%7BT%2B1%7D%29+-+F_%7BT%2B1%7D%28Q%29%2C+%5C+%5Cforall+Q+%5Cin+%5Cmathcal%7BP%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where we removed the loss term of the algorithm on both sides. Define ![{{\boldsymbol x}_t=\mathop{\mathbb E}_{{\boldsymbol x} \sim P_t}[{\boldsymbol x}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+x%7D_t%3D%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_t%7D%5B%7B%5Cboldsymbol+x%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \begin{aligned} \sum_{t=1}^T &\ell_t( {\boldsymbol x}_t) - \left\langle\sum_{t=1}^T \ell_t,Q\right\rangle \\ &= \psi_{T+1}(Q) - \min_{M \in \mathcal{P}} \ \psi_{1}(M) + \sum_{t=1}^T [F_t(P_t) - F_{t+1}(P_{t+1}) + \ell_t( {\boldsymbol x}_t)] + F_{T+1}(P_{T+1}) - F_{T+1}(Q) & (1) \\\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%26%5Cell_t%28+%7B%5Cboldsymbol+x%7D_t%29+-+%5Cleft%5Clangle%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%2CQ%5Cright%5Crangle+%5C%5C+%26%3D+%5Cpsi_%7BT%2B1%7D%28Q%29+-+%5Cmin_%7BM+%5Cin+%5Cmathcal%7BP%7D%7D+%5C+%5Cpsi_%7B1%7D%28M%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5BF_t%28P_t%29+-+F_%7Bt%2B1%7D%28P_%7Bt%2B1%7D%29+%2B+%5Cell_t%28+%7B%5Cboldsymbol+x%7D_t%29%5D+%2B+F_%7BT%2B1%7D%28P_%7BT%2B1%7D%29+-+F_%7BT%2B1%7D%28Q%29+%26+%281%29+%5C%5C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The above equality will be the starting point to analyze WAA and AA.
2. The Weighted Average Algorithm

We consider FTRL for distributions described in the previous section. As usual, we will denote by 





We set 
![{\psi_t:P\rightarrow \lambda_t \text{KL}(P||P_1)=\lambda_t \mathop{\mathbb E}_{{\boldsymbol x} \sim P}[\ln\frac{P(\mathrm{d} {\boldsymbol x})}{P_1(\mathrm{d} {\boldsymbol x})}]}](https://s0.wp.com/latex.php?latex=%7B%5Cpsi_t%3AP%5Crightarrow+%5Clambda_t+%5Ctext%7BKL%7D%28P%7C%7CP_1%29%3D%5Clambda_t+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P%7D%5B%5Cln%5Cfrac%7BP%28%5Cmathrm%7Bd%7D+%7B%5Cboldsymbol+x%7D%29%7D%7BP_1%28%5Cmathrm%7Bd%7D+%7B%5Cboldsymbol+x%7D%29%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

WAA is stated in Algorithm 1. Essentially, WAA predicts with a weighted average of predictions—hence the name of the algorithm—where the weights are proportional to the negative exponential of the cumulative losses of each predictor.
Remark 1. Note that if
is such that
, then
for all
, then
for all
is automatically satisfied.
Remark 2. If the losses are convex, predicting with the average instead of sampling makes sense because by Jensen’s inequality, we have
![\displaystyle \ell_t({\boldsymbol x}_t) \leq \mathop{\mathbb E}_{{\boldsymbol x} \sim P_t} [\ell_t({\boldsymbol x})]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+%5Cleq+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_t%7D+%5B%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Next, we will dig deeper in the concept of exp-concavity that will be used as a key assumption on the losses.
2.1. Convex Analysis Bits: Exp-concavity
Definition 1. Let
and
. A function
is called
‑exp‑concave if
is a concave function on

Proposition 2. Let
. If
is
is
-exp-concave for any
.
Proof: Observe that 



Proposition 3. Assume
is
where
and
. Then,
Proof: Since 
The next proposition shows that exp-concavity is a stronger property than convexity.
Proof: Let 



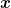

![{t\in[0,1]}](https://s0.wp.com/latex.php?latex=%7Bt%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

For the positive numbers 

Combining the two inequalities,

Taking 

so
We can also characterize the exp-concavity in terms of the Hessian of a twice differentiable function.
Theorem 5. Let
twice-differentiable. Then, f is

Proof: The concavity of 

Let’s compute 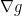


The Hessian is

Re‑ordering,

Since 


Example 1. Consider
,
, and
, where
. We have
and
Using Theorem 5,
Hence, we have that
.



