This is the last post in this series to show that online learning is more than online learning. This time it is about using an online linear optimization algorithm to minimize non-convex, non-smooth functions with access to stochastic gradients. Unlike in the previous two posts, here we will actually use the online algorithm itself, not just its regret guarantee. Nevertheless, the same philosophy applies: a regret guarantee is a statement that the sequence 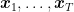
1. From Online Learning to Non-Convex Non-Smooth Optimization
This section describes a simple (and surprisingly sharp) reduction from Online Linear Optimization (OLO) to the task of finding approximate stationary points of non-convex, non-smooth objectives. The key idea is to feed stochastic gradients to an online algorithm, which then decides the updates rather than the iterates.
We consider the objective function 
Example 1. Consider
defined as
. Then,
, where
. Hence,
is differentiable everywhere, but its derivative is not Lipschitz because
is unbounded when
.
To connect function values to gradients without convexity or smoothness, we isolate the only calculus identity needed by the reduction. So, we will define well-behaved functions as those that satisfy the specific equality we need.
Definition 1 (Well-behaved function). A differentiable function
,

Remark 1. Identity (1) is immediate for smooth functions (by the fundamental theorem of calculus applied to
), but it can hold well beyond smooth objectives. In particular, Cutkosky et al. (2023) show that if
We now define our notion of optimality. Since
Definition 2 (Barycentric
-stationarity). Let
. Let
be the set of random variables
with finite support in the ball of radius
around
, such that
exists for all
in the support of
We say that
.
![\displaystyle \|\nabla F({\boldsymbol x})\|_\delta \stackrel{\text{def}}{=} \inf_{{\boldsymbol Q} \in \mathcal{Q}({\boldsymbol x},\delta)} \ \left\{ \left\| \mathop{\mathbb E}\left[\nabla F({\boldsymbol Q})\right]\right\|_2 : \mathop{\mathbb E}[{\boldsymbol Q}]={\boldsymbol x} \right\}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5C%7C_%5Cdelta+%5Cstackrel%7B%5Ctext%7Bdef%7D%7D%7B%3D%7D+%5Cinf_%7B%7B%5Cboldsymbol+Q%7D+%5Cin+%5Cmathcal%7BQ%7D%28%7B%5Cboldsymbol+x%7D%2C%5Cdelta%29%7D+%5C+%5Cleft%5C%7B+%5Cleft%5C%7C+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cnabla+F%28%7B%5Cboldsymbol+Q%7D%29%5Cright%5D%5Cright%5C%7C_2+%3A+%5Cmathop%7B%5Cmathbb+E%7D%5B%7B%5Cboldsymbol+Q%7D%5D%3D%7B%5Cboldsymbol+x%7D+%5Cright%5C%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Remark 2. This notion is closely related to Goldstein-type
1.1. The Reduction Algorithm
We now present the reduction from non-convex optimization of well-behaved functions to online linear optimization.
Fix a cycle length 

