This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
In the last lecture, we have shown a very simple and parameter-free algorithm for Online Convex Optimization (OCO) in  -dimensions, based on a reduction to a coin-betting problem. Now, we will see how to reduce Learning with Expert Advice (LEA) to betting on coins, obtaining again parameter-free and optimal algorithms.
-dimensions, based on a reduction to a coin-betting problem. Now, we will see how to reduce Learning with Expert Advice (LEA) to betting on coins, obtaining again parameter-free and optimal algorithms.
1. Reduction to Learning with Experts
First, remember that the regret we got from Online Mirror Descent (OMD), and similarly for Follow-The-Regularized-Leader (FTRL), is

where 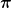 is the prior distribution on the experts and
is the prior distribution on the experts and  is the KL-divergence. As we reasoned in the OCO case, in order to set the learning rate we should know the value of
is the KL-divergence. As we reasoned in the OCO case, in order to set the learning rate we should know the value of 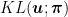 . If we could set
. If we could set  to
to 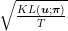 , we would obtain a regret of
, we would obtain a regret of  . However, given the adversarial nature of the game, this is impossible. So, as we did in the OCO case, we will show that even this problem can be reduced to betting on a coin, obtaining optimal guarantees with a parameter-free algorithm.
. However, given the adversarial nature of the game, this is impossible. So, as we did in the OCO case, we will show that even this problem can be reduced to betting on a coin, obtaining optimal guarantees with a parameter-free algorithm.
First, let’s introduce some notation. Let  be the number of experts and
be the number of experts and 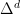 be the -dimensional probability simplex. Let
be the -dimensional probability simplex. Let ![{{\boldsymbol \pi} = [\pi_1, \pi_2, \dots, \pi_d] \in \Delta^d}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+%5Cpi%7D+%3D+%5B%5Cpi_1%2C+%5Cpi_2%2C+%5Cdots%2C+%5Cpi_d%5D+%5Cin+%5CDelta%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) be any prior distribution. Let
be any prior distribution. Let 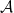 be a coin-betting algorithm. We will instantiate copies of .
be a coin-betting algorithm. We will instantiate copies of .
Consider any round  . Let
. Let 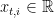 be the bet of the
be the bet of the  -th copy of . The LEA algorithm computes
-th copy of . The LEA algorithm computes ![{\widehat {\boldsymbol p}_t = [\widehat p_{t,1}, \widehat p_{t,2}, \dots, \widehat p_{t,d}] \in {\mathbb R}_{+}^d}](https://s0.wp.com/latex.php?latex=%7B%5Cwidehat+%7B%5Cboldsymbol+p%7D_t+%3D+%5B%5Cwidehat+p_%7Bt%2C1%7D%2C+%5Cwidehat+p_%7Bt%2C2%7D%2C+%5Cdots%2C+%5Cwidehat+p_%7Bt%2Cd%7D%5D+%5Cin+%7B%5Cmathbb+R%7D_%7B%2B%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as

Then, the LEA algorithm predicts ![{{\boldsymbol p}_t = [p_{t,1}, p_{t,2}, \dots, p_{t,d}] \in \Delta^d}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+p%7D_t+%3D+%5Bp_%7Bt%2C1%7D%2C+p_%7Bt%2C2%7D%2C+%5Cdots%2C+p_%7Bt%2Cd%7D%5D+%5Cin+%5CDelta%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as
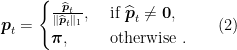
Then, the algorithm receives the reward vector ![{{\boldsymbol g}_t = [g_{t,1}, g_{t,2}, \dots, g_{t,d}] \in [0,1]^d}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+g%7D_t+%3D+%5Bg_%7Bt%2C1%7D%2C+g_%7Bt%2C2%7D%2C+%5Cdots%2C+g_%7Bt%2Cd%7D%5D+%5Cin+%5B0%2C1%5D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Finally, it feeds the reward to each copy of . The reward for the -th copy of is
. Finally, it feeds the reward to each copy of . The reward for the -th copy of is ![{c_{t,i} \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bc_%7Bt%2Ci%7D+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) defined as
defined as