Finally, we show that exp-concavity holds on the entire
Proposition 6. Let
Proof: Denote by 



Hence, we have

Since 

Remark 3. The previous result and the fact that exp-concave functions are often used only on bounded domains might induce someone to think that exp-concave function only exists on bounded domains. This is not true: There exists exp-concave
, where
is not bounded. For example, let
and
that is 1-exp-concave.
2.2. Analysis of WAA
We now state the regret guarantee for WAA.
Theorem 7. Assume that
for all
Moreover, if
, we also have
![\displaystyle \sum_{t=1}^T \ell_t( {\boldsymbol x}_t) \leq \mathop{\mathbb E}_{{\boldsymbol x} \sim Q}\left[\sum_{t=1}^T \ell_t({\boldsymbol x})\right] + \lambda_T \text{KL}(Q||P_1), \quad \forall Q \in \Delta_\mu(\mathcal{V})~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28+%7B%5Cboldsymbol+x%7D_t%29+%5Cleq+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%5D+%2B+%5Clambda_T+%5Ctext%7BKL%7D%28Q%7C%7CP_1%29%2C+%5Cquad+%5Cforall+Q+%5Cin+%5CDelta_%5Cmu%28%5Cmathcal%7BV%7D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \sum_{t=1}^T \ell_t( {\boldsymbol x}_t) \leq -\lambda_T \ln \mathop{\mathbb E}_{{\boldsymbol x} \sim P_1}\left[ \exp\left(-\frac{1}{\lambda_T} \sum_{t=1}^T \ell_t({\boldsymbol x})\right)\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28+%7B%5Cboldsymbol+x%7D_t%29+%5Cleq+-%5Clambda_T+%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_1%7D%5Cleft%5B+%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda_T%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We start from (1).
First of all, observe that it holds that (proof left as an exercise)
![\displaystyle \label{eq:aa_alternate_term} \inf_{P} \ \langle f, P\rangle + \lambda \text{KL}(P,Q) = - \lambda \ln \mathop{\mathbb E}_{{\boldsymbol x} \sim Q}\left[\exp\left(- \frac{1}{\lambda} f({\boldsymbol x})\right)\right]~. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Aaa_alternate_term%7D+%5Cinf_%7BP%7D+%5C+%5Clangle+f%2C+P%5Crangle+%2B+%5Clambda+%5Ctext%7BKL%7D%28P%2CQ%29+%3D+-+%5Clambda+%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D%5Cleft%5B%5Cexp%5Cleft%28-+%5Cfrac%7B1%7D%7B%5Clambda%7D+f%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
Given that 


Assuming 
![\displaystyle \begin{aligned} F_t(P_t) - F_{t+1}(P_{t+1}) &\leq - \langle\ell_t, P_{t+1}\rangle-B_{F_t}(P_{t+1};P_t) = - \langle \ell_t,P_{t+1}\rangle-B_{\psi_t}(P_{t+1};P_t) \\ &\leq \max_{P} \ - \langle\ell_t,P\rangle-B_{\psi_t}(P;P_t) = \lambda_t\ln \mathop{\mathbb E}_{{\boldsymbol x} \sim P_{t}} \left[\exp\left(-\frac{1}{\lambda_t} \ell_t({\boldsymbol x})\right)\right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+F_t%28P_t%29+-+F_%7Bt%2B1%7D%28P_%7Bt%2B1%7D%29+%26%5Cleq+-+%5Clangle%5Cell_t%2C+P_%7Bt%2B1%7D%5Crangle-B_%7BF_t%7D%28P_%7Bt%2B1%7D%3BP_t%29+%3D+-+%5Clangle+%5Cell_t%2CP_%7Bt%2B1%7D%5Crangle-B_%7B%5Cpsi_t%7D%28P_%7Bt%2B1%7D%3BP_t%29+%5C%5C+%26%5Cleq+%5Cmax_%7BP%7D+%5C+-+%5Clangle%5Cell_t%2CP%5Crangle-B_%7B%5Cpsi_t%7D%28P%3BP_t%29+%3D+%5Clambda_t%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_%7Bt%7D%7D+%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda_t%7D+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where in the first equality we used the fact that the terms with the losses are linear with respect to the distribution, and in the last equality we used (2).
Finally, if
![\displaystyle \lambda_t\ln \mathop{\mathbb E}_{{\boldsymbol x} \sim P_t} \left[\exp\left(-\frac{1}{\lambda_t} \ell_t({\boldsymbol x})\right)\right] + \ell_t\left({\boldsymbol x}_t\right) =\lambda_t\ln \mathop{\mathbb E}_{{\boldsymbol x} \sim P_t} \left[\exp\left(-\frac{1}{\lambda_t} \ell_t({\boldsymbol x})\right)\right] + \ell_t\left(\mathop{\mathbb E}_{{\boldsymbol x} \sim P_t}[{\boldsymbol x}]\right) \leq0,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clambda_t%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_t%7D+%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda_t%7D+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D+%2B+%5Cell_t%5Cleft%28%7B%5Cboldsymbol+x%7D_t%5Cright%29+%3D%5Clambda_t%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_t%7D+%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda_t%7D+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D+%2B+%5Cell_t%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+P_t%7D%5B%7B%5Cboldsymbol+x%7D%5D%5Cright%29+%5Cleq0%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
for all 