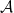










Theorem 3. Let
be the sigma-field generated by all randomness up to round
before querying
, so that
is
for some
. Let
be a multiple of the cycle length
steps with cycle length
with learning rate
and initial point equal to
on each cycle (i.e., after each reset). Then,
In particular, for
and then set
rounded to an integer. Then,
![\displaystyle \label{eq:stoch-oracle} \mathop{\mathbb E}[{\boldsymbol g}_t\mid \mathcal{F}_t]=\nabla F({\boldsymbol x}'_t), \qquad \mathop{\mathbb E}[\|{\boldsymbol g}_t\|_2^2\mid \mathcal{F}_t]\le G^2, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Astoch-oracle%7D+%5Cmathop%7B%5Cmathbb+E%7D%5B%7B%5Cboldsymbol+g%7D_t%5Cmid+%5Cmathcal%7BF%7D_t%5D%3D%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C+%5Cqquad+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_2%5E2%5Cmid+%5Cmathcal%7BF%7D_t%5D%5Cle+G%5E2%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb E}\left[ \frac{1}{T/K}\sum_{j=1}^{T/K} \left\|\frac{1}{K}\sum_{t=(j-1)K+1}^{jK}\nabla F({\boldsymbol x}'_t)\right\|_2 \right] \le \frac{F({\boldsymbol x}_0)-\inf_{{\boldsymbol x}} F({\boldsymbol x})}{D\,T} + \frac{2G}{\sqrt{K}}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cfrac%7B1%7D%7BT%2FK%7D%5Csum_%7Bj%3D1%7D%5E%7BT%2FK%7D+%5Cleft%5C%7C%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5Cright%5C%7C_2+%5Cright%5D+%5Cle+%5Cfrac%7BF%28%7B%5Cboldsymbol+x%7D_0%29-%5Cinf_%7B%7B%5Cboldsymbol+x%7D%7D+F%28%7B%5Cboldsymbol+x%7D%29%7D%7BD%5C%2CT%7D+%2B+%5Cfrac%7B2G%7D%7B%5Csqrt%7BK%7D%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \mathop{\mathbb E}\big[\|\nabla F(\bar{{\boldsymbol x}}_J)\|_\delta\big] = \mathcal{O}\left(G^\frac{2}{3}\,\left(\frac{F({\boldsymbol x}_0)-\inf_{{\boldsymbol x}} F({\boldsymbol x})}{T\delta}\right)^{1/3}\right)~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cbig%5B%5C%7C%5Cnabla+F%28%5Cbar%7B%7B%5Cboldsymbol+x%7D%7D_J%29%5C%7C_%5Cdelta%5Cbig%5D+%3D+%5Cmathcal%7BO%7D%5Cleft%28G%5E%5Cfrac%7B2%7D%7B3%7D%5C%2C%5Cleft%28%5Cfrac%7BF%28%7B%5Cboldsymbol+x%7D_0%29-%5Cinf_%7B%7B%5Cboldsymbol+x%7D%7D+F%28%7B%5Cboldsymbol+x%7D%29%7D%7BT%5Cdelta%7D%5Cright%29%5E%7B1%2F3%7D%5Cright%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We first prove the key identity linking change in function value to an expected gradient. By Definition 1, we have
![\displaystyle \begin{aligned} F({\boldsymbol x}_{t})-F({\boldsymbol x}_{t-1}) &= \int_0^1 \! \langle\nabla F({\boldsymbol x}_{t-1}+a({\boldsymbol x}_{t}-{\boldsymbol x}_{t-1})),{\boldsymbol x}_{t}-{\boldsymbol x}_{t-1}\rangle\,\mathrm{d}a = \int_0^1 \! \langle\nabla F({\boldsymbol x}_{t-1}-a {\boldsymbol m}_{t}),-{\boldsymbol m}_{t}\rangle\,\mathrm{d}a\\ &=-\left\langle \mathop{\mathbb E}_{s_t}\big[\nabla F({\boldsymbol x}_{t-1}-s_t {\boldsymbol m}_{t})\big],{\boldsymbol m}_{t}\right\rangle =-\left\langle \mathop{\mathbb E}_{s_t}\big[\nabla F({\boldsymbol x}'_{t})\big],{\boldsymbol m}_{t}\right\rangle, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+F%28%7B%5Cboldsymbol+x%7D_%7Bt%7D%29-F%28%7B%5Cboldsymbol+x%7D_%7Bt-1%7D%29+%26%3D+%5Cint_0%5E1+%5C%21+%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D_%7Bt-1%7D%2Ba%28%7B%5Cboldsymbol+x%7D_%7Bt%7D-%7B%5Cboldsymbol+x%7D_%7Bt-1%7D%29%29%2C%7B%5Cboldsymbol+x%7D_%7Bt%7D-%7B%5Cboldsymbol+x%7D_%7Bt-1%7D%5Crangle%5C%2C%5Cmathrm%7Bd%7Da+%3D+%5Cint_0%5E1+%5C%21+%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D_%7Bt-1%7D-a+%7B%5Cboldsymbol+m%7D_%7Bt%7D%29%2C-%7B%5Cboldsymbol+m%7D_%7Bt%7D%5Crangle%5C%2C%5Cmathrm%7Bd%7Da%5C%5C+%26%3D-%5Cleft%5Clangle+%5Cmathop%7B%5Cmathbb+E%7D_%7Bs_t%7D%5Cbig%5B%5Cnabla+F%28%7B%5Cboldsymbol+x%7D_%7Bt-1%7D-s_t+%7B%5Cboldsymbol+m%7D_%7Bt%7D%29%5Cbig%5D%2C%7B%5Cboldsymbol+m%7D_%7Bt%7D%5Cright%5Crangle+%3D-%5Cleft%5Clangle+%5Cmathop%7B%5Cmathbb+E%7D_%7Bs_t%7D%5Cbig%5B%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_%7Bt%7D%29%5Cbig%5D%2C%7B%5Cboldsymbol+m%7D_%7Bt%7D%5Cright%5Crangle%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where the second to last equality is due to the fact that 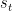
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Taking expectation over all randomness up to time 
![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[F({\boldsymbol x}_t)-F({\boldsymbol x}_{t-1})\right] &= -\mathop{\mathbb E}\left[\langle\nabla F({\boldsymbol x}'_t),{\boldsymbol m}_t\rangle\right] \\ &= \mathop{\mathbb E}\left[\langle-{\boldsymbol g}_t,{\boldsymbol m}_t-{\boldsymbol u}_j\rangle\right] +\mathop{\mathbb E}\left[\langle{\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t),{\boldsymbol m}_t\rangle\right] -\mathop{\mathbb E}\left[\langle{\boldsymbol g}_t,{\boldsymbol u}_j\rangle\right] \\ &= \mathop{\mathbb E}\left[\langle-{\boldsymbol g}_t,{\boldsymbol m}_t-{\boldsymbol u}_j\rangle\right] -\mathop{\mathbb E}\left[\langle{\boldsymbol g}_t,{\boldsymbol u}_j\rangle\right], \\ &= \mathop{\mathbb E}\left[\langle-{\boldsymbol g}_t,{\boldsymbol m}_t-{\boldsymbol u}_j\rangle\right] +\mathop{\mathbb E}\left[\langle-\nabla F({\boldsymbol x}'_t),{\boldsymbol u}_j\rangle\right]+\mathop{\mathbb E}\left[\langle\nabla F({\boldsymbol x}'_t)-{\boldsymbol g}_t,{\boldsymbol u}_j\rangle\right], & (3) \\\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5BF%28%7B%5Cboldsymbol+x%7D_t%29-F%28%7B%5Cboldsymbol+x%7D_%7Bt-1%7D%29%5Cright%5D+%26%3D+-%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+m%7D_t%5Crangle%5Cright%5D+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+m%7D_t-%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%2B%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+m%7D_t%5Crangle%5Cright%5D+-%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+m%7D_t-%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+-%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D%2C+%5C%5C+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+m%7D_t-%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%2B%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D%2B%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D%2C+%26+%283%29+%5C%5C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where in the second to last equality we used that 
![{\mathop{\mathbb E}[{\boldsymbol g}_t \mid \mathcal{F}_t] = \nabla F({\boldsymbol x}'_t)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B%7B%5Cboldsymbol+g%7D_t+%5Cmid+%5Cmathcal%7BF%7D_t%5D+%3D+%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We now analyze one cycle, and then sum over cycles. Fix a cycle 

