This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019.
You can find all the lectures I published here.
In the last lecture, we introduced the Explore-Then-Commit (ETC) algorithm that solves the stochastic bandit problem, but requires the knowledge of the gaps. This time we will introduce a parameter-free strategy that achieves the same optimal regret guarantee.
1. Upper Confidence Bound Algorithm

The ETC algorithm has the disadvantage of requiring the knowledge of the gaps to tune the exploration phase. Moreover, it solves the exploration vs. exploitation trade-off in a clunky way. It would be better to have an algorithm that smoothly transition from one phase into the other in a data-dependent way. So, we now describe an optimal and adaptive strategy called Upper Confidence Bound (UCB) algorithm. It employs the principle of optimism in the face of uncertainty, to select in each round the arm that has the potential to be the best one.
UCB works keeping an estimate of the expected loss of each arm and also a confidence interval at a certain probability. Roughly speaking, we have that with probability at least

![\displaystyle \mu_i \in \left[\hat{\mu}_i - \sqrt{\frac{2\ln \frac{1}{\delta}}{S_{t-1,i}}}, \hat{\mu}_i\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmu_i+%5Cin+%5Cleft%5B%5Chat%7B%5Cmu%7D_i+-+%5Csqrt%7B%5Cfrac%7B2%5Cln+%5Cfrac%7B1%7D%7B%5Cdelta%7D%7D%7BS_%7Bt-1%2Ci%7D%7D%7D%2C+%5Chat%7B%5Cmu%7D_i%5Cright%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where the “roughly” comes from the fact that 
Remark 1. The name Upper Confidence Bound comes from the fact that traditionally stochastic bandits are defined over rewards, rather than losses. So, in our case we actually use the lower confidence bound in the algorithm. However, to avoid confusion with the literature, we still call it Upper Confidence Bound algorithm.
The key points in the proof are on how to choose the right confidence level 
The algorithm is summarized in Algorithm 1 and we can prove the following regret bound.
Theorem 1. Assume that the rewards of the arms are
-subgaussian and
and let

Proof: We analyze one arm at the time. Also, without loss of generality, assume that the optimal arm is the first one. For arm 
![{\mathop{\mathbb E}[S_{T,i}]\leq \frac{8\alpha \ln T}{\Delta^2_i} + \frac{\alpha}{\alpha-2}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta%5E2_i%7D+%2B+%5Cfrac%7B%5Calpha%7D%7B%5Calpha-2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The proof is based on the fact that once I have sampled an arm enough times, the probability to take a suboptimal arm is small.
Let 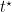




Consider 


If the first one is true, the confidence interval around our estimate of the expectation of the optimal arm does not contain 

