We will continue with black-box reductions, this time solving the problem of sleeping experts.
1. Sleeping Experts
Consider now the setting of learning with experts where only a subset of the experts is active in each round. In particular we have that 



The online algorithm receives at the beginning of each round the information about which experts will be active and it can pick only one of the active experts. So, we constrain the learning with experts algorithm to produce a probability distribution only over the active experts. So, we will use a different notion of regret, in particular, our regret with respect to the expert

In other words, we measure the regret against expert 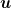

In the case that all the experts are active on all rounds, this notion recovers the usual one. However, in the general case, this is a different notion than the one we used in Online Linear Optimization.
For the reduction, we need a way to transform a vector 

For the second part, from the original linear losses 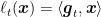



With the above definitions, we have

In turn, this implies that

In words, we can construct surrogate losses to transform the sleeping expert problem in an OLO problem over 

The norm of the surrogate losses is controlled because 
Remark 1. Clearly, if we have an algorithm for learning with experts, we can use it in the reduction because
.
Remark 2. The above definitions and reduction generalize to the setting that
, denoting the confidence that the expert has in their prediction, where
means that the expert has no confidence and it abstains from producing a prediction.
Example 1. Consider the learning with sleeping experts setting with linear losses
. Let’s design a series of reductions to easily solve this problem: this is a good exercise to show how easy is to combine online learning algorithms and reductions as LEGO blocks.
Consider to run a 1d coin-betting algorithm to solve online linear optimization in
. For example, we can use the KT algorithm, where we ignore the rounds where the gradients are zero:
Use a black-box reduction from last time to constraint it to
and obtain a regret of
where
is the number of times that
. Use it to produce an algorithm over
. Finally, set
and a sleeping expert reduction from
Moreover, given that
, the upper bound on the regret of the final algorithm against any expert
, that depends on the number of rounds that the expert
![\displaystyle x_t =\frac{-\sum_{j=1}^{t-1} g_j}{\sum_{j=1}^{t-1} \boldsymbol{1}[g_j\neq0]} \left(\epsilon - \sum_{j=1}^{t-1} g_j x_j\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+x_t+%3D%5Cfrac%7B-%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+g_j%7D%7B%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Cboldsymbol%7B1%7D%5Bg_j%5Cneq0%5D%7D+%5Cleft%28%5Cepsilon+-+%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+g_j+x_j%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \tilde{g}_t &= \begin{cases} \min(g_t,0), & z_t<0\\ g_t, & z_t \geq 0 \end{cases}\\ z_t &=\frac{-\sum_{j=1}^{t-1} \tilde{g}_j}{\sum_{j=1}^{t-1} \boldsymbol{1}[\tilde{g}_j\neq0]} \left(\epsilon - \sum_{j=1}^{t-1} \tilde{g}_j z_j\right)\\ x_t &=\max(z_t,0)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctilde%7Bg%7D_t+%26%3D+%5Cbegin%7Bcases%7D+%5Cmin%28g_t%2C0%29%2C+%26+z_t%3C0%5C%5C+g_t%2C+%26+z_t+%5Cgeq+0+%5Cend%7Bcases%7D%5C%5C+z_t+%26%3D%5Cfrac%7B-%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Ctilde%7Bg%7D_j%7D%7B%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Cboldsymbol%7B1%7D%5B%5Ctilde%7Bg%7D_j%5Cneq0%5D%7D+%5Cleft%28%5Cepsilon+-+%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Ctilde%7Bg%7D_j+z_j%5Cright%29%5C%5C+x_t+%26%3D%5Cmax%28z_t%2C0%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{aligned} \hat{g}_{t,i} &=a_{t,i}(g_{t,i}-\langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle), \ i =1, \dots, d\\ \tilde{g}_{t,i} &= \begin{cases} \min(\hat{g}_{t,i},0), & z_{t,i}<0\\ \hat{g}_{t,i}, & z_{t,i} \geq 0 \end{cases}, \ i=1, \dots, d\\ z_{t,i} &=\frac{-\sum_{j=1}^{t-1} \tilde{g}_{j,i}}{\sum_{j=1}^{t-1} \boldsymbol{1}[\tilde{g}_{j,i}\neq0]} \left(\epsilon_i - \sum_{j=1}^{t-1} \tilde{g}_{j,i} z_{j,i}\right), \ i=1, \dots, d\\ x_{t,i} &=\frac{a_{t,i} \max(z_{t,i},0)}{\sum_{j=1}^d a_{t,j} \max(z_{t,i},0)}, \ i=1, \dots, d~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Chat%7Bg%7D_%7Bt%2Ci%7D+%26%3Da_%7Bt%2Ci%7D%28g_%7Bt%2Ci%7D-%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle%29%2C+%5C+i+%3D1%2C+%5Cdots%2C+d%5C%5C+%5Ctilde%7Bg%7D_%7Bt%2Ci%7D+%26%3D+%5Cbegin%7Bcases%7D+%5Cmin%28%5Chat%7Bg%7D_%7Bt%2Ci%7D%2C0%29%2C+%26+z_%7Bt%2Ci%7D%3C0%5C%5C+%5Chat%7Bg%7D_%7Bt%2Ci%7D%2C+%26+z_%7Bt%2Ci%7D+%5Cgeq+0+%5Cend%7Bcases%7D%2C+%5C+i%3D1%2C+%5Cdots%2C+d%5C%5C+z_%7Bt%2Ci%7D+%26%3D%5Cfrac%7B-%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Ctilde%7Bg%7D_%7Bj%2Ci%7D%7D%7B%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Cboldsymbol%7B1%7D%5B%5Ctilde%7Bg%7D_%7Bj%2Ci%7D%5Cneq0%5D%7D+%5Cleft%28%5Cepsilon_i+-+%5Csum_%7Bj%3D1%7D%5E%7Bt-1%7D+%5Ctilde%7Bg%7D_%7Bj%2Ci%7D+z_%7Bj%2Ci%7D%5Cright%29%2C+%5C+i%3D1%2C+%5Cdots%2C+d%5C%5C+x_%7Bt%2Ci%7D+%26%3D%5Cfrac%7Ba_%7Bt%2Ci%7D+%5Cmax%28z_%7Bt%2Ci%7D%2C0%29%7D%7B%5Csum_%7Bj%3D1%7D%5Ed+a_%7Bt%2Cj%7D+%5Cmax%28z_%7Bt%2Ci%7D%2C0%29%7D%2C+%5C+i%3D1%2C+%5Cdots%2C+d%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
2. History Bits
The setting of sleeping experts has been proposed by Blum (1997) and Freund, Schapire, Singer, and Warmuth (1997). The reduction above is an extension of the one from Gaillard, Stoltz, and Van Erven (2014) that was designed to reduce the sleeping experts problem to the learning with experts problem rather than OLO in 
3. Exercises
Exercise 1. Prove that the variant of KT that does not update on rounds where
have the stated regret in Example 1.