![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[F({\boldsymbol x}_{jK})-F({\boldsymbol x}_{(j-1)K})\right] &= \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK}\langle -{\boldsymbol g}_t,{\boldsymbol m}_t-{\boldsymbol u}_j\rangle\right] - \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK} \langle\nabla F({\boldsymbol x}'_t),{\boldsymbol u}_j\rangle\right] \\ &\quad + \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK} \langle\nabla F({\boldsymbol x}'_t)-{\boldsymbol g}_t,{\boldsymbol u}_j\rangle\right]~. & (4) \\\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5BF%28%7B%5Cboldsymbol+x%7D_%7BjK%7D%29-F%28%7B%5Cboldsymbol+x%7D_%7B%28j-1%29K%7D%29%5Cright%5D+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Clangle+-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+m%7D_t-%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+-+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%5C%5C+%26%5Cquad+%2B+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D%7E.+%26+%284%29+%5C%5C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We now focus on each term on the r.h.s. of this equality.
For the first term on the r.h.s. of (4), for any 

Since this inequality holds for every 

![\displaystyle \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK}\langle -{\boldsymbol g}_t,{\boldsymbol m}_t-{\boldsymbol u}_j\rangle\right] \leq \frac{D^2}{2\eta} + \frac{\eta}{2} K G^2 = D G \sqrt{K}~. \label{eq:proof_non_convex_conversion_eq1} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Clangle+-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+m%7D_t-%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%5Cleq+%5Cfrac%7BD%5E2%7D%7B2%5Ceta%7D+%2B+%5Cfrac%7B%5Ceta%7D%7B2%7D+K+G%5E2+%3D+D+G+%5Csqrt%7BK%7D%7E.+%5Clabel%7Beq%3Aproof_non_convex_conversion_eq1%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we choose