The construction above defines a LEA algorithm defined by the predictions  , based on the algorithm . We can prove the following regret bound for it.
, based on the algorithm . We can prove the following regret bound for it.
Theorem 1 (Regret Bound for Experts) Let be a coin-betting algorithm that guarantees a wealth after rounds with initial money equal to 1 of 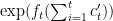 for any sequence of continuous coin outcomes
for any sequence of continuous coin outcomes ![{c'_1, \dots, c't \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bc%27_1%2C+%5Cdots%2C+c%27t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then, the regret of the LEA algorithm with prior
. Then, the regret of the LEA algorithm with prior  that predicts at each round with in (2) satisfies
that predicts at each round with in (2) satisfies

for any 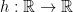 concave and non-decreasing such that
concave and non-decreasing such that  .
.
Proof: We first prove that  . Indeed,
. Indeed,

The first equality follows from definition of 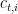 . To see the second equality, consider two cases: If
. To see the second equality, consider two cases: If  for all then
for all then  and therefore both
and therefore both 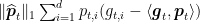 and
and  are trivially zero. If
are trivially zero. If  then
then  for all .
for all .
From the assumption on , we have for any sequence 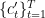 such that
such that ![{c'_t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bc%27_t+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that
that

So, inequality and (4) imply

Now, for any competitor 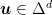 ,
,
![\displaystyle \begin{aligned} \text{Regret}_T({\boldsymbol u}) &= \sum_{t=1}^T \langle {\boldsymbol g}_t, {\boldsymbol p}_t - {\boldsymbol u} \rangle \\ &= \sum_{t=1}^T \sum_{i=1}^d u_i \left(\langle {\boldsymbol g}_t, {\boldsymbol p}_t \rangle - g_{t,i} \right) \\ & \le \sum_{t=1}^T \sum_{i=1}^N u_i c_{t,i} \qquad \text{(by definition of } c_{t,i} \text{)} \\ & \leq \sum_{i=1}^N u_i h\left(f_T\left( \sum_{t=1}^T c_{t,i}\right) \right) \qquad \text{(definition of the } h(x) \text{)} \\ & \le h\left[\sum_{i=1}^N u_i f_T\left( \sum_{t=1}^T c_{t,i}\right) \right] \qquad \text{(by concavity of } h \text{ and Jensen inequality)} \\ & \le h\left[KL({\boldsymbol u};{\boldsymbol \pi})+\ln \left(\sum_{i=1}^N \pi_i \exp\left(f_T\left(\sum_{t=1}^T c_{t,i}\right)\right) \right)\right] \qquad \text{(Fenchel-Young inequality)} \\ & \le h(KL({\boldsymbol u};{\boldsymbol \pi})) \qquad \text{(by (5))}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctext%7BRegret%7D_T%28%7B%5Cboldsymbol+u%7D%29+%26%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+p%7D_t+-+%7B%5Cboldsymbol+u%7D+%5Crangle+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Csum_%7Bi%3D1%7D%5Ed+u_i+%5Cleft%28%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+p%7D_t+%5Crangle+-+g_%7Bt%2Ci%7D+%5Cright%29+%5C%5C+%26+%5Cle+%5Csum_%7Bt%3D1%7D%5ET+%5Csum_%7Bi%3D1%7D%5EN+u_i+c_%7Bt%2Ci%7D+%5Cqquad+%5Ctext%7B%28by+definition+of+%7D+c_%7Bt%2Ci%7D+%5Ctext%7B%29%7D+%5C%5C+%26+%5Cleq+%5Csum_%7Bi%3D1%7D%5EN+u_i+h%5Cleft%28f_T%5Cleft%28+%5Csum_%7Bt%3D1%7D%5ET+c_%7Bt%2Ci%7D%5Cright%29+%5Cright%29+%5Cqquad+%5Ctext%7B%28definition+of+the+%7D+h%28x%29+%5Ctext%7B%29%7D+%5C%5C+%26+%5Cle+h%5Cleft%5B%5Csum_%7Bi%3D1%7D%5EN+u_i+f_T%5Cleft%28+%5Csum_%7Bt%3D1%7D%5ET+c_%7Bt%2Ci%7D%5Cright%29+%5Cright%5D+%5Cqquad+%5Ctext%7B%28by+concavity+of+%7D+h+%5Ctext%7B+and+Jensen+inequality%29%7D+%5C%5C+%26+%5Cle+h%5Cleft%5BKL%28%7B%5Cboldsymbol+u%7D%3B%7B%5Cboldsymbol+%5Cpi%7D%29%2B%5Cln+%5Cleft%28%5Csum_%7Bi%3D1%7D%5EN+%5Cpi_i+%5Cexp%5Cleft%28f_T%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+c_%7Bt%2Ci%7D%5Cright%29%5Cright%29+%5Cright%29%5Cright%5D+%5Cqquad+%5Ctext%7B%28Fenchel-Young+inequality%29%7D+%5C%5C+%26+%5Cle+h%28KL%28%7B%5Cboldsymbol+u%7D%3B%7B%5Cboldsymbol+%5Cpi%7D%29%29+%5Cqquad+%5Ctext%7B%28by+%285%29%29%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Now, we could think to use the Krichevsky–Trofimov (KT) bettor with this theorem. However, we would obtain a sub-optimal regret guarantee. In fact, remembering the lower bound on the wealth of KT and setting  where
where  is a universal constant, we have
is a universal constant, we have