The second bound is obtained by choosing 
![{\mathop{\mathbb E}_{{\boldsymbol x} \sim Q}\left[\sum_{t=1}^T \ell_t({\boldsymbol x})\right] + \lambda_T \text{KL}(Q||P_1)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%5D+%2B+%5Clambda_T+%5Ctext%7BKL%7D%28Q%7C%7CP_1%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
So, the WAA algorithm has the surprising property to have a \emph{constant} regret on exp-concave losses with respect to a stochastic competitor.
Unfortunately, the update in the WAA has not a closed formula. In fact, it requires the numerical evaluation of the expectation. However, if the distribution is discrete we can always calculate the prediction.
Example 2. As a practical example, consider the case that
is composed by
vectors in
. In this case, we have that

We have proved an upper bound to the regret of WAA that uses a randomized comparator, that is, ![{\mathop{\mathbb E}_{{\boldsymbol x} \sim Q}\left[\sum_{t=1}^T \ell_t({\boldsymbol x})\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 8. Assume that
. Then, Algorithm 2 satisfies
![\displaystyle \label{eq:waa_uniform} \sum_{t=1}^T (\ell_t({\boldsymbol x}_t) - \ell_t({\boldsymbol u})) \leq \frac{d}{\alpha} \left[1+\ln(T/d+1)\right], \ \forall {\boldsymbol u} \in \mathcal{V}~. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Awaa_uniform%7D+%5Csum_%7Bt%3D1%7D%5ET+%28%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+-+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29%29+%5Cleq+%5Cfrac%7Bd%7D%7B%5Calpha%7D+%5Cleft%5B1%2B%5Cln%28T%2Fd%2B1%29%5Cright%5D%2C+%5C+%5Cforall+%7B%5Cboldsymbol+u%7D+%5Cin+%5Cmathcal%7BV%7D%7E.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Fix 




By the exp-concavity of


Hence, we have for any

that implies
![\displaystyle \sum_{t=1}^T \mathop{\mathbb E}_{{\boldsymbol x} \sim Q} [\ell_t({\boldsymbol x})] \leq \frac{d}{\alpha}+ \sum_{t=1}^T \ell_t({\boldsymbol u})~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D+%5B%5Cell_t%28%7B%5Cboldsymbol+x%7D%29%5D+%5Cleq+%5Cfrac%7Bd%7D%7B%5Calpha%7D%2B+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Moreover, the KL term becomes

Given that

because
Using Theorem 7 and putting all together, we have the stated bound.
2.3. ONS and OSD as instantiations of WAA
In this section, we show that WAA is more general than one might think. In fact, we will show that it can be equivalent to online subgradient descent and to the Online Newton Step.
Here, we will set 



The losses we use are 

where

and 

However,

that is, the solution of FTRL with regularizer 



Hence, we have the following cases:
- For exp-concave losses, we recover the regret upper bound of the ONS algorithm.
- For convex losses, we have
. Hence, we have
If in addition
, we have
- For
, we have
. Hence, we can set
and
to have



In the next theorem, we also show that the bound in Theorem 7 is powerful enough to capture all the cases above.
Theorem 9. Let
and
are arbitrary for all
, where
. Then, we have
where
for all