Our choice of 
![\displaystyle \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK}\langle\nabla F({\boldsymbol x}'_t),{\boldsymbol u}_j\rangle\right] = D\mathop{\mathbb E}\left[\left\|\sum_{t=(j-1)K+1}^{jK}\nabla F({\boldsymbol x}'_t)\right\|_2\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%3D+D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5Cright%5C%7C_2%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we upper bound the last term in (4). First, observe that
![\displaystyle \mathop{\mathbb E}[\|{\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t)\|_2^2|\mathcal{F}_t] = \mathop{\mathbb E}[\|{\boldsymbol g}_t\|_2^2|\mathcal{F}_t]-\|\nabla F({\boldsymbol x}'_t)\|_2^2 \leq G^2,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5C%7C_2%5E2%7C%5Cmathcal%7BF%7D_t%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5B%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_2%5E2%7C%5Cmathcal%7BF%7D_t%5D-%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5C%7C_2%5E2+%5Cleq+G%5E2%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle \mathop{\mathbb E}[\langle{\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t),{\boldsymbol g}_n-\nabla F({\boldsymbol x}'_n)\rangle |\mathcal{F}_t]=0, \quad \forall n< t~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Clangle%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%2C%7B%5Cboldsymbol+g%7D_n-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_n%29%5Crangle+%7C%5Cmathcal%7BF%7D_t%5D%3D0%2C+%5Cquad+%5Cforall+n%3C+t%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, we have
![\displaystyle \begin{aligned} \mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK} \langle\nabla F({\boldsymbol x}'_t)-{\boldsymbol g}_t,{\boldsymbol u}_j\rangle\right] &\leq D \mathop{\mathbb E}\left[\left\|\sum_{t=(j-1)K+1}^{jK} ({\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t))\right\|_2\right] \\ &\leq D\sqrt{\mathop{\mathbb E}\left[\left\|\sum_{t=(j-1)K+1}^{jK} ({\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t))\right\|^2_2\right]}\\ &= D\sqrt{\mathop{\mathbb E}\left[\sum_{t=(j-1)K+1}^{jK} \|{\boldsymbol g}_t-\nabla F({\boldsymbol x}'_t)\|^2_2\right]}\\ &\leq G D\sqrt{K}, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%5Clangle%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29-%7B%5Cboldsymbol+g%7D_t%2C%7B%5Cboldsymbol+u%7D_j%5Crangle%5Cright%5D+%26%5Cleq+D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%28%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%29%5Cright%5C%7C_2%5Cright%5D+%5C%5C+%26%5Cleq+D%5Csqrt%7B%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%28%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%29%5Cright%5C%7C%5E2_2%5Cright%5D%7D%5C%5C+%26%3D+D%5Csqrt%7B%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D+%5C%7C%7B%5Cboldsymbol+g%7D_t-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5C%7C%5E2_2%5Cright%5D%7D%5C%5C+%26%5Cleq+G+D%5Csqrt%7BK%7D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where we used Cauchy–Schwarz’s inequality and Jensen’s inequality.
Putting everything together, we have
![\displaystyle D \, \mathop{\mathbb E}\left[\left\|\sum_{t=(j-1)K+1}^{jK}\nabla F({\boldsymbol x}'_t)\right\|_2\right] \le 2DG\sqrt{K} + \mathop{\mathbb E}\left[F({\boldsymbol x}_{(j-1)K})-F({\boldsymbol x}_{jK})\right]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D+%5C%2C+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5Cright%5C%7C_2%5Cright%5D+%5Cle+2DG%5Csqrt%7BK%7D+%2B+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5BF%28%7B%5Cboldsymbol+x%7D_%7B%28j-1%29K%7D%29-F%28%7B%5Cboldsymbol+x%7D_%7BjK%7D%29%5Cright%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Summing over 
![\displaystyle D\sum_{j=1}^{T/K} \mathop{\mathbb E}\left[\left\|\sum_{t=(j-1)K+1}^{jK}\nabla F({\boldsymbol x}'_t)\right\|_2\right] \le 2\frac{T}{K}\,DG\sqrt{K} + F({\boldsymbol x}_0)-\mathop{\mathbb E}[F({\boldsymbol x}_T)] \le 2\frac{T}{K}\,DG\sqrt{K} + F({\boldsymbol x}_0)-\inf_{{\boldsymbol x}} F({\boldsymbol x})~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D%5Csum_%7Bj%3D1%7D%5E%7BT%2FK%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cleft%5C%7C%5Csum_%7Bt%3D%28j-1%29K%2B1%7D%5E%7BjK%7D%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%27_t%29%5Cright%5C%7C_2%5Cright%5D+%5Cle+2%5Cfrac%7BT%7D%7BK%7D%5C%2CDG%5Csqrt%7BK%7D+%2B+F%28%7B%5Cboldsymbol+x%7D_0%29-%5Cmathop%7B%5Cmathbb+E%7D%5BF%28%7B%5Cboldsymbol+x%7D_T%29%5D+%5Cle+2%5Cfrac%7BT%7D%7BK%7D%5C%2CDG%5Csqrt%7BK%7D+%2B+F%28%7B%5Cboldsymbol+x%7D_0%29-%5Cinf_%7B%7B%5Cboldsymbol+x%7D%7D+F%28%7B%5Cboldsymbol+x%7D%29%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Dividing by 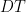
Now observe that within each cycle we have 