We might think that the  is the price we have to pay to adapt to the unknown competitor
is the price we have to pay to adapt to the unknown competitor 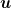 . However, it turns out it can be removed. In the next section, we see how to change the KT strategy to obtain the optimal guarantee.
. However, it turns out it can be removed. In the next section, we see how to change the KT strategy to obtain the optimal guarantee.
2. A Betting Strategy that Looses at Most a Constant Fraction of Money
In the reduction before, if we use the KT betting strategy we would have a term under the square root. It turns out that we can avoid that term if we know the number of rounds beforehand. Then, in case  is unknown we can just use a doubling trick, paying only a constant multiplicative factor in the regret.
is unknown we can just use a doubling trick, paying only a constant multiplicative factor in the regret.
The logarithmic term in the regret comes from the fact that the lower bound on the wealth is
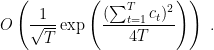
Note that in the case in which the number of heads in the sequence is equal to the number of heads, so that  , the guaranteed wealth becomes proportional to
, the guaranteed wealth becomes proportional to  . So, for that goes to infinity the bettor will lose all of its money.
. So, for that goes to infinity the bettor will lose all of its money.
Instead, we need a more conservative strategy that guarantees

for  small enough and independent of . In this case, the betting strategy has to pace its betting, possibly with the knowledge of the duration of the game, so that even in the case that the number of heads is equal to the number of tails it will only lose a fraction of its money. At the same time, it will still gain an exponential amount of money when the coin outcomes are biased towards one side.
small enough and independent of . In this case, the betting strategy has to pace its betting, possibly with the knowledge of the duration of the game, so that even in the case that the number of heads is equal to the number of tails it will only lose a fraction of its money. At the same time, it will still gain an exponential amount of money when the coin outcomes are biased towards one side.
We will prove that this is possible, designing a new betting strategy.
Denote by  for
for  and define
and define
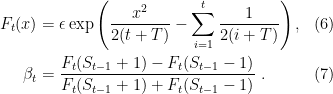
Note that if

then, by induction,  . In fact, we have
. In fact, we have

Hence, we have to prove that (8) is true in order to guarantee a minimum wealth of our betting strategy.
First, given that 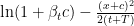 is a concave function of
is a concave function of  , we have
, we have
![\displaystyle \min_{ c \in [-1,1]} \ \ln(1+\beta_t c) - \frac{(x+c)^2}{2(t+T)} = \min\left(\ln(1+\beta_t) - \frac{(x+1)^2}{2(t+T)}, \ln(1-\beta_t) - \frac{(x-1)^2}{2(t+T)}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7B+c+%5Cin+%5B-1%2C1%5D%7D+%5C+%5Cln%281%2B%5Cbeta_t+c%29+-+%5Cfrac%7B%28x%2Bc%29%5E2%7D%7B2%28t%2BT%29%7D+%3D+%5Cmin%5Cleft%28%5Cln%281%2B%5Cbeta_t%29+-+%5Cfrac%7B%28x%2B1%29%5E2%7D%7B2%28t%2BT%29%7D%2C+%5Cln%281-%5Cbeta_t%29+-+%5Cfrac%7B%28x-1%29%5E2%7D%7B2%28t%2BT%29%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Also, our choice of  makes the two quantities above equal with
makes the two quantities above equal with  , that is
, that is