Proof: Select 

Observe that the quadratic nature of the losses allows us to easily go from a stochastic to a deterministic competitor:
![\displaystyle \mathop{\mathbb E}_{{\boldsymbol x} \sim Q}[\hat{\ell}_t({\boldsymbol x})] = \ell_t({\boldsymbol x}_t)+\langle {\boldsymbol g}_t, {\boldsymbol u}-{\boldsymbol x}_t\rangle + \frac12\text{Tr}[{\boldsymbol C} {\boldsymbol M}_t]+ \frac12 \|{\boldsymbol u}-{\boldsymbol x}_t\|^2_{{\boldsymbol M}_t} = \hat{\ell}_t({\boldsymbol u})+\frac12 \text{Tr}[{\boldsymbol C} {\boldsymbol M}_t]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D+%5Csim+Q%7D%5B%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29%5D+%3D+%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29%2B%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_t%5Crangle+%2B+%5Cfrac12%5Ctext%7BTr%7D%5B%7B%5Cboldsymbol+C%7D+%7B%5Cboldsymbol+M%7D_t%5D%2B+%5Cfrac12+%5C%7C%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_t%5C%7C%5E2_%7B%7B%5Cboldsymbol+M%7D_t%7D+%3D+%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+u%7D%29%2B%5Cfrac12+%5Ctext%7BTr%7D%5B%7B%5Cboldsymbol+C%7D+%7B%5Cboldsymbol+M%7D_t%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, we have
![\displaystyle \sum_{t=1}^T \left(\ell_t({\boldsymbol x}_t)-\ell_t({\boldsymbol u})\right) \leq \sum_{t=1}^T \left(\hat{\ell}_t({\boldsymbol x}_t)-\hat{\ell}_t({\boldsymbol u})\right) = \sum_{t=1}^T \left(\hat{\ell}_t({\boldsymbol x}_t)-\mathop{\mathbb E}_{{\boldsymbol x}\sim Q}[\hat{\ell}_t({\boldsymbol x})]\right)+\frac12 \text{Tr}\left({\boldsymbol C} \sum_{t=1}^T {\boldsymbol M}_t\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29-%5Cell_t%28%7B%5Cboldsymbol+u%7D%29%5Cright%29+%5Cleq+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29-%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+u%7D%29%5Cright%29+%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29-%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+Q%7D%5B%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29%5D%5Cright%29%2B%5Cfrac12+%5Ctext%7BTr%7D%5Cleft%28%7B%5Cboldsymbol+C%7D+%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+M%7D_t%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
From (1), we have
![\displaystyle \sum_{t=1}^T \left(\hat{\ell}_t({\boldsymbol x}_t)-\mathop{\mathbb E}_{{\boldsymbol x}\sim Q}[\hat{\ell}_t({\boldsymbol x})]\right) \leq \lambda \text{KL}(Q||P_1) + \sum_{t=1}^T \lambda \ln \mathop{\mathbb E}_{{\boldsymbol x}\sim P_t}\left[\exp\left(-\frac{1}{\lambda}\left( \hat{\ell}_t({\boldsymbol x})-\hat{\ell}_t({\boldsymbol x}_t)\right)\right)\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29-%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+Q%7D%5B%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29%5D%5Cright%29+%5Cleq+%5Clambda+%5Ctext%7BKL%7D%28Q%7C%7CP_1%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5Clambda+%5Cln+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+P_t%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda%7D%5Cleft%28+%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29-%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29%5Cright%29%5Cright%29%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
From the update rule, we have
![\displaystyle \begin{aligned} \lambda \ln\mathop{\mathbb E}_{{\boldsymbol x}\sim P_t}\left[\exp\left(-\frac{1}{\lambda} \hat{\ell}_t({\boldsymbol x})\right)\right]+\hat{\ell}_t({\boldsymbol x}_t) &=\lambda \ln\mathop{\mathbb E}_{{\boldsymbol x}\sim P_t}\left[\exp\left(-\frac{1}{\lambda} \left(\hat{\ell}_t({\boldsymbol x})-\hat{\ell}_t({\boldsymbol x}_t)\right)\right)\right]\\ &= \lambda \ln\mathop{\mathbb E}_{{\boldsymbol x}\sim P_t}\left[\exp\left(-\frac{1}{\lambda} \left(\langle {\boldsymbol g}_t, {\boldsymbol x}-{\boldsymbol x}_t\rangle + \frac12 \|{\boldsymbol x}-{\boldsymbol x}_t\|^2_{{\boldsymbol M}_t}\right)\right)\right] \\ &= \frac{1}{2 \lambda}{\boldsymbol g}_t^\top {\boldsymbol \Sigma}_{t+1}{\boldsymbol g}_t - \frac{\lambda}{2}\ln \frac{|{\boldsymbol \Sigma}_{t}|}{|{\boldsymbol \Sigma}_{t+1}|}, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Clambda+%5Cln%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+P_t%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda%7D+%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29%5Cright%29%5Cright%5D%2B%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29+%26%3D%5Clambda+%5Cln%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+P_t%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda%7D+%5Cleft%28%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29-%5Chat%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D_t%29%5Cright%29%5Cright%29%5Cright%5D%5C%5C+%26%3D+%5Clambda+%5Cln%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+P_t%7D%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda%7D+%5Cleft%28%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D-%7B%5Cboldsymbol+x%7D_t%5Crangle+%2B+%5Cfrac12+%5C%7C%7B%5Cboldsymbol+x%7D-%7B%5Cboldsymbol+x%7D_t%5C%7C%5E2_%7B%7B%5Cboldsymbol+M%7D_t%7D%5Cright%29%5Cright%29%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7B2+%5Clambda%7D%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%7B%5Cboldsymbol+g%7D_t+-+%5Cfrac%7B%5Clambda%7D%7B2%7D%5Cln+%5Cfrac%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%7D%7C%7D%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%7C%7D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where in the last inequality we used the that