Sampling

It is interesting to compute the update

This is reminiscent of the Stochastic Gradient Descent (SGD) update with momentum and clipping, which are common heuristics for optimizing non-convex objectives in deep learning. Yet, here the update comes naturally from the theory.
We can also prove that this bound is optimal. To see this, we consider smooth functions and the following lemma.
 is
is  . Then,
. Then, Proof: Since 
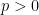

![{\left\|\mathop{\mathbb E}_{{\boldsymbol y}\sim Q}[\nabla F({\boldsymbol y})]\right\|_2 \leq \epsilon + p}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%5C%7C%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+y%7D%5Csim+Q%7D%5B%5Cnabla+F%28%7B%5Cboldsymbol+y%7D%29%5D%5Cright%5C%7C_2+%5Cleq+%5Cepsilon+%2B+p%7D&bg=ffffff&fg=000000&s=0&c=20201002)
By definition of 



![\displaystyle \begin{aligned} \epsilon + p & \geq \left\|\mathop{\mathbb E}_{{\boldsymbol y}\sim Q}[\nabla F({\boldsymbol y})]\right\|_2 = \left\|\nabla F({\boldsymbol x}) + \mathop{\mathbb E}_{{\boldsymbol y}\sim Q}\big[\nabla F({\boldsymbol y})-\nabla F({\boldsymbol x})\big]\right\|_2 \\ &\geq \|\nabla F({\boldsymbol x})\|_2 - \left\|\mathop{\mathbb E}_{{\boldsymbol y}\sim Q}\big[\nabla F({\boldsymbol y})-\nabla F({\boldsymbol x})\big]\right\|_2 \\ &\geq \|\nabla F({\boldsymbol x})\|_2 - \mathop{\mathbb E}_{{\boldsymbol y}\sim Q}\left[\|\nabla F({\boldsymbol y})-\nabla F({\boldsymbol x})\|_2\right] \\ &\geq \|\nabla F({\boldsymbol x})\|_2 - H\delta~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cepsilon+%2B+p+%26+%5Cgeq+%5Cleft%5C%7C%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+y%7D%5Csim+Q%7D%5B%5Cnabla+F%28%7B%5Cboldsymbol+y%7D%29%5D%5Cright%5C%7C_2+%3D+%5Cleft%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29+%2B+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+y%7D%5Csim+Q%7D%5Cbig%5B%5Cnabla+F%28%7B%5Cboldsymbol+y%7D%29-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5Cbig%5D%5Cright%5C%7C_2+%5C%5C+%26%5Cgeq+%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5C%7C_2+-+%5Cleft%5C%7C%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+y%7D%5Csim+Q%7D%5Cbig%5B%5Cnabla+F%28%7B%5Cboldsymbol+y%7D%29-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5Cbig%5D%5Cright%5C%7C_2+%5C%5C+%26%5Cgeq+%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5C%7C_2+-+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+y%7D%5Csim+Q%7D%5Cleft%5B%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+y%7D%29-%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5C%7C_2%5Cright%5D+%5C%5C+%26%5Cgeq+%5C%7C%5Cnabla+F%28%7B%5Cboldsymbol+x%7D%29%5C%7C_2+-+H%5Cdelta%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Therefore, 

Now, recall that Theorem 3 shows that we can find a 






2. History Bits
Zhang et al. (2020) proposed to use the Goldstein stationarity condition (Goldstein, 1977) for non-convex non-smooth objectives. They also proved a suboptimal bound of 

Acknowledgments
Thanks to ChatGPT for checking my post.
