This is the second post in my series of “From Online Learning to X”.
Last time, we saw how to derive Rademacher complexity bounds using the existence of online learning algorithms. This time, we will see how to go from online learning to PAC-Bayes bounds, using the existence of parameter-free algorithms for the learning with experts setting.
1. From Linear Regret to PAC-Bayes
In this section, we show that one can directly obtain generalization bounds for any machine learning algorithm from upper bounds on linear regret.
We will consider the same setting we used in the online-to-batch reduction, where one aims at minimizing the risk of a function ![{f:\mathcal{Z} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5Cmathcal%7BZ%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \text{Risk}(f)=\mathop{\mathbb E}_{{\boldsymbol \xi}\sim \rho} [f({\boldsymbol \xi})]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BRisk%7D%28f%29%3D%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim+%5Crho%7D+%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
For example, in a regression setting, 

Given a training set 



We can also consider the case where the predictor is randomized, in the sense that we draw 

![{\mathcal{F}:=\{f \mid f:\mathcal{Z} \rightarrow [0,1]\}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BF%7D%3A%3D%5C%7Bf+%5Cmid+f%3A%5Cmathcal%7BZ%7D+%5Crightarrow+%5B0%2C1%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \overline{\text{Gen}}(Q,\mathcal{S}) := \mathop{\mathbb E}_{f \sim Q}[\text{Gen}(f,\mathcal{S})]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverline%7B%5Ctext%7BGen%7D%7D%28Q%2C%5Cmathcal%7BS%7D%29+%3A%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bf+%5Csim+Q%7D%5B%5Ctext%7BGen%7D%28f%2C%5Cmathcal%7BS%7D%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
In particular, we are interested in upper bounding 

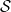
We now describe the reduction from this problem to an online learning one. Consider an online algorithm that at each round 


![{g_t(f)=f({\boldsymbol \xi}_t) - \mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho} [f({\boldsymbol \xi})]}](https://s0.wp.com/latex.php?latex=%7Bg_t%28f%29%3Df%28%7B%5Cboldsymbol+%5Cxi%7D_t%29+-+%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D+%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\ell_t(P)=\mathop{\mathbb E}_{f\sim P}[g_t(f)]}](https://s0.wp.com/latex.php?latex=%7B%5Cell_t%28P%29%3D%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+P%7D%5Bg_t%28f%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \begin{aligned} \overline{\text{Gen}}(Q,\mathcal{S}) &= \mathop{\mathbb E}_{f \sim Q}[\mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho}[f({\boldsymbol \xi})]] - \frac{1}{T}\sum_{t=1}^T \mathop{\mathbb E}_{f \sim Q}[f({\boldsymbol \xi}_t)]\\ &= \frac{1}{T}\sum_{t=1}^T -\ell_t(Q) \\ &= \frac{1}{T}\sum_{t=1}^T (\ell_t(P_t)-\ell_t(Q)) - \frac{1}{T}\sum_{t=1}^T \ell_t(P_t)\\ &= \frac{\text{Regret}_T(Q)}{T} - \frac{1}{T}\sum_{t=1}^T \ell_t(P_t)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Coverline%7B%5Ctext%7BGen%7D%7D%28Q%2C%5Cmathcal%7BS%7D%29+%26%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bf+%5Csim+Q%7D%5B%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D%5D+-+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+%5Cmathop%7B%5Cmathbb+E%7D_%7Bf+%5Csim+Q%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D_t%29%5D%5C%5C+%26%3D+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+-%5Cell_t%28Q%29+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+%28%5Cell_t%28P_t%29-%5Cell_t%28Q%29%29+-+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28P_t%29%5C%5C+%26%3D+%5Cfrac%7B%5Ctext%7BRegret%7D_T%28Q%29%7D%7BT%7D+-+%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bt%3D1%7D%5ET+%5Cell_t%28P_t%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We use 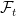


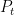


![\displaystyle \mathop{\mathbb E}[\ell_t(P_t)|\mathcal{F}_{t-1}] =\mathop{\mathbb E}[\mathop{\mathbb E}_{f \sim P_t}[f({\boldsymbol \xi}_t)-\mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho}[f({\boldsymbol \xi})]]|\mathcal{F}_{t-1}] =0~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cell_t%28P_t%29%7C%5Cmathcal%7BF%7D_%7Bt-1%7D%5D+%3D%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cmathop%7B%5Cmathbb+E%7D_%7Bf+%5Csim+P_t%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D_t%29-%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D%5D%7C%5Cmathcal%7BF%7D_%7Bt-1%7D%5D+%3D0%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
So, we have that 
![{f({\boldsymbol \xi})\in[0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle g_t(f)=f({\boldsymbol \xi}_t)-\mathop{\mathbb E}_{{\boldsymbol \xi}\sim\rho}[f({\boldsymbol \xi})] \in [-1,1],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+g_t%28f%29%3Df%28%7B%5Cboldsymbol+%5Cxi%7D_t%29-%5Cmathop%7B%5Cmathbb+E%7D_%7B%7B%5Cboldsymbol+%5Cxi%7D%5Csim%5Crho%7D%5Bf%28%7B%5Cboldsymbol+%5Cxi%7D%29%5D+%5Cin+%5B-1%2C1%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
and therefore
![\displaystyle \ell_t(P_t)=\mathop{\mathbb E}_{f\sim P_t}[g_t(f)] \in [-1,1]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell_t%28P_t%29%3D%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+P_t%7D%5Bg_t%28f%29%5D+%5Cin+%5B-1%2C1%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, 
![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