![\displaystyle \mathop{\mathbb E}_{{\boldsymbol x}\sim \mathcal{N}({\boldsymbol x}_t,{\boldsymbol \Sigma}_t)} \left[\exp\left(-\frac{1}{\lambda}\langle {\boldsymbol g}_t, {\boldsymbol x}-{\boldsymbol x}_t\rangle\right)\right] =\exp\left(\frac{1}{2 \lambda^2}{\boldsymbol g}_t^\top \left({\boldsymbol \Sigma}_t^{-1}+\frac{1}{\lambda} M_t\right)^{-1} {\boldsymbol g}_t\right) =\exp\left(\frac{1}{2 \lambda^2}{\boldsymbol g}_t^\top {\boldsymbol \Sigma}_{t+1}^{-1} {\boldsymbol g}_t\right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+%5Cmathcal%7BN%7D%28%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+%5CSigma%7D_t%29%7D+%5Cleft%5B%5Cexp%5Cleft%28-%5Cfrac%7B1%7D%7B%5Clambda%7D%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D-%7B%5Cboldsymbol+x%7D_t%5Crangle%5Cright%29%5Cright%5D+%3D%5Cexp%5Cleft%28%5Cfrac%7B1%7D%7B2+%5Clambda%5E2%7D%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%5Cleft%28%7B%5Cboldsymbol+%5CSigma%7D_t%5E%7B-1%7D%2B%5Cfrac%7B1%7D%7B%5Clambda%7D+M_t%5Cright%29%5E%7B-1%7D+%7B%5Cboldsymbol+g%7D_t%5Cright%29+%3D%5Cexp%5Cleft%28%5Cfrac%7B1%7D%7B2+%5Clambda%5E2%7D%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%5E%7B-1%7D+%7B%5Cboldsymbol+g%7D_t%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and ![{\mathop{\mathbb E}_{{\boldsymbol x}\sim \mathcal{N}(\boldsymbol{0},{\boldsymbol \Sigma}_t)}[\exp(-\frac{1}{2 \lambda} {\boldsymbol x}^\top {\boldsymbol M}_t {\boldsymbol x})]=\frac{1}{\sqrt{|{\boldsymbol I}_d+\frac{1}{\lambda}{\boldsymbol \Sigma}_t {\boldsymbol M}_t|}}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+x%7D%5Csim+%5Cmathcal%7BN%7D%28%5Cboldsymbol%7B0%7D%2C%7B%5Cboldsymbol+%5CSigma%7D_t%29%7D%5B%5Cexp%28-%5Cfrac%7B1%7D%7B2+%5Clambda%7D+%7B%5Cboldsymbol+x%7D%5E%5Ctop+%7B%5Cboldsymbol+M%7D_t+%7B%5Cboldsymbol+x%7D%29%5D%3D%5Cfrac%7B1%7D%7B%5Csqrt%7B%7C%7B%5Cboldsymbol+I%7D_d%2B%5Cfrac%7B1%7D%7B%5Clambda%7D%7B%5Cboldsymbol+%5CSigma%7D_t+%7B%5Cboldsymbol+M%7D_t%7C%7D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Putting all together, we obtain
![\displaystyle \frac{\lambda}{2} \left(\ln\frac{|{\boldsymbol \Sigma}_1|}{|{\boldsymbol C}|}+\text{Tr}({\boldsymbol C} {\boldsymbol \Sigma}^{-1}_1)-d+ ({\boldsymbol x}_1-{\boldsymbol u})^\top {\boldsymbol \Sigma}^{-1}_1({\boldsymbol x}_1-{\boldsymbol u}) \right) + \frac{1}{2 \lambda}\sum_{t=1}^T {\boldsymbol g}_t^\top {\boldsymbol \Sigma}_{t+1}{\boldsymbol g}_t - \frac{\lambda}{2}\ln \frac{|{\boldsymbol \Sigma}_{1}|}{|{\boldsymbol \Sigma}_{T+1}|} + \frac{1}{2} \text{Tr}\left[C \sum_{t=1}^T {\boldsymbol M}_t\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Clambda%7D%7B2%7D+%5Cleft%28%5Cln%5Cfrac%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_1%7C%7D%7B%7C%7B%5Cboldsymbol+C%7D%7C%7D%2B%5Ctext%7BTr%7D%28%7B%5Cboldsymbol+C%7D+%7B%5Cboldsymbol+%5CSigma%7D%5E%7B-1%7D_1%29-d%2B+%28%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%29%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D%5E%7B-1%7D_1%28%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%29+%5Cright%29+%2B+%5Cfrac%7B1%7D%7B2+%5Clambda%7D%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%7B%5Cboldsymbol+g%7D_t+-+%5Cfrac%7B%5Clambda%7D%7B2%7D%5Cln+%5Cfrac%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7B1%7D%7C%7D%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7BT%2B1%7D%7C%7D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Ctext%7BTr%7D%5Cleft%5BC+%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+M%7D_t%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
We now select 
![\displaystyle \begin{aligned} &\frac{\lambda}{2} \left(\ln\frac{|{\boldsymbol \Sigma}_1|}{|{\boldsymbol \Sigma}_{T+1}|}+\text{Tr}({\boldsymbol \Sigma}_{T+1} {\boldsymbol \Sigma}^{-1}_1)-d+ ({\boldsymbol u}-{\boldsymbol x}_1)^\top {\boldsymbol \Sigma}^{-1}_1({\boldsymbol u}-{\boldsymbol x}_1) \right) + \frac{1}{2\lambda}\sum_{t=1}^T {\boldsymbol g}_t^\top {\boldsymbol \Sigma}_{t+1}{\boldsymbol g}_t - \frac{\lambda}{2}\ln \frac{|{\boldsymbol \Sigma}_{1}|}{|{\boldsymbol \Sigma}_{T+1}|}\\ &\quad + \frac{1}{2} \text{Tr}\left[{\boldsymbol \Sigma}_{T+1} \sum_{t=1}^T {\boldsymbol M}_t\right]\\ &=\frac{\lambda}{2} ({\boldsymbol x}_1-{\boldsymbol u})^\top {\boldsymbol \Sigma}^{-1}_1({\boldsymbol x}_1-{\boldsymbol u}) + \frac{1}{2 \lambda}\sum_{t=1}^T {\boldsymbol g}_t^\top {\boldsymbol \Sigma}_{t+1}{\boldsymbol g}_t~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26%5Cfrac%7B%5Clambda%7D%7B2%7D+%5Cleft%28%5Cln%5Cfrac%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_1%7C%7D%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7BT%2B1%7D%7C%7D%2B%5Ctext%7BTr%7D%28%7B%5Cboldsymbol+%5CSigma%7D_%7BT%2B1%7D+%7B%5Cboldsymbol+%5CSigma%7D%5E%7B-1%7D_1%29-d%2B+%28%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_1%29%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D%5E%7B-1%7D_1%28%7B%5Cboldsymbol+u%7D-%7B%5Cboldsymbol+x%7D_1%29+%5Cright%29+%2B+%5Cfrac%7B1%7D%7B2%5Clambda%7D%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%7B%5Cboldsymbol+g%7D_t+-+%5Cfrac%7B%5Clambda%7D%7B2%7D%5Cln+%5Cfrac%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7B1%7D%7C%7D%7B%7C%7B%5Cboldsymbol+%5CSigma%7D_%7BT%2B1%7D%7C%7D%5C%5C+%26%5Cquad+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Ctext%7BTr%7D%5Cleft%5B%7B%5Cboldsymbol+%5CSigma%7D_%7BT%2B1%7D+%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+M%7D_t%5Cright%5D%5C%5C+%26%3D%5Cfrac%7B%5Clambda%7D%7B2%7D+%28%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%29%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D%5E%7B-1%7D_1%28%7B%5Cboldsymbol+x%7D_1-%7B%5Cboldsymbol+u%7D%29+%2B+%5Cfrac%7B1%7D%7B2+%5Clambda%7D%5Csum_%7Bt%3D1%7D%5ET+%7B%5Cboldsymbol+g%7D_t%5E%5Ctop+%7B%5Cboldsymbol+%5CSigma%7D_%7Bt%2B1%7D%7B%5Cboldsymbol+g%7D_t%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
3. Example of WAA: The Krichevsky-Trofimov Betting Algorithm
Here, we show how to derive the Krichevsky-Trofimov betting algorithm and its regret upper bound. We consider the WAA algorithm where we set the losses to 

