We now consider online learning with delayed feedback. We consider a constant delay of length 



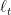



1. Delay as Bad Hints
Instead of designing online algorithms specifically for the case of delayed feedback, we will reduce the setting of online learning with delays to the one of optimistic online learning, that is, when we receive the hint 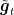



On the other hand, in Optimistic FTRL without delays and linearized losses we predict with

Hence, the two updates are equivalent if we set 
In the same way, we have that in OMD with delays we predict the same 

On the other hand, Optimistic OMD without delays updates with

where 


The above observations are very powerful because they can immediately give us the regret guarantee of FTRL and OMD with delays. Indeed, considering FTRL, assuming that the regularizer 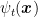


The result for OMD with delays is similar. The optimal tuning of 
Where is the problem? Is the reduction from delays to optimistic updates suboptimal? This seems unlikely, given that the reduction is exact. Instead, the problem is somewhere else: The optimistic bounds we have are suboptimal!
So, in the next two sections, we show a better bound for Optimistic OMD and Optimistic FTRL, which will imply the optimal bound for OMD and FTRL with delays.
2. Improved Optimistic OMD Bound
As we already saw, the following one is the pseudo-code of Optimistic OMD.

Note that setting 

We can now state its improved regret guarantee.
Theorem 1. Let
be the Bregman divergence with respect to
and assume
to be proper, closed, and
-strongly convex with respect to
. Let
be a non-empty closed convex set. With the notation in Algorithm 1, assume each
exists and lies in
. Assume
for
. Define
. Then,
, the following regret bounds hold
Moreover, if
is constant, i.e.,
, we have


To prove this improved theorem, we will use the following technical lemmas.
Lemma 2. Assume
to be
. Let
be convex. Let
. Then, we have

Proof: Observe that from the optimality condition on 

Hence, we have

where in first inequality we used the strong convexity of

Lemma 3. Let
and
. Then, we have
![\displaystyle \sup_{{\boldsymbol v} \in {\mathbb R}^d: \|{\boldsymbol v}\|\leq c/a} \ \langle {\boldsymbol g},{\boldsymbol v}\rangle - \frac{a}{2}\|{\boldsymbol v}\|^2 = \frac{1}{2 a } \left[\|{\boldsymbol g}\|^2_\star-\max(\|{\boldsymbol g}\|_\star-c,0)^2\right] \leq \frac{1}{2 a } \|{\boldsymbol g}\|_\star \min\left(\|{\boldsymbol g}\|_\star, 2 c \right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csup_%7B%7B%5Cboldsymbol+v%7D+%5Cin+%7B%5Cmathbb+R%7D%5Ed%3A+%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%5Cleq+c%2Fa%7D+%5C+%5Clangle+%7B%5Cboldsymbol+g%7D%2C%7B%5Cboldsymbol+v%7D%5Crangle+-+%5Cfrac%7Ba%7D%7B2%7D%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%5E2+%3D+%5Cfrac%7B1%7D%7B2+a+%7D+%5Cleft%5B%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C%5E2_%5Cstar-%5Cmax%28%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar-c%2C0%29%5E2%5Cright%5D+%5Cleq+%5Cfrac%7B1%7D%7B2+a+%7D+%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar+%5Cmin%5Cleft%28%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar%2C+2+c+%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof:
![\displaystyle \begin{aligned} \sup_{{\boldsymbol v} \in {\mathbb R}^d: \|{\boldsymbol v}\|\leq c/a} \ \langle {\boldsymbol g},{\boldsymbol v}\rangle - \frac{a}{2}\|{\boldsymbol v}\|^2 &=\sup_{0\leq x\leq c/a} \ \sup_{{\boldsymbol v} \in {\mathbb R}^d: \|{\boldsymbol v}\|= x} \ \langle {\boldsymbol g},{\boldsymbol v}\rangle - \frac{a}{2}\|{\boldsymbol v}\|^2\\ &=\sup_{0\leq x\leq c/a} \ x\|{\boldsymbol g}\|_\star - \frac{a}{2}x^2\\ &=\frac{1}{a} \min(\|{\boldsymbol g}\|_\star,c)\left[\|{\boldsymbol g}\|_\star-\frac{1}{2}\min(\|{\boldsymbol g}\|_\star,c)\right]\\ &=\frac{1}{2a} \left[\|{\boldsymbol g}\|^2_\star-\max(\|{\boldsymbol g}\|_\star-c,0)^2\right]~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csup_%7B%7B%5Cboldsymbol+v%7D+%5Cin+%7B%5Cmathbb+R%7D%5Ed%3A+%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%5Cleq+c%2Fa%7D+%5C+%5Clangle+%7B%5Cboldsymbol+g%7D%2C%7B%5Cboldsymbol+v%7D%5Crangle+-+%5Cfrac%7Ba%7D%7B2%7D%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%5E2+%26%3D%5Csup_%7B0%5Cleq+x%5Cleq+c%2Fa%7D+%5C+%5Csup_%7B%7B%5Cboldsymbol+v%7D+%5Cin+%7B%5Cmathbb+R%7D%5Ed%3A+%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%3D+x%7D+%5C+%5Clangle+%7B%5Cboldsymbol+g%7D%2C%7B%5Cboldsymbol+v%7D%5Crangle+-+%5Cfrac%7Ba%7D%7B2%7D%5C%7C%7B%5Cboldsymbol+v%7D%5C%7C%5E2%5C%5C+%26%3D%5Csup_%7B0%5Cleq+x%5Cleq+c%2Fa%7D+%5C+x%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar+-+%5Cfrac%7Ba%7D%7B2%7Dx%5E2%5C%5C+%26%3D%5Cfrac%7B1%7D%7Ba%7D+%5Cmin%28%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar%2Cc%29%5Cleft%5B%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar-%5Cfrac%7B1%7D%7B2%7D%5Cmin%28%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar%2Cc%29%5Cright%5D%5C%5C+%26%3D%5Cfrac%7B1%7D%7B2a%7D+%5Cleft%5B%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C%5E2_%5Cstar-%5Cmax%28%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar-c%2C0%29%5E2%5Cright%5D%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The second inequality is obtained by lower bounding the max with its two possible values and overapproximating.
We can now prove the Theorem.
Proof: We can use the one-step lemma for OMD with 

