This is the first of three posts to show that online learning is more than just online learning!
Each of these posts will show how we can go from online learning to X, where X will be something completely unrelated to online learning. These results are based on the fact that a linear regret proof in its essence is a statement about arbitrary sequence of vectors, so it can be used in other settings as well.
These results I’ll show in these posts are not new, but somehow not so widely known as they should be.
1. From Linear Regret to Rademacher Complexity
Previously, we used online-to-batch conversions to turn regret bounds into guarantees on the risk. A different (and extremely useful) way to quantify the statistical difficulty of a hypothesis class is through its Rademacher complexity. It measures how well the class can correlate with pure noise, and it is the key quantity behind many uniform convergence and generalization results. Here, we show a simple reduction that upper bounds the Rademacher complexity of a class using the regret guarantee of an online learning algorithm.
We consider the Vapnik’s general setting of learning for generic function classes. Hence, we seek to minimize
![\displaystyle \label{eq:vapnik_general_obj} \min_{f \in \mathcal{F}} \ \mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho} [f({\boldsymbol \xi})] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Avapnik_general_obj%7D+%5Cmin_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D+%5C+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D+%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 





It is now natural to ask if 
One way to study this problem is through the concept of Rademacher complexity of a function class.
Definition 1 (Rademacher complexity). Let
be an arbitrary set of
be i.i.d. Rademacher random variables, that is
. The empirical Rademacher complexity of
is defined as
![\displaystyle \label{eq:emp_rad} \widehat{\mathfrak{R}}_{\mathcal{T}}(\mathcal{F}) \stackrel{\text{def}}{=} \frac{1}{T}\, \mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\left[ \sup_{f\in\mathcal{F}} \ \sum_{t=1}^T \epsilon_t f({\boldsymbol \xi}_t)\right]~. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Aemp_rad%7D+%5Cwidehat%7B%5Cmathfrak%7BR%7D%7D_%7B%5Cmathcal%7BT%7D%7D%28%5Cmathcal%7BF%7D%29+%5Cstackrel%7B%5Ctext%7Bdef%7D%7D%7B%3D%7D+%5Cfrac%7B1%7D%7BT%7D%5C%2C+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B+%5Csup_%7Bf%5Cin%5Cmathcal%7BF%7D%7D+%5C+%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+f%28%7B%5Cboldsymbol+%5Cxi%7D_t%29%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
Intuitively, if 
This idea can be made formal and yields generalization guarantees; for example, bounds of the form
![\displaystyle \sup_{f\in\mathcal{F}} \ \left| \mathop{\mathbb E}[f({\boldsymbol \xi})] - \frac{1}{T}\sum_{t=1}^T f({\boldsymbol \xi}_t) \right| \lesssim \widehat{\mathfrak{R}}_{\mathcal{T}}(\mathcal{F}) + \sqrt{\frac{\ln(1/\delta)}{T}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csup_%7Bf%5Cin%5Cmathcal%7BF%7D%7D+%5C+%5Cleft%7C+%5Cmathop%7B%5Cmathbb+E%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D+-+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+f%28%7B%5Cboldsymbol+%5Cxi%7D_t%29+%5Cright%7C+%5Clesssim+%5Cwidehat%7B%5Cmathfrak%7BR%7D%7D_%7B%5Cmathcal%7BT%7D%7D%28%5Cmathcal%7BF%7D%29+%2B+%5Csqrt%7B%5Cfrac%7B%5Cln%281%2F%5Cdelta%29%7D%7BT%7D%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
with probability at least 
Moreover, one can easily obtain a generalization guarantee that depends 

We will not prove such results here; instead, we focus on the following question: how can we upper bound
Here, we consider function classes given by composing Lipschitz functions with linear predictors. A typical example is: Given a prediction function class 
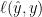

where 




Lemma 2 (Contraction Lemma). Let
be
. Then, for any sample

Hence, in our setting it suffices to control the complexity of linear functions, which we do next.
2. Rademacher Complexity of Linear Classes through Regret Guarantees
We now state the core reduction. Let 

Fix a sample 

Theorem 3. Let
such that for any
we also have
. Fix any sequence
and any non-empty, bounded, closed set
, where
, produces
and satisfies the regret guarantee
Then, the empirical Rademacher complexity of the linear class satisfies

![\displaystyle \label{eq:rad_bound_linear} \widehat{\mathfrak{R}}_{\mathcal{T}}(\mathcal{F}_{\mathrm{lin}}) = \frac{1}{T} \mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\left[ \sup_{{\boldsymbol x}\in\mathcal{V}}\ \sum_{t=1}^T \epsilon_t \langle {\boldsymbol x},{\boldsymbol z}_t\rangle \right] \leq \frac{R(T)}{T}~. \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Arad_bound_linear%7D+%5Cwidehat%7B%5Cmathfrak%7BR%7D%7D_%7B%5Cmathcal%7BT%7D%7D%28%5Cmathcal%7BF%7D_%7B%5Cmathrm%7Blin%7D%7D%29+%3D+%5Cfrac%7B1%7D%7BT%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B+%5Csup_%7B%7B%5Cboldsymbol+x%7D%5Cin%5Cmathcal%7BV%7D%7D%5C+%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D%2C%7B%5Cboldsymbol+z%7D_t%5Crangle+%5Cright%5D+%5Cleq+%5Cfrac%7BR%28T%29%7D%7BT%7D%7E.+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Fix 