![{\mathcal{V}=[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BV%7D%3D%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Given that ![{a_t=\sum_{i=1}^t \boldsymbol{1}[c_i=1]}](https://s0.wp.com/latex.php?latex=%7Ba_t%3D%5Csum_%7Bi%3D1%7D%5Et+%5Cboldsymbol%7B1%7D%5Bc_i%3D1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{b_t=\sum_{i=1}^t \boldsymbol{1}[c_i=-1]}](https://s0.wp.com/latex.php?latex=%7Bb_t%3D%5Csum_%7Bi%3D1%7D%5Et+%5Cboldsymbol%7B1%7D%5Bc_i%3D-1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \mathop{\mathbb E}_{x \sim P_1}\left[\prod_{i=1}^t (1+c_i x)\right] &= \frac{2^{a_t+b_t} \Gamma(a_t+1/2) \Gamma(b_t+1/2)}{\pi \Gamma(a_t+b_t+1)},\\ \mathop{\mathbb E}_{x \sim P_1}\left[x \prod_{i=1}^t (1+c_i x)\right] &= \frac{2^{a_t+b_t}\, (a_t-b_t) \, \Gamma(a_t+1/2)\, \Gamma(b_t+1/2)}{\pi\, (a_t+b_t+1)\,\Gamma(a_t+b_t+1)},\\ \max_v \ \prod_{t=1}^T (1+c_t v) =\max_v \ (1+v)^{a_T} (1-v)^{b_T} &= \left(1+\frac{a_T-b_T}{T}\right)^{a_T} \left(1-\frac{a_T-b_T}{T}\right)^{b_T} = 2^T a_T^{a_T} b_T^{b_T} T^{-T}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bx+%5Csim+P_1%7D%5Cleft%5B%5Cprod_%7Bi%3D1%7D%5Et+%281%2Bc_i+x%29%5Cright%5D+%26%3D+%5Cfrac%7B2%5E%7Ba_t%2Bb_t%7D+%5CGamma%28a_t%2B1%2F2%29+%5CGamma%28b_t%2B1%2F2%29%7D%7B%5Cpi+%5CGamma%28a_t%2Bb_t%2B1%29%7D%2C%5C%5C+%5Cmathop%7B%5Cmathbb+E%7D_%7Bx+%5Csim+P_1%7D%5Cleft%5Bx+%5Cprod_%7Bi%3D1%7D%5Et+%281%2Bc_i+x%29%5Cright%5D+%26%3D+%5Cfrac%7B2%5E%7Ba_t%2Bb_t%7D%5C%2C+%28a_t-b_t%29+%5C%2C+%5CGamma%28a_t%2B1%2F2%29%5C%2C+%5CGamma%28b_t%2B1%2F2%29%7D%7B%5Cpi%5C%2C+%28a_t%2Bb_t%2B1%29%5C%2C%5CGamma%28a_t%2Bb_t%2B1%29%7D%2C%5C%5C+%5Cmax_v+%5C+%5Cprod_%7Bt%3D1%7D%5ET+%281%2Bc_t+v%29+%3D%5Cmax_v+%5C+%281%2Bv%29%5E%7Ba_T%7D+%281-v%29%5E%7Bb_T%7D+%26%3D+%5Cleft%281%2B%5Cfrac%7Ba_T-b_T%7D%7BT%7D%5Cright%29%5E%7Ba_T%7D+%5Cleft%281-%5Cfrac%7Ba_T-b_T%7D%7BT%7D%5Cright%29%5E%7Bb_T%7D+%3D+2%5ET+a_T%5E%7Ba_T%7D+b_T%5E%7Bb_T%7D+T%5E%7B-T%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
With the above formulas we can calculate that