Let’s prove the claim: if both the inequalities above are false,

that, by the selection strategy of the algorithm, would imply 
Note that 
![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[ S_{T,i}\right] &= \mathop{\mathbb E}[S_{t^\star,i}] + \sum_{t=t^\star+1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i, (2) \text{ or } (3) \text{ true}]] \\ &\leq \frac{8\alpha \ln T}{\Delta_i^2} + 1 + \sum_{t=t^\star+1}^T \mathop{\mathbb E}[\boldsymbol{1}[(2) \text{ or } (3) \text{ true}]] \\ &\leq \frac{8\alpha \ln T}{\Delta_i^2} + 1 + \sum_{t=t^\star+1}^T \left(\mathop{\mathbb P}[(2) \text{ true}] + \mathop{\mathbb P}[(3) \text{ true}]\right)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+S_%7BT%2Ci%7D%5Cright%5D+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7Bt%5E%5Cstar%2Ci%7D%5D+%2B+%5Csum_%7Bt%3Dt%5E%5Cstar%2B1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%2C+%282%29+%5Ctext%7B+or+%7D+%283%29+%5Ctext%7B+true%7D%5D%5D+%5C%5C+%26%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+1+%2B+%5Csum_%7Bt%3Dt%5E%5Cstar%2B1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5B%282%29+%5Ctext%7B+or+%7D+%283%29+%5Ctext%7B+true%7D%5D%5D+%5C%5C+%26%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+1+%2B+%5Csum_%7Bt%3Dt%5E%5Cstar%2B1%7D%5ET+%5Cleft%28%5Cmathop%7B%5Cmathbb+P%7D%5B%282%29+%5Ctext%7B+true%7D%5D+%2B+%5Cmathop%7B%5Cmathbb+P%7D%5B%283%29+%5Ctext%7B+true%7D%5D%5Cright%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we upper bound the probabilities in the sum. Given that the losses on the arms are i.i.d. and using the union bound, we have
![\displaystyle \begin{aligned} \mathop{\mathbb P} \left[\hat{\mu}_{t-1,1} - \sqrt{\frac{2\alpha \ln t}{S_{t-1,1}}} \geq \mu_1 \right] &\leq \mathop{\mathbb P} \left[\max_{s=1, \dots, t-1} \ \frac{1}{s}\sum_{j=1}^s g_{j,1} - \sqrt{\frac{2\alpha \ln t}{s}} \geq \mu_1\right] \\ &= \mathop{\mathbb P}\left[\bigcup_{s=1}^{t-1} \left\{\frac{1}{s}\sum_{j=1}^s g_{j,1} - \sqrt{\frac{2\alpha \ln t}{s}} \geq \mu_1\right\}\right]~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D++%5Cmathop%7B%5Cmathbb+P%7D+%5Cleft%5B%5Chat%7B%5Cmu%7D_%7Bt-1%2C1%7D+-+%5Csqrt%7B%5Cfrac%7B2%5Calpha+%5Cln+t%7D%7BS_%7Bt-1%2C1%7D%7D%7D+%5Cgeq+%5Cmu_1+%5Cright%5D+%26%5Cleq+%5Cmathop%7B%5Cmathbb+P%7D+%5Cleft%5B%5Cmax_%7Bs%3D1%2C+%5Cdots%2C+t-1%7D+%5C+%5Cfrac%7B1%7D%7Bs%7D%5Csum_%7Bj%3D1%7D%5Es+g_%7Bj%2C1%7D+-+%5Csqrt%7B%5Cfrac%7B2%5Calpha+%5Cln+t%7D%7Bs%7D%7D+%5Cgeq+%5Cmu_1%5Cright%5D+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B%5Cbigcup_%7Bs%3D1%7D%5E%7Bt-1%7D+%5Cleft%5C%7B%5Cfrac%7B1%7D%7Bs%7D%5Csum_%7Bj%3D1%7D%5Es+g_%7Bj%2C1%7D+-+%5Csqrt%7B%5Cfrac%7B2%5Calpha+%5Cln+t%7D%7Bs%7D%7D+%5Cgeq+%5Cmu_1%5Cright%5C%7D%5Cright%5D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, we have
![\displaystyle \begin{aligned} \mathop{\mathbb P}[(2) \text{ true} ] &\leq \sum_{s=1}^{t-1} \mathop{\mathbb P}\left[\frac{1}{s}\sum_{j=1}^s g_{j,1} - \sqrt{\frac{2\alpha \ln t}{s}} \geq \mu_1\right] \qquad \text{(union bound)}\\ &\leq \sum_{s=1}^{t-1} t^{-\alpha} = (t-1) t^{-\alpha}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+P%7D%5B%282%29+%5Ctext%7B+true%7D+%5D+%26%5Cleq+%5Csum_%7Bs%3D1%7D%5E%7Bt-1%7D+%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B%5Cfrac%7B1%7D%7Bs%7D%5Csum_%7Bj%3D1%7D%5Es+g_%7Bj%2C1%7D+-+%5Csqrt%7B%5Cfrac%7B2%5Calpha+%5Cln+t%7D%7Bs%7D%7D+%5Cgeq+%5Cmu_1%5Cright%5D+%5Cqquad+%5Ctext%7B%28union+bound%29%7D%5C%5C+%26%5Cleq+%5Csum_%7Bs%3D1%7D%5E%7Bt-1%7D+t%5E%7B-%5Calpha%7D+%3D+%28t-1%29+t%5E%7B-%5Calpha%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Given that the same bound holds for ![{\mathop{\mathbb P}[(3) \text{ true}]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D%5B%283%29+%5Ctext%7B+true%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[ S_{T,i}\right] &\leq \frac{8\alpha \ln T}{\Delta_i^2} + 1 + \sum_{t=1}^{\infty} 2 (t-1) t^{-\alpha} \\ &\leq \frac{8\alpha \ln T}{\Delta_i^2} + 1 + \sum_{t=2}^{\infty} 2 t^{1-\alpha} \\ &\leq \frac{8\alpha \ln T}{\Delta_i^2} + 1 + 2\int_{1}^{\infty} x^{1-\alpha}\\ &=\frac{8\alpha \ln T}{\Delta_i^2} + \frac{\alpha}{\alpha-2}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+S_%7BT%2Ci%7D%5Cright%5D+%26%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+1+%2B+%5Csum_%7Bt%3D1%7D%5E%7B%5Cinfty%7D+2+%28t-1%29+t%5E%7B-%5Calpha%7D+%5C%5C+%26%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+1+%2B+%5Csum_%7Bt%3D2%7D%5E%7B%5Cinfty%7D+2+t%5E%7B1-%5Calpha%7D+%5C%5C+%26%5Cleq+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+1+%2B+2%5Cint_%7B1%7D%5E%7B%5Cinfty%7D+x%5E%7B1-%5Calpha%7D%5C%5C+%26%3D%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D+%2B+%5Cfrac%7B%5Calpha%7D%7B%5Calpha-2%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Using the decomposition of the regret we proved last time, ![{\text{Regret}_T=\sum_{i=1}^d \Delta_i \mathop{\mathbb E}[S_{T,i}]}](https://s0.wp.com/latex.php?latex=%7B%5Ctext%7BRegret%7D_T%3D%5Csum_%7Bi%3D1%7D%5Ed+%5CDelta_i+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