Rearranging, we get

Taking expectation with respect to
![\displaystyle \label{eq:rad_exp_split} \widehat{\mathfrak{R}}_{\mathcal{T}}(\mathcal{F}_{\mathrm{lin}}) \leq \frac{R(T)}{T} + \frac{1}{T}\mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\left[\sum_{t=1}^T \epsilon_t \langle {\boldsymbol x}_t,{\boldsymbol z}_t\rangle\right]~. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Arad_exp_split%7D+%5Cwidehat%7B%5Cmathfrak%7BR%7D%7D_%7B%5Cmathcal%7BT%7D%7D%28%5Cmathcal%7BF%7D_%7B%5Cmathrm%7Blin%7D%7D%29+%5Cleq+%5Cfrac%7BR%28T%29%7D%7BT%7D+%2B+%5Cfrac%7B1%7D%7BT%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+z%7D_t%5Crangle%5Cright%5D%7E.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
It remains to show that the second term is 



![\displaystyle \mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\!\left[\epsilon_t \langle {\boldsymbol x}_t,{\boldsymbol z}_t\rangle \middle| \epsilon_1,\dots,\epsilon_{t-1}, \text{internal randomness}\right] = \langle {\boldsymbol x}_t,{\boldsymbol z}_t\rangle\,\mathop{\mathbb E}[\epsilon_t] =0,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5C%21%5Cleft%5B%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+z%7D_t%5Crangle+%5Cmiddle%7C+%5Cepsilon_1%2C%5Cdots%2C%5Cepsilon_%7Bt-1%7D%2C+%5Ctext%7Binternal+randomness%7D%5Cright%5D+%3D+%5Clangle+%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+z%7D_t%5Crangle%5C%2C%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cepsilon_t%5D+%3D0%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and by taking expectation again we obtain ![{\mathop{\mathbb E}[\epsilon_t \langle {\boldsymbol x}_t,{\boldsymbol z}_t\rangle]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+z%7D_t%5Crangle%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\left[\sum_{t=1}^T \epsilon_t \langle {\boldsymbol x}_t,{\boldsymbol z}_t\rangle\right]=0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D_t%2C%7B%5Cboldsymbol+z%7D_t%5Crangle%5Cright%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Remark 1. The proof of Theorem 3 has the same flavor as the probabilistic method argument used in lower bounds: we introduce Rademacher signs, feed them to an online algorithm, and then exploit the fact that the algorithm cannot correlate with the fresh randomness at time
.
We can instantiate the above theorem using the Online Mirror Descent (OMD) algorithms with 
Corollary 4. Let
and
such that
. For
, let
. Let
where
and
for
. Let
. Then,
![\displaystyle \frac{1}{T} \mathop{\mathbb E}_{\epsilon_1, \dots, \epsilon_T}\left[ \sup_{{\boldsymbol x}\in\mathcal{V}_p} \ \sum_{t=1}^T \epsilon_t \langle {\boldsymbol x},{\boldsymbol z}_t\rangle \right] \leq \frac{U_p G_q}{\sqrt{(p-1)T}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7BT%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C+%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B+%5Csup_%7B%7B%5Cboldsymbol+x%7D%5Cin%5Cmathcal%7BV%7D_p%7D+%5C+%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+%5Clangle+%7B%5Cboldsymbol+x%7D%2C%7B%5Cboldsymbol+z%7D_t%5Crangle+%5Cright%5D+%5Cleq+%5Cfrac%7BU_p+G_q%7D%7B%5Csqrt%7B%28p-1%29T%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We instantiate Theorem 3 with OMD with 

We can also consider the case of classes of functions with finite cardinality.
Corollary 5 (Massart’s Lemma). Let
for
. Then,
![\displaystyle \frac{1}{T} \mathop{\mathbb E}_{\epsilon_1,\dots, \epsilon_T}\left[ \max_{i=1,\dots, d} \ \sum_{t=1}^T \epsilon_t z_{t,i}\right] \leq \frac{G_\infty \sqrt{2 \ln d}}{\sqrt{T}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7BT%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cepsilon_1%2C%5Cdots%2C+%5Cepsilon_T%7D%5Cleft%5B+%5Cmax_%7Bi%3D1%2C%5Cdots%2C+d%7D+%5C+%5Csum_%7Bt%3D1%7D%5ET+%5Cepsilon_t+z_%7Bt%2Ci%7D%5Cright%5D+%5Cleq+%5Cfrac%7BG_%5Cinfty+%5Csqrt%7B2+%5Cln+d%7D%7D%7B%5Csqrt%7BT%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We instantiate Theorem 3 with OMD with entropic regularizer, learning rate 
![{{\boldsymbol x}_1=[1/d, \dots, 1/d]^\top}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+x%7D_1%3D%5B1%2Fd%2C+%5Cdots%2C+1%2Fd%5D%5E%5Ctop%7D&bg=ffffff&fg=000000&s=0&c=20201002)
3. History Bits
The contraction lemma appears in many places in the literature (see, e.g., Ledoux&Talagrand, 1991, Bartlett&Mendelson, 2001, Bartlett&Mendelson, 2002, Meir&Zhang, 2003).
Kakade et al. (2008) proved Theorem 3 using strong convexity, while Kakade et al. (2009) proved it through the proof of FTRL. Here, we simply used a black-box conversion to the linear regret upper bound for any online learning algorithm.
Massart’s lemma was originally proved by Massart (2000).
Acknowledgments
Thanks to ChatGPT for checking my post.