and
![\displaystyle x_{t+1} =\mathop{\mathbb E}_{x \sim P_t}[x] =\frac{a_t-b_t}{a_t+b_t+1} =\frac{\sum_{i=1}^t c_i}{t+1}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+x_%7Bt%2B1%7D+%3D%5Cmathop%7B%5Cmathbb+E%7D_%7Bx+%5Csim+P_t%7D%5Bx%5D+%3D%5Cfrac%7Ba_t-b_t%7D%7Ba_t%2Bb_t%2B1%7D+%3D%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5Et+c_i%7D%7Bt%2B1%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Using the second result in Theorem 7, we have
![\displaystyle \begin{aligned} \sum_{t=1}^T (\ell_t(x_t)-\ell_t(u)) &\leq \ln \frac{\max_{v \in [-1,1]} \ \prod_{t=1}^T (1+c_t v)}{\mathop{\mathbb E}_{x \sim P_1} [\prod_{t=1}^T (1+c_t x)]}\\ &\leq \ln \frac{2^T a_T^{a_T} b_T^{b_T} T^{-T} \, \pi \, \Gamma(a_T+b_T+1)}{2^{a_T+b_T}\,\Gamma(a_T+1/2) \, \Gamma(b_T+1/2) }\\ &= \ln \frac{a_T^{a_T} b_T^{b_T} T^{-T} \pi \, \Gamma(T+1)}{\Gamma(a_T+1/2) \, \Gamma(b_T+1/2) }~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%28%5Cell_t%28x_t%29-%5Cell_t%28u%29%29+%26%5Cleq+%5Cln+%5Cfrac%7B%5Cmax_%7Bv+%5Cin+%5B-1%2C1%5D%7D+%5C+%5Cprod_%7Bt%3D1%7D%5ET+%281%2Bc_t+v%29%7D%7B%5Cmathop%7B%5Cmathbb+E%7D_%7Bx+%5Csim+P_1%7D+%5B%5Cprod_%7Bt%3D1%7D%5ET+%281%2Bc_t+x%29%5D%7D%5C%5C+%26%5Cleq+%5Cln+%5Cfrac%7B2%5ET+a_T%5E%7Ba_T%7D+b_T%5E%7Bb_T%7D+T%5E%7B-T%7D+%5C%2C+%5Cpi+%5C%2C+%5CGamma%28a_T%2Bb_T%2B1%29%7D%7B2%5E%7Ba_T%2Bb_T%7D%5C%2C%5CGamma%28a_T%2B1%2F2%29+%5C%2C+%5CGamma%28b_T%2B1%2F2%29+%7D%5C%5C+%26%3D+%5Cln+%5Cfrac%7Ba_T%5E%7Ba_T%7D+b_T%5E%7Bb_T%7D+T%5E%7B-T%7D+%5Cpi+%5C%2C+%5CGamma%28T%2B1%29%7D%7B%5CGamma%28a_T%2B1%2F2%29+%5C%2C+%5CGamma%28b_T%2B1%2F2%29+%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Using Lemma 13.6 in my draft book, we have that this expression is maximized for 