For other choices of , the two alternatives would be different and the minimum one could always be the one picked by the adversary. Instead, making the two choices worst outcomes equivalent, we minimize the damage of the adversarial choice of the outcomes of the coin. So, we have that
![\displaystyle \begin{aligned} \ln (1+\beta_t c_t) - \ln F_t(S_t) &= \ln (1+\beta_t c_t) + F_t(S_{t-1}+c_t) \\ &\geq \min_{ c \in [-1,1]} \ \ln (1+\beta_t c) + \ln F_t(S_{t-1}+c) \\ &= -\ln \frac{F_{t}(S_{t-1}+1)+F_{t}(S_{t-1}-1)}{2} \\ &=- \ln \left[\exp\left(\frac{S_{t-1}^2+1}{2(t+T)} - \sum_{i=1}^t \frac{1}{2(i+T)}\right) \frac{1}{2}\left(\exp\left(\frac{S_{t-1}}{t+T}\right) + \exp\left(\frac{-S_{t-1}}{t+T}\right) \right) \right] \\ &= -\frac{S_{t-1}^2+1}{2(t+T)} - \ln \cosh\frac{S_{t-1}}{t+T} + \sum_{i=1}^t \frac{1}{2(i+T)} \\ &\geq -\frac{S_{t-1}^2}{2(t+T)} - \frac{S_{t-1}^2}{2(t+T)^2} + \sum_{i=1}^{t-1} \frac{1}{2(i+T)} \\ &\geq -\frac{S_{t-1}^2}{2(t+T)} - \frac{S_{t-1}^2}{2(t+T)(t-1+T)} + \sum_{i=1}^{t-1} \frac{1}{2(i+T)} \\ &= -\frac{S_{t-1}^2}{2(t-1+T)}+ \sum_{i=1}^{t-1} \frac{1}{2(i+T)} \\ &= -\ln F_{t-1}(S_{t-1}), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cln+%281%2B%5Cbeta_t+c_t%29+-+%5Cln+F_t%28S_t%29+%26%3D+%5Cln+%281%2B%5Cbeta_t+c_t%29+%2B+F_t%28S_%7Bt-1%7D%2Bc_t%29+%5C%5C+%26%5Cgeq+%5Cmin_%7B+c+%5Cin+%5B-1%2C1%5D%7D+%5C+%5Cln+%281%2B%5Cbeta_t+c%29+%2B+%5Cln+F_t%28S_%7Bt-1%7D%2Bc%29+%5C%5C+%26%3D+-%5Cln+%5Cfrac%7BF_%7Bt%7D%28S_%7Bt-1%7D%2B1%29%2BF_%7Bt%7D%28S_%7Bt-1%7D-1%29%7D%7B2%7D+%5C%5C+%26%3D-+%5Cln+%5Cleft%5B%5Cexp%5Cleft%28%5Cfrac%7BS_%7Bt-1%7D%5E2%2B1%7D%7B2%28t%2BT%29%7D+-+%5Csum_%7Bi%3D1%7D%5Et+%5Cfrac%7B1%7D%7B2%28i%2BT%29%7D%5Cright%29+%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cexp%5Cleft%28%5Cfrac%7BS_%7Bt-1%7D%7D%7Bt%2BT%7D%5Cright%29+%2B+%5Cexp%5Cleft%28%5Cfrac%7B-S_%7Bt-1%7D%7D%7Bt%2BT%7D%5Cright%29+%5Cright%29+%5Cright%5D+%5C%5C+%26%3D+-%5Cfrac%7BS_%7Bt-1%7D%5E2%2B1%7D%7B2%28t%2BT%29%7D+-+%5Cln+%5Ccosh%5Cfrac%7BS_%7Bt-1%7D%7D%7Bt%2BT%7D+%2B+%5Csum_%7Bi%3D1%7D%5Et+%5Cfrac%7B1%7D%7B2%28i%2BT%29%7D+%5C%5C+%26%5Cgeq+-%5Cfrac%7BS_%7Bt-1%7D%5E2%7D%7B2%28t%2BT%29%7D+-+%5Cfrac%7BS_%7Bt-1%7D%5E2%7D%7B2%28t%2BT%29%5E2%7D+%2B+%5Csum_%7Bi%3D1%7D%5E%7Bt-1%7D+%5Cfrac%7B1%7D%7B2%28i%2BT%29%7D+%5C%5C+%26%5Cgeq+-%5Cfrac%7BS_%7Bt-1%7D%5E2%7D%7B2%28t%2BT%29%7D+-+%5Cfrac%7BS_%7Bt-1%7D%5E2%7D%7B2%28t%2BT%29%28t-1%2BT%29%7D+%2B+%5Csum_%7Bi%3D1%7D%5E%7Bt-1%7D+%5Cfrac%7B1%7D%7B2%28i%2BT%29%7D+%5C%5C+%26%3D+-%5Cfrac%7BS_%7Bt-1%7D%5E2%7D%7B2%28t-1%2BT%29%7D%2B+%5Csum_%7Bi%3D1%7D%5E%7Bt-1%7D+%5Cfrac%7B1%7D%7B2%28i%2BT%29%7D+%5C%5C+%26%3D+-%5Cln+F_%7Bt-1%7D%28S_%7Bt-1%7D%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where in the second equality we used the definition of and in the second inequality we used the fact that  .
.
Hence, given that (8) is true, this strategy guarantees
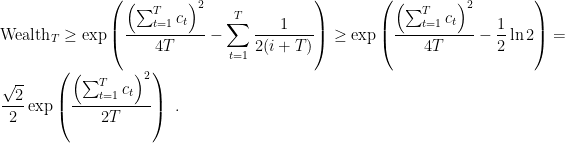
We can now use this betting strategy in the expert reduction in Theorem 1, setting  , to have
, to have