Summing over 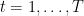

Summing the r.h.s., we have that
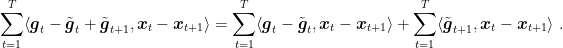
Finally, observe that

Telescoping the terms with the Bregman divergences gives the first bound.
Now, using the strong convexity of

From Lemma 2, we know that 


Using Lemma 3 gives the second bound.
The bound for fixed 
The advantage of these bounds is that the terms in the sum only depends linearly on bad hints, rather than quadratically. Next, we will use exactly this property to obtain the optimal regret guarantee for OMD with delayed feedback.
From Optimistic OMD to Delayed OMD. We now show the improved bound for OMD with delays and constant learning rate. The delay-to-optimism conversion says that we have to set 

That is, assuming 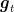


3. Improved Optimistic FTRL Bound for Linear Losses
We now prove a similar improved regret guarantee for Optimistic FTRL with linearized losses, whose pseudo-code is the following one.

Here, we will give an improved version of the regret bound for Optimistic FTRL with linearized losses. The analysis will use an auxiliary sequence of predictions, and then relate these predictions to the ones of Optimistic FTRL.
Define 
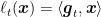



Theorem 4. With the notation in Algorithm 2, let
is closed, subdifferentiable, and
pointwise for all
for all
and all
for
![\displaystyle \begin{aligned} \sum_{t=1}^T &\ell_t({\boldsymbol x}_t) - \sum_{t=1}^T \ell_t({\boldsymbol u})\\ &\leq \sum_{t=1}^T \langle{\boldsymbol g}_t, {\boldsymbol x}_t - {\boldsymbol u}\rangle\\ &\leq \psi_{T+1}({\boldsymbol u}) - \min_{{\boldsymbol x} \in \mathcal{V}} \ \psi_{1}({\boldsymbol x}) + \sum_{t=1}^T \left[\frac{\|{\boldsymbol g}_t-\tilde{{\boldsymbol g}}^{(a)}_t\|_\star^2}{2\lambda_t} + \frac{\|{\boldsymbol g}_t\|_\star \|\tilde{{\boldsymbol g}}_t - \tilde{{\boldsymbol g}}^{(a)}_t\|_\star}{\lambda_t} \right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Csum_%7Bt%3D1%7D%5ET+%26%5Cell_t%28%7B%5Cboldsymbol+x%7D_t%29+-+%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28%7B%5Cboldsymbol+u%7D%29%5C%5C+%26%5Cleq+%5Csum_%7Bt%3D1%7D%5ET+%5Clangle%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t+-+%7B%5Cboldsymbol+u%7D%5Crangle%5C%5C+%26%5Cleq+%5Cpsi_%7BT%2B1%7D%28%7B%5Cboldsymbol+u%7D%29+-+%5Cmin_%7B%7B%5Cboldsymbol+x%7D+%5Cin+%5Cmathcal%7BV%7D%7D+%5C+%5Cpsi_%7B1%7D%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%5B%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+g%7D_t-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5E%7B%28a%29%7D_t%5C%7C_%5Cstar%5E2%7D%7B2%5Clambda_t%7D+%2B+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_%5Cstar+%5C%7C%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t+-+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5E%7B%28a%29%7D_t%5C%7C_%5Cstar%7D%7B%5Clambda_t%7D+%5Cright%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
To prove this theorem we will need the following stability lemma for FTRL.
Lemma 5. Assume
to be
and
. Then,
.
Proof: Define 


