This post is part of the lecture notes of my class “Introduction to Online Learning” at Boston University, Fall 2019. I will publish two lectures per week.
You can find the lectures I published till now here.
Today, we will consider the stochastic bandit setting. Here, each arm is associated with an unknown probability distribution. At each time step, the algorithm selects one arm 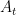

![\displaystyle \text{Regret}_T :=\mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,A_t}\right] - \min_{i=1,\dots,d} \ \mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,i}\right] =\mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,A_t}\right] - \min_{i=1,\dots,d} \ \mu_i,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BRegret%7D_T+%3A%3D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D%5Cright%5D+-+%5Cmin_%7Bi%3D1%2C%5Cdots%2Cd%7D+%5C+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2Ci%7D%5Cright%5D+%3D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D%5Cright%5D+-+%5Cmin_%7Bi%3D1%2C%5Cdots%2Cd%7D+%5C+%5Cmu_i%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where we denoted by 

Remark 1 The usual notation in the stochastic bandit literature is to consider rewards instead of losses. Instead, to keep our notation coherent with the OCO literature, we will consider losses. The two things are completely equivalent up to a multiplication by
.
Before presenting our first algorithm for stochastic bandits, we will introduce some basic notions on concentration inequalities that will be useful in our definitions and proofs.
1. Concentration Inequalities Bits
Suppose that 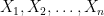
![{\mu = \mathop{\mathbb E}[X_1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5BX_1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\sigma = \mathrm{Var}[X_1]}](https://s0.wp.com/latex.php?latex=%7B%5Csigma+%3D+%5Cmathrm%7BVar%7D%5BX_1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

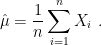
Linearity of expectation shows that ![{\mathop{\mathbb E}[\hat{\mu}] = \mu}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Chat%7B%5Cmu%7D%5D+%3D+%5Cmu%7D&bg=ffffff&fg=000000&s=0&c=20201002)
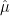
We could use Chebyshev’s inequality to upper bound the probability that
![\displaystyle \Pr[|\hat{\mu}-\mu|\geq\epsilon]\leq \frac{\mathrm{Var}[\hat{\mu}]}{\epsilon^2}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5B%7C%5Chat%7B%5Cmu%7D-%5Cmu%7C%5Cgeq%5Cepsilon%5D%5Cleq+%5Cfrac%7B%5Cmathrm%7BVar%7D%5B%5Chat%7B%5Cmu%7D%5D%7D%7B%5Cepsilon%5E2%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Using the fact that ![{\mathrm{Var}[\hat{\mu}] = \frac{\sigma^2}{n}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7BVar%7D%5B%5Chat%7B%5Cmu%7D%5D+%3D+%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \Pr[|\hat{\mu}-\mu|\geq\epsilon]\leq \frac{\sigma^2}{n \epsilon^2}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5B%7C%5Chat%7B%5Cmu%7D-%5Cmu%7C%5Cgeq%5Cepsilon%5D%5Cleq+%5Cfrac%7B%5Csigma%5E2%7D%7Bn+%5Cepsilon%5E2%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
So, we can expect the probability of having a “bad” estimate to go to zero as one over the number of samples in our empirical mean. Is this the best we can get? To understand what we can hope for, let’s take a look at the central limit theorem.
We know that, defining 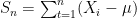


![\displaystyle \Pr[\hat{\mu}-\mu \geq \epsilon] = \Pr[S_n \geq n\epsilon] = \Pr\left[\frac{S_n}{\sqrt{2 \sigma^2}} \geq \sqrt{\frac{n}{\sigma^2}}\epsilon\right] \approx \int_{\epsilon\sqrt{\frac{n}{\sigma^2}}}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{x^2}{2}\right) dx,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5B%5Chat%7B%5Cmu%7D-%5Cmu+%5Cgeq+%5Cepsilon%5D+%3D+%5CPr%5BS_n+%5Cgeq+n%5Cepsilon%5D+%3D+%5CPr%5Cleft%5B%5Cfrac%7BS_n%7D%7B%5Csqrt%7B2+%5Csigma%5E2%7D%7D+%5Cgeq+%5Csqrt%7B%5Cfrac%7Bn%7D%7B%5Csigma%5E2%7D%7D%5Cepsilon%5Cright%5D+%5Capprox+%5Cint_%7B%5Cepsilon%5Csqrt%7B%5Cfrac%7Bn%7D%7B%5Csigma%5E2%7D%7D%7D%5E%5Cinfty+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%7D+%5Cexp%5Cleft%28-%5Cfrac%7Bx%5E2%7D%7B2%7D%5Cright%29+dx%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where the approximation comes from the central limit theorem. The integral cannot be calculated with a closed form, but we can easily upper bound it. Indeed, for 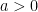

