In this post, we will see how to extend the notion of regret to a sequence of comparators instead of a single one. We saw that the definition of regret makes sense as a direct generalization of both the stochastic setting and the offline optimization. However, in some cases, we know that the environment is changing over time, so we would like an algorithm that guarantees a stronger notion of regret that captures the dynamics of the environment.
Our first extension is to use multiple comparators, using the concept of dynamic regret, defined as

where 

Is it possible to obtain sublinear dynamic regret? We already know that in the case that 



where 


1. Dynamic Regret of Online Mirror Descent
It turns out that some online learning algorithm already satisfies a dynamic regret without any additional change. For Online Mirror Descent (OMD), we can state the following theorem.
Theorem 1. Let
the Bregman divergence w.r.t.
and assume
to be closed and
-strongly convex with respect to
in
. Let
a non-empty closed convex set. Assume that
for
. Then,
, OMD with constant learning rate
satisfies
where
.

Proof: From the one-step inequality for OMD with competitor

Dividing by

Now observe that

Hence, we have

Putting it all together, we have

Assuming that 

Assuming 


In other words, we suffer an additional regret of

compared to the static case, for any
Example 1. Consider the case that the feasible is has diameter
with respect to the L2 norm, i.e.,
. Set
and assume the subgradients to satisfy
for
and setting
we have

Could we obtain a better regret guarantee? We could set the learning rate to 

However, assuming the knowledge of the exact value of 

2. ADER: Optimal Dependency on the Path Length for Online Subgradient Descent
In the previous section, we saw that the algorithm needs to know the path length of the competitors to tune its learning rate. Here, we show how to construct an online learning algorithm that achieves the same guarantees up to polylogarithmic terms. For simplicity, we will consider the Euclidean case, but it is easy to extend it to the Bregman case. Moreover, we assume the losses to be 
We will use a classic online learning method: to run in parallel many projected Online Gradient Descent (OGD) algorithms with different learning rates and use an Exponentiated Gradient algorithm (EG) to learn online the best combination of their iterates. In this way, we will show that the cumulative loss of the resulting algorithm is close to the cumulative loss of the best learning rate, which in turn will give us the right dependency on the path length.

Consider a feasible set 
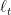

Using the fact that 


So, consider a grid of 



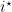

To combine the OGD algorithms with different learning rates, we use the EG algorithm where the OGD algorithms are our experts. We construct the loss vector for EG as ![{{\boldsymbol z}_t = [\ell_t({\boldsymbol x}^{(1)}_{t}), \dots, \ell_t({\boldsymbol x}^{(N)}_{t})]^\top}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cboldsymbol+z%7D_t+%3D+%5B%5Cell_t%28%7B%5Cboldsymbol+x%7D%5E%7B%281%29%7D_%7Bt%7D%29%2C+%5Cdots%2C+%5Cell_t%28%7B%5Cboldsymbol+x%7D%5E%7B%28N%29%7D_%7Bt%7D%29%5D%5E%5Ctop%7D&bg=ffffff&fg=000000&s=0&c=20201002)




Now observe that by Jensen’s inequality and the convexity of

This motivates the choice of using a convex combination of the predictions of the OGD algorithms. Moreover, we have 
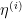

Putting it all together, we have

We are still not completely done: This construction above queries 
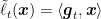


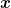


Hence, a dynamic regret guarantee on 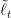
Theorem 2. Let
be a non-empty closed convex set with bounded diameter with respect to the L2 norm equal to
to be convex functions subdifferentiable in

Note that while we query only one subgradient per round, the computational complexity of ADER per round is still 

3. History Bits
Herbster&Warmuth (1998) introduced the idea of tracking the best expert in learning with experts game. In this setting, the best expert is allowed to change at most 

Theorem 1 is a generalization of Cesa-Bianchi&Lugosi (2006, Theorem 11.4) to arbitrary distance generating functions and considering Lipschitz losses. Also, following Jacobsen&Cutkosky (2022, Lemma 4), I have fixed the offset in the proof so that we do not have to assume that 
Zhang et al. (2018) designed the ADER algorithm and they also proved that it is optimal in bounded domains. The idea of combining online algorithms with different learning rates comes directly from the MetaGrad algorithm (van Erven&Koolen, 2016, van Erven et al., 2021) which also showed how to query a single gradient per round. In turn, MetaGrad is based on prior work using a grid of learning rates in EG (Koolen et al., 2014). By now, this is a well-known method that allows us to solve essentially all problems of tuning learning rates in bounded domains, at least theoretically. One can also combine different learning rates in unbounded domains, with a multi-scale expert algorithm (Foster et al., 2017, Cutkosky&Orabona, 2018). This method can be considered a better “doubling trick” because it allows tracking non-monotonic quantities at the price of a logarithmic computational overhead. It is worth also stressing that the general idea of combining the outputs of different online learning algorithms through another online learning algorithm is instead much older, and it goes back at least to Blum&Mansour (2005), Blum&Mansour (2007).
I described a slightly simpler version of ADER with a flat prior, see Exercise 1 for the original bound. I also removed the unnecessary assumption that
Acknowledgements
Thanks to Nicolò Campolongo for telling me about the papers by Blum and Mansour.
4. Exercises
Exercise 1. Change the prior in the EG algorithm to obtain a dependency of
instead of
. In this way, if the path length is zero, that is we are in the static case, the regret is
instead of
, when
.