Note that this betting strategy could also be used in the OCO reduction. Given that we removed the logarithmic term in the exponent, in the 1-dimensional case, we would obtain a regret of

where we gained in the  term inside the logarithmic, instead of the term of the KT algorithm. This implies that now we can set
term inside the logarithmic, instead of the term of the KT algorithm. This implies that now we can set  to and obtain an asymptotic rate of
to and obtain an asymptotic rate of 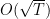 rather than
rather than  .
.
3. History Bits
The first parameter-free algorithm for experts is from (Chaudhuri, K. and Freund, Y. and Hsu, D. J., 2009), named NormalHedge, where they obtained a bound similar to the one in (9) but with an additional  term. Then, (Chernov, A. and Vovk, V., 2010) removed the log factors with an update without a closed form. (Orabona, F. and Pal, D., 2016) showed that this guarantee can be efficiently obtained through the novel reduction to coin-betting in Theorem 1. Later, these kind of regret guarantees were improved to depend on the sum of the squared losses rather than on time, but with an additional factor, in the Squint algorithm (Koolen, W. M. and van Erven, T., 2015). It is worth noting that the Squint algorithm can be interpreted exactly as a coin-betting algorithm plus the reduction in Theorem 1.
term. Then, (Chernov, A. and Vovk, V., 2010) removed the log factors with an update without a closed form. (Orabona, F. and Pal, D., 2016) showed that this guarantee can be efficiently obtained through the novel reduction to coin-betting in Theorem 1. Later, these kind of regret guarantees were improved to depend on the sum of the squared losses rather than on time, but with an additional factor, in the Squint algorithm (Koolen, W. M. and van Erven, T., 2015). It is worth noting that the Squint algorithm can be interpreted exactly as a coin-betting algorithm plus the reduction in Theorem 1.
The betting strategy in (6) and (7) are new, and derived from the shifted-KT potentials in (Orabona, F. and Pal, D., 2016). The guarantee is the same obtained by the shifted-KT potentials, but the analysis can be done without knowing the properties of the gamma function.
4. Exercises
Exercise 1 Using the same proof technique in the lecture, find a betting strategy whose wealth depends on  rather than on .
rather than on .