![\displaystyle \label{eq:conc_gaussian} \Pr[\hat{\mu}-\mu \geq \epsilon] \lessapprox \sqrt{\frac{\sigma^2}{2 \pi \epsilon^2 n}} \exp\left(-\frac{n \epsilon^2}{2 \sigma^2}\right)~. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Aconc_gaussian%7D+%5CPr%5B%5Chat%7B%5Cmu%7D-%5Cmu+%5Cgeq+%5Cepsilon%5D+%5Clessapprox+%5Csqrt%7B%5Cfrac%7B%5Csigma%5E2%7D%7B2+%5Cpi+%5Cepsilon%5E2+n%7D%7D+%5Cexp%5Cleft%28-%5Cfrac%7Bn+%5Cepsilon%5E2%7D%7B2+%5Csigma%5E2%7D%5Cright%29%7E.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
This is better than what we got with Chebyshev’s inequality and we would like to obtain an exact bound with a similar asymptotic rate. To do that, we will focus our attention on subgaussian random variables.
Definition 1 We say that a random variable is
–subgaussian if for all
we have that
.
Example 1 The following random variable are subgaussian:
- If
is Gaussian with mean zero and variance
, then
- If
almost surely, then
-subgaussian.
We have the following properties for subgaussian random variables.
Lemma 2 (Lattimore and Szepesvári, 2018, Lemma 5.4) Assume that
and
are independent and
-subgaussian and
-subgaussian respectively. Then,
= 0 and
.
is
-subgaussian.
is
-subgaussian.
Subgaussians random variables behaves like Gaussian random variables, in the sense that their tail probabilities are upper bounded by the ones of a Gaussian of variance
Theorem 3 (Markov’s inequality) For a non-negative random variable
, we have that
.
With Markov’s inequality, we can now formalize the above statement on subgaussian random variables.
![{\Pr[X\geq \epsilon] \leq \exp\left(-\frac{\epsilon^2}{2\sigma^2}\right)}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5BX%5Cgeq+%5Cepsilon%5D+%5Cleq+%5Cexp%5Cleft%28-%5Cfrac%7B%5Cepsilon%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
. Proof: For any 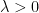
![\displaystyle \begin{aligned} \Pr[X\geq \epsilon] = \Pr[\exp(\lambda X)\geq \exp(\lambda\epsilon)] \leq \frac{\mathop{\mathbb E}[\exp(\lambda X)]}{\exp(\lambda \epsilon)} \leq \exp(\lambda^2 \sigma^2/2-\lambda \epsilon)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5CPr%5BX%5Cgeq+%5Cepsilon%5D+%3D+%5CPr%5B%5Cexp%28%5Clambda+X%29%5Cgeq+%5Cexp%28%5Clambda%5Cepsilon%29%5D+%5Cleq+%5Cfrac%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cexp%28%5Clambda+X%29%5D%7D%7B%5Cexp%28%5Clambda+%5Cepsilon%29%7D+%5Cleq+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2-%5Clambda+%5Cepsilon%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Minimizing the right hand side of the inequality w.r.t. 