It is instructive to observe an actual run of the algorithm. I have considered 5 arms and Gaussian losses. In the left plot of figure below, I have plotted how the estimates and confidence intervals of UCB varies over time (in blue), compared to the actual true means (in black). In the right side, you can see the number of times each arm was pulled by the algorithm.
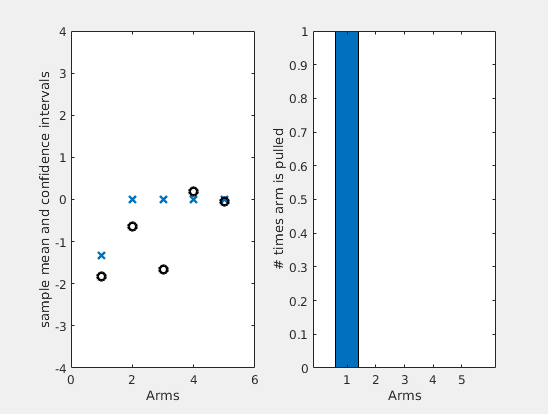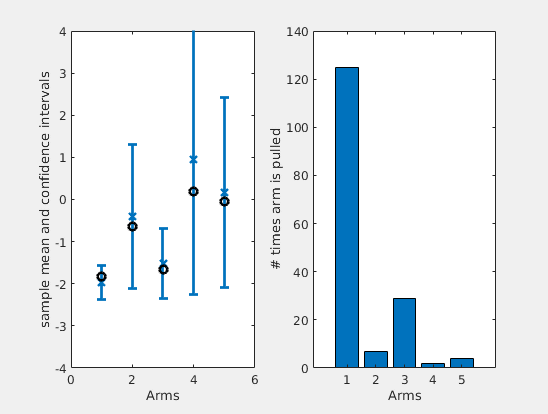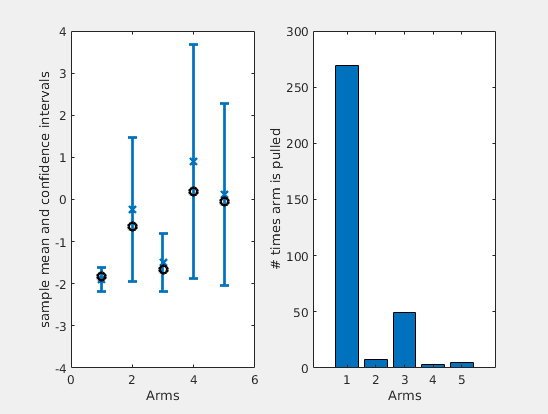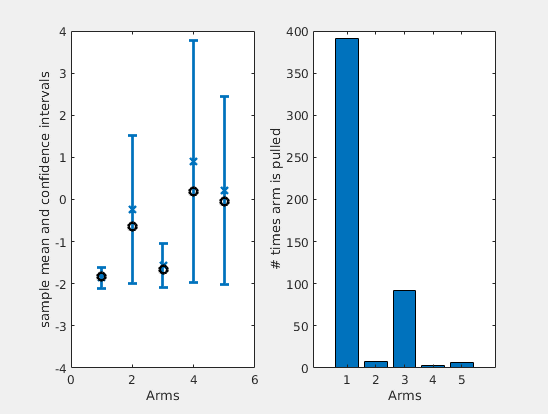
It is interesting to note that the logarithmic factor in the confidence term will make the confidences of the arm that are not pulled to increase over time. In turn, this will assure that the algorithm does not miss the optimal arm, even if the estimates were off. Also, the algorithm will keep pulling the two arms that are close together, to be sure on which one is the best among the two.
The bound above can become meaningless if the gaps are too small. So, here we prove another bound that does not depend on the inverse of the gaps.
Theorem 2. Assume that the rewards of the arms minus their expectations are
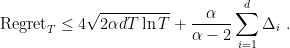
Proof: Let 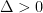
![\displaystyle \mathop{\mathbb E}[S_{T,i}] \leq \frac{\alpha}{\alpha-2} + \frac{8\alpha \ln T}{\Delta_i^2}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D+%5Cleq+%5Cfrac%7B%5Calpha%7D%7B%5Calpha-2%7D+%2B+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%5E2%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, using the regret decomposition we proved last time, we have
![\displaystyle \begin{aligned} \text{Regret}_T &= \sum_{i:\Delta_i < \Delta} \Delta_i \mathop{\mathbb E}[S_{T,i}] + \sum_{i:\Delta_i \geq \Delta} \Delta_i \mathop{\mathbb E}[S_{T,i}] \\ &\leq T\Delta + \sum_{i:\Delta_i \geq \Delta} \Delta_i \mathop{\mathbb E}[S_{T,i}] \\ &\leq T\Delta + \sum_{i:\Delta_i \geq \Delta} \left(\Delta_i \frac{\alpha}{\alpha-2} + \frac{8\alpha \ln T}{\Delta_i}\right) \\ &\leq T\Delta + \frac{\alpha}{\alpha-2} \sum_{i=1}^d \Delta_i + \frac{8\alpha d \ln