4. History Bits
The WAA is from Kivinen&Warmuth (1999), as a simplification of the AA of Vovk (1990) (see also Vovk (1998, Appendix A) for an easier description of the AA).
This algorithm is known with many names: Cesa-Bianchi&Lugosi (2006) calls it “exponentially weighted mixture forecaster”, Hazan et al. (2006), Hazan et al. (2007) rediscover it (see below) and name it “exponentially weighted online optimization algorithm”, Wouter Koolen calls it simply “exponential weights algorithm” in his blog post in 2016 (see below). I preferred to use the name that its designers gave to it, also because its acronym nicely matches the one of the Aggregating Algorithm.
Theorem 5 and Example 1 are from Kivinen&Warmuth (1999).
The observation that the AA also works for infinite sets of experts was made by Freund (1996), Freund (2003).
Theorem 8 is from Hazan et al. (2006), Hazan et al. (2007), where they seem to rediscover the WAA algorithm with uniform prior, but I improved it by adding 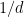
Almost the entire Section 2.3 is from a blog post by Wouter Koolen (the blog of Wouter is really good, full of gems and this is one of them!), where it is done for OGD, while I derived it for FTRL. van der Hoeven&van Erven (2016) has extended this equivalence to Online Mirror Descent. The subtlety of defining the prior on
Acknowledgments
Thanks to Wei-Cheng Lee for feedback on a prelimary version of this post and to Gemini 2.5 for checking all the proofs.