An easy consequence of the above theorem is that the empirical average of subgaussian random variables concentrates around its expectation, with the same asymptotic rate in (1).
Corollary 5 Assume that
are independent,
, we have
where
.
![\displaystyle \begin{aligned} \Pr\left[\hat{\mu} \geq \mu + \epsilon\right] \leq \exp\left(- \frac{n \epsilon^2}{2\sigma^2}\right) &&\text{ and }&& \Pr\left[\hat{\mu} \leq \mu - \epsilon\right] \leq \exp\left(- \frac{n \epsilon^2}{2\sigma^2}\right), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D+%5Cgeq+%5Cmu+%2B+%5Cepsilon%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28-+%5Cfrac%7Bn+%5Cepsilon%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%29+%26%26%5Ctext%7B+and+%7D%26%26+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D+%5Cleq+%5Cmu+-+%5Cepsilon%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28-+%5Cfrac%7Bn+%5Cepsilon%5E2%7D%7B2%5Csigma%5E2%7D%5Cright%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Equating the upper bounds on the r.h.s. of the inequalities in the Corollary to 

![\displaystyle \mu \in \left[\hat{\mu}-\sqrt{\frac{2 \sigma^2\ln\frac{1}{\delta}}{n}}, \hat{\mu}+\sqrt{\frac{2 \sigma^2\ln\frac{1}{\delta}}{n}}\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmu+%5Cin+%5Cleft%5B%5Chat%7B%5Cmu%7D-%5Csqrt%7B%5Cfrac%7B2+%5Csigma%5E2%5Cln%5Cfrac%7B1%7D%7B%5Cdelta%7D%7D%7Bn%7D%7D%2C+%5Chat%7B%5Cmu%7D%2B%5Csqrt%7B%5Cfrac%7B2+%5Csigma%5E2%5Cln%5Cfrac%7B1%7D%7B%5Cdelta%7D%7D%7Bn%7D%7D%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
2. Explore-Then-Commit Algorithm

We are now ready to present the most natural algorithm for the stochastic bandit setting, called Explore-Then-Commit (ETC) algorithm. That is, we first identify the best arm over 
In the following, we will denote by ![{S_{t,i}=\sum_{j=1}^t \boldsymbol{1}[A_t=i]}](https://s0.wp.com/latex.php?latex=%7BS_%7Bt%2Ci%7D%3D%5Csum_%7Bj%3D1%7D%5Et+%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Define by 

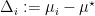
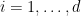
Lemma 6 For any policy of selection of the arms, the regret is upper bounded by
![\displaystyle \text{Regret}_T = \sum_{i=1}^d \mathop{\mathbb E}[S_{T,i}] \Delta_i~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BRegret%7D_T+%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Cmathop%7B%5Cmathbb+E%7D%5BS_%7BT%2Ci%7D%5D+%5CDelta_i%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Observe that
![\displaystyle \sum_{t=1}^T g_{t,A_t} = \sum_{t=1}^T \sum_{i=1}^d g_{t,i} \boldsymbol{1}[A_t=i]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D+%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Csum_%7Bi%3D1%7D%5Ed+g_%7Bt%2Ci%7D+%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence,
![\displaystyle \begin{aligned} \text{Regret}_T &= \mathop{\mathbb E}\left[\sum_{t=1}^T g_{t,A_t}\right] - T \mu^\star = \mathop{\mathbb E}\left[\sum_{t=1}^T (g_{t,A_t}- \mu^\star)\right] = \sum_{i=1}^d \sum_{t=1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i](g_{t,i}-\mu^\star)] \\ &= \sum_{i=1}^d \sum_{t=1}^T \mathop{\mathbb E}[\mathop{\mathbb E}[\boldsymbol{1}[A_t=i](g_{t,i}- \mu^\star)|A_t]] = \sum_{i=1}^d \sum_{t=1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i] \mathop{\mathbb E}[g_{t,i} - \mu^\star |A_t]] \\ &= \sum_{i=1}^d \sum_{t=1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i] (\mu_{A_t}- \mu^\star)] = \sum_{i=1}^d \sum_{t=1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i]] (\mu_i- \mu^\star)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctext%7BRegret%7D_T+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+g_%7Bt%2CA_t%7D%5Cright%5D+-+T+%5Cmu%5E%5Cstar+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D1%7D%5ET+%28g_%7Bt%2CA_t%7D-+%5Cmu%5E%5Cstar%29%5Cright%5D+%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%28g_%7Bt%2Ci%7D-%5Cmu%5E%5Cstar%29%5D+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%28g_%7Bt%2Ci%7D-+%5Cmu%5E%5Cstar%29%7CA_t%5D%5D+%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D+%5Cmathop%7B%5Cmathbb+E%7D%5Bg_%7Bt%2Ci%7D+-+%5Cmu%5E%5Cstar+%7CA_t%5D%5D+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D+%28%5Cmu_%7BA_t%7D-+%5Cmu%5E%5Cstar%29%5D+%3D+%5Csum_%7Bi%3D1%7D%5Ed+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5D+%28%5Cmu_i-+%5Cmu%5E%5Cstar%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The above Lemma quantifies the intuition that in order to have a small regret we have to select the suboptimal arms less often then the best one.
We are now ready to prove the regret guarantee of the ETC algorithm.
Theorem 7 Assume that the losses of the arms minus their expectations are
-subgaussian and
. Then, ETC guarantees a regret of