T}{\Delta}~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctext%7BRegret%7D_T+%26%3D+%5Csum_%7Bi%3A%5CDelta_i+%3C+%5CDelta%7D+%5CDelta_i+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D+%2B+%5Csum_%7Bi%3A%5CDelta_i+%5Cgeq+%5CDelta%7D+%5CDelta_i+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D+%5C%5C+%26%5Cleq+T%5CDelta+%2B+%5Csum_%7Bi%3A%5CDelta_i+%5Cgeq+%5CDelta%7D+%5CDelta_i+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D+%5C%5C+%26%5Cleq+T%5CDelta+%2B+%5Csum_%7Bi%3A%5CDelta_i+%5Cgeq+%5CDelta%7D+%5Cleft%28%5CDelta_i+%5Cfrac%7B%5Calpha%7D%7B%5Calpha-2%7D+%2B+%5Cfrac%7B8%5Calpha+%5Cln+T%7D%7B%5CDelta_i%7D%5Cright%29+%5C%5C+%26%5Cleq+T%5CDelta+%2B+%5Cfrac%7B%5Calpha%7D%7B%5Calpha-2%7D+%5Csum_%7Bi%3D1%7D%5Ed+%5CDelta_i+%2B+%5Cfrac%7B8%5Calpha+d+%5Cln+T%7D%7B%5CDelta%7D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Choosing 
Remark 2. Note that while the UCB algorithm is considered parameter-free, we still have to know the subgaussianity of the arms. While this can be easily upper bounded for stochastic arms with bounded support, it is unclear how to do it without any prior knowledge on the distribution of the arms.
It is possible to prove that the UCB algorithm is asymptotically optimal, in the sense of the following Theorem.
Theorem 3 (Bubeck, S. and Cesa-Bianchi, N. , 2012, Theorem 2.2). Consider a strategy that satisfies
for any set of Bernoulli rewards distributions, any arm
and any
. Then, for any set of Bernoulli reward distributions, the following holds

2. History Bits
The use of confidence bounds and the idea of optimism first appeared in the work by (T. L. Lai and H. Robbins, 1985). The first version of UCB is by (T. L. Lai, 1987). The version of UCB I presented is by (P. Auer and N. Cesa-Bianchi and P. Fischer, 2002) under the name UCB1. Note that, rather than considering 1-subgaussian environments, (P. Auer and N. Cesa-Bianchi and P. Fischer, 2002) considers bandits where the rewards are confined to the ![{[0, 1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
3. Exercises
Exercise 1. Prove a similar regret bound to the one in Theorem 2 for an optimally tuned Explore-Then-Commit algorithm.

EDIT: Fixed a small bug in the proof of UCB found by Daniel Hsu
LikeLike