Nice, post! The amount of work to remove just a ln T factor is impressive!
I have few questions: since you mentioned Squint, can you elaborate more on how it can be seen as a coin betting algorithm? I find Squint really appealing, since the sum of square losses should always be no worse than T, but it can actually be much better, for example it implies constant regret in a stochastic setting (see for example thm. 11 in http://proceedings.mlr.press/v35/gaillard14.pdf). Is it possible to give such bounds, or first-order bounds using a KT strategy?
Also, there should be some applications where the knowledge of the time horizon is not available in advance. For example, in the construction used to get strongly-adaptive regret bounds (as in your paper http://proceedings.mlr.press/v54/jun17a/jun17a.pdf), I guess in this case it would be better to use Squint?
Thank you!
LikeLike
Sorry, regarding the strongly-adaptive construction I suppose the real problem is not the knowledge of T but the fact that you shouldn’t be able to use a doubling trick.
Nicolò
LikeLike
The main difficulty in dealing with Squint is the “improper prior” they use. The rest is easy: by induction you can show that any potential of the form used by Squint gives a lower bound to the wealth. I will try to find the time to write a post on it: it is easier to explain with equations.
If you don’t care about improper prior, you would get additional log factors. Note that Squint gets a log log term that is probably unavoidable.
In alternative, if you just care about the constant regret in the stochastic setting, you can get it easily with a strategy that depends on sum |c_i| rather than sum c_i^2. This is much easier to do and it was done in OCO with Pistol (https://arxiv.org/abs/1406.3816) and Learning with Experts with AdaNormalHedge (http://proceedings.mlr.press/v40/Luo15.pdf). Note that again it can be proven that these are betting algorithms. The only difference is that they bet with the lower bound to the wealth times the betting fraction rather than using the actual wealth times the betting fraction. Note that the proof of AdaNormalHedge is complex only because they truncate negative predictions inside the potential rather than outside as in equation (3). If you remove the truncation, the proof becomes easy.
Trying to adapt directly KT to obtain this kind of guarantees is not a good idea: you quickly loose the closed form expression. Indeed, KT is nothing else than FTRL with certain losses and a certain regularizer. You can use the same FTRL strategy if the coin is “continuous”, but you don’t have a closed form anymore.
LikeLike
Cool, thanks! You are probably already aware of it but there’s also a “dual” view of KT for experts from an exponential weights point of view in http://proceedings.mlr.press/v75/hoeven18a/hoeven18a.pdf
LikeLiked by 1 person
Nice post! Your work on parameter-free online learning is rather impressive! I’m curious if it is possible to develop parameter-free version of accelerated gradient descent as well?
LikeLiked by 1 person
Hi Yichi, thanks for your question!
The key point is that accelerated algorithms makes sense for smooth functions, while parameter-free algorithms make sense for non-smooth ones. In fact, with a non-smooth function the (sub)-gradient does not give any information on how far is the optimum and the setting of the learning rate becomes critical. Instead, in the smooth world the gradients are very informative and knowledge of the smoothness constant allows to easily optimally set the learning rate. Hence, we should first define what we mean by “parameter-free” for smooth optimization. Also, it is relatively easy to estimate smoothness. Indeed, the accelerated algorithm FISTA (https://www.math.mcgill.ca/yyang/comp/papers/FISTA.pdf) has a line-search procedure that essentially estimates the smoothness parameter. It is still non-trivial to estimate the smoothness constant in the stochastic setting, but definitely doable.
A different but related result you might be interested is that parameter-free algorithms allow you to adapt to the strong convexity (that is harder to estimate than smoothness), see section 6 in https://arxiv.org/pdf/1802.06293.pdf
LikeLike