Proof: Let’s assume without loss of generality that the optimal arm is the first one.
So, for 
![\displaystyle \begin{aligned} \sum_{t=1}^T \mathop{\mathbb E}[\boldsymbol{1}[A_t=i]] &= m + (T-m d) \Pr\left[\hat{\mu}_{md,i} \leq \min_{j\geq i} \ \hat{\mu}_{md,j}\right] \\ &\leq m + (T-m d) \Pr\left[\hat{\mu}_{md,i} \leq \hat{\mu}_{md,1}\right]\\ &=m + (T-m d) \Pr\left[\hat{\mu}_{md,1}-\mu_1-(\hat{\mu}_{md,i} -\mu_i)\geq \Delta_i\right]~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cboldsymbol%7B1%7D%5BA_t%3Di%5D%5D+%26%3D+m+%2B+%28T-m+d%29+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D_%7Bmd%2Ci%7D+%5Cleq+%5Cmin_%7Bj%5Cgeq+i%7D+%5C+%5Chat%7B%5Cmu%7D_%7Bmd%2Cj%7D%5Cright%5D+%5C%5C+%26%5Cleq+m+%2B+%28T-m+d%29+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D_%7Bmd%2Ci%7D+%5Cleq+%5Chat%7B%5Cmu%7D_%7Bmd%2C1%7D%5Cright%5D%5C%5C+%26%3Dm+%2B+%28T-m+d%29+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D_%7Bmd%2C1%7D-%5Cmu_1-%28%5Chat%7B%5Cmu%7D_%7Bmd%2Ci%7D+-%5Cmu_i%29%5Cgeq+%5CDelta_i%5Cright%5D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
From Lemma 2, we have that 

![\displaystyle \Pr\left[\hat{\mu}_{md,1}-\mu_1-(\hat{\mu}_{md,i} -\mu_i) \geq \Delta_i\right] \leq \exp\left(-\frac{m \Delta^2_i}{4}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%5Chat%7B%5Cmu%7D_%7Bmd%2C1%7D-%5Cmu_1-%28%5Chat%7B%5Cmu%7D_%7Bmd%2Ci%7D+-%5Cmu_i%29+%5Cgeq+%5CDelta_i%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28-%5Cfrac%7Bm+%5CDelta%5E2_i%7D%7B4%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
The bound shows the trade-off between exploration and exploitation: if 
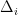
For example, in that case that 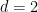

that is minimized by
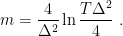
Remembering that

When 
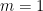


The main drawback of this algorithm is that its optimal tuning depends on the gaps 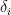
3. History Bits
The ETC algorithm goes back to (Robbins, H., 1952), even if Robbins proposed what is now called epoch-greedy (Langford, J. and Zhang, T., 2008). For more history on ETC, take a look at chapter 6 in (Lattimore, T. and Szepesvári, C., 2018). The proofs presented here are from (Lattimore, T. and Szepesvári, C., 2018) as well.

Thanks for the tutorial. May I know how you obtained \Delta + (T-2)\Delta \leq T\Delta \leq \frac{4}{\Delta} for m=1?
LikeLike
Hi Jeng, it is enough to use the condition T Delta^2/4 \leq 1.
LikeLike
Nice tutorial! Could you explain why there is an additional +\Delta in the final upper bound? When I substitute m into the bound I don’t get that extra +\Delta. Thanks in advance
LikeLike
It comes from the fact that you need to take the ceiling of the optimal value of m to obtain an integer number. Note that in the case the optimal m is 1, the +\Delta is not needed, but it is a small overapproximation to make the expression simpler.
LikeLike