Hence, summing these two inequalities, we have

that completes the proof.
We can now prove Theorem 4.
Proof: Using the regret bound for optimistic FTRL on the predictions

Now, we focus our attention on 

Using this inequality in the regret bound above, for any 

Remember that
Note that the minimization with respect to 
![\displaystyle \min_{\tilde{{\boldsymbol g}}_t^{(a)}} \ \frac{\|{\boldsymbol g}_t -\tilde{{\boldsymbol g}}_t^{(a)}\|^2_\star}{2} +\|{\boldsymbol g}_t\|_\star \|\tilde{{\boldsymbol g}}_t - \tilde{{\boldsymbol g}}_t^{(a)}\|_\star \leq \frac{1}{2} \left[\|{\boldsymbol g}_t -\tilde{{\boldsymbol g}}_t\|^2_\star - \max(\|{\boldsymbol g}_t -\tilde{{\boldsymbol g}}_t\|_\star-\|{\boldsymbol g}_t\|_\star,0)^2\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7B%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5E%7B%28a%29%7D%7D+%5C+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+g%7D_t+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5E%7B%28a%29%7D%5C%7C%5E2_%5Cstar%7D%7B2%7D+%2B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_%5Cstar+%5C%7C%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t+-+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5E%7B%28a%29%7D%5C%7C_%5Cstar+%5Cleq+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B%5C%7C%7B%5Cboldsymbol+g%7D_t+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5C%7C%5E2_%5Cstar+-+%5Cmax%28%5C%7C%7B%5Cboldsymbol+g%7D_t+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D_t%5C%7C_%5Cstar-%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_%5Cstar%2C0%29%5E2%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
From Optimistic FTRL to Delayed FTRL. For our aim of analyzing online learning with delays, we can choose 

That is, assuming that the 

4. Conclusion
I have described only the basic idea behind the reduction from online learning with delayed feedback to optimistic updates with bad hints. It should be immediate to see that this reduction allows us to use any variant for optimistic updates to study delayed updates. For example, it is now immediate to use data-depedent learning rates or regularizers to obtain tigher regret bounds under particular situations.
5. History Bits
Weinberger&Ordentlich (2002) were the first to analyze the delayed feedback problem. They considered the adversarial full information setting with a fixed, known delay
The equivalence of delays/bad hints and the improved regret guarantees for Optimistic FTRL and Optimistic OMD are due to Flaspohler et al. (2021). However, their OMD bound contains a small mistake: They are missing the last terms in the bound, due to the fact that we set the 

Lemma 2 is from Joulani et al. (2016).
Acknowledgments
Thanks for ChatGPT 5.2 for checking the proofs. (Yet, I found the mistake in the previous paper, while ChatGPT 5.2 was claiming that everything was correct!)
6. Exercises
Exercise 1. Let
and
a norm. Then, show that
![\displaystyle \min_{\tilde{{\boldsymbol g}}^{(a)}} \ \frac{\|{\boldsymbol g} -\tilde{{\boldsymbol g}}^{(a)}\|^2_\star}{2} +\|{\boldsymbol g}\|_\star \|\tilde{{\boldsymbol g}} - \tilde{{\boldsymbol g}}^{(a)}\|_\star \leq \frac{1}{2} \left[\|{\boldsymbol g} -\tilde{{\boldsymbol g}}\|^2_\star - \max(\|{\boldsymbol g} -\tilde{{\boldsymbol g}}\|_\star-\|{\boldsymbol g}\|_\star,0)^2\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7B%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5E%7B%28a%29%7D%7D+%5C+%5Cfrac%7B%5C%7C%7B%5Cboldsymbol+g%7D+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5E%7B%28a%29%7D%5C%7C%5E2_%5Cstar%7D%7B2%7D+%2B%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar+%5C%7C%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D+-+%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5E%7B%28a%29%7D%5C%7C_%5Cstar+%5Cleq+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B%5C%7C%7B%5Cboldsymbol+g%7D+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5C%7C%5E2_%5Cstar+-+%5Cmax%28%5C%7C%7B%5Cboldsymbol+g%7D+-%5Ctilde%7B%7B%5Cboldsymbol+g%7D%7D%5C%7C_%5Cstar-%5C%7C%7B%5Cboldsymbol+g%7D%5C%7C_%5Cstar%2C0%29%5E2%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