We are done! We can now put everything together to have the following theorem.
Theorem 1. Let
be a measurable space of measurable functions
,
, and
. Let
be drawn i.i.d. from a distribution
. Consider any online learning algorithm that outputs a distribution over
. Then, simultaneously for all
, even selected with the knowledge of
,

2. Which Online Algorithm Should we Use?
We can now instantiate this theorem with the regret of any online learning algorithm. For example, we could use the Exponentiated Gradient algorithm, where we think of each 
The first issue is easy to deal with: Roughly speaking, it is enough to substitute any sum over the experts with integrals. Using the fact that ![{g_t(f) \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bg_t%28f%29+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

where 
The second problem instead is a difficult one: the optimal learning rate depends on 

So, we can consider a continuous version of the parameter-free algorithm for learning with expert advice and we can show this regret bound.
Theorem 2. Let
. There exists an online learning algorithm that depends on
For any competitor distribution
![\displaystyle \ell_t(P)=\mathop{\mathbb E}_{f \sim P}[g_t(f)]~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cell_t%28P%29%3D%5Cmathop%7B%5Cmathbb+E%7D_%7Bf+%5Csim+P%7D%5Bg_t%28f%29%5D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \text{Regret}_T(Q) :=\sum_{t=1}^T \left(\mathop{\mathbb E}_{f\sim P_t}[g_t(f)]-\mathop{\mathbb E}_{f\sim Q}[g_t(f)]\right) \leq 2\sqrt{T\left(\text{KL}(Q||\pi)+\frac12 \ln 2\right)}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BRegret%7D_T%28Q%29+%3A%3D%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+P_t%7D%5Bg_t%28f%29%5D-%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+Q%7D%5Bg_t%28f%29%5D%5Cright%29+%5Cleq+2%5Csqrt%7BT%5Cleft%28%5Ctext%7BKL%7D%28Q%7C%7C%5Cpi%29%2B%5Cfrac12+%5Cln+2%5Cright%29%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
The proof is a straightforward adaptation of the finite-expert case, but for completeness we include it in the Appendix below.
Combining the two previous theorems, and taking care of the fact that ![{\ell(P)\in [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cell%28P%29%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Corollary 3 (PAC-Bayes Bound). Let

The role of 
Remark 1. As in the previous post, the existence of an online learning algorithm with a regret upper bound is enough to prove our bound. We never need to actually run the online algorithm. Moreover, in this case we could not run the reduction even if we wanted to, since the linear losses
depend on the unknown distribution
3. History Bits
PAC-Bayes bounds were first proposed by McAllester (1998) and, as first explained by van Erven (2014), they can be seen as a continuous generalization of the union bound. There is now a vast literature on this subject, and we refer the reader to the recent review by Alquier (2024) for an introduction. Recently, PAC-Bayes bounds gained popularity because they can yield non-vacuous generalization bounds for deep neural networks. Yet one should not confuse a certificate of generalization with an “explanation of generalization” in deep neural networks (see, e.g., Picard-Weibel et al., 2025).
The reduction from online learning to PAC-Bayes bounds as well as the idea of using parameter-free algorithms is from Lugosi&Neu (2023). Despite what claimed in Lugosi&Neu (2023), the PAC-Bayes bound in Corollary 3 is not new, it has been obtained by Kakade et al. (2008). Such bound shaves off a 
Independently, Jang et al. (2023) proposed another reduction from coin-betting to PAC-Bayes. While less general than the one presented here, it allows one to prove tighter results by changing the surrogate loss 
Acknowledgments
Thanks to ChatGPT for checking my post.
Appendix: Proof of the Parameter-free Algorithm for Continuous Experts
It is enough to show the continuous analogue of Theorem 1 here. As in the finite-dimensional case, let 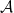



Then, the continuous Learning with Experts Advice (LEA) algorithm predicts with the distribution

After the prediction, the algorithm receives 
![\displaystyle \label{eq:gradients_experts_reduction_cont} c_t(f)= \begin{cases} \mathop{\mathbb E}_{\phi\sim P_t}[g_t(\phi)]-g_t(f), & \text{if } x_t(f)>0,\\ \max\bigl(\mathop{\mathbb E}_{\phi\sim P_t}[g_t(\phi)]-g_t(f),0\bigr), & \text{if } x_t(f)\le 0~. \end{cases} \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Agradients_experts_reduction_cont%7D+c_t%28f%29%3D+%5Cbegin%7Bcases%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cphi%5Csim+P_t%7D%5Bg_t%28%5Cphi%29%5D-g_t%28f%29%2C+%26+%5Ctext%7Bif+%7D+x_t%28f%29%3E0%2C%5C%5C+%5Cmax%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cphi%5Csim+P_t%7D%5Bg_t%28%5Cphi%29%5D-g_t%28f%29%2C0%5Cbigr%29%2C+%26+%5Ctext%7Bif+%7D+x_t%28f%29%5Cle+0%7E.+%5Cend%7Bcases%7D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
The construction above defines a LEA algorithm on a continuous set of experts. The regret guarantee is the following one.
Theorem 4 (Regret Bound for a Continuous Set of Experts). Let
, its wealth after
rounds with initial money equal to
satisfies
Then, the continuous LEA algorithm with prior
for any
concave and non-decreasing such that
for all
.


Proof: We first prove that

Indeed, by the definition of 
![\displaystyle \begin{aligned} \int_{\mathcal{F}} c_t(f)x_t(f)\,\pi(\mathrm{d}f) &= \int_{\{f\,:\,x_t(f)>0\}} x_t(f)\bigl(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f)\bigr)\,\pi(\mathrm{d}f) \\ &\qquad + \int_{\{f\,:\,x_t(f)\le 0\}} x_t(f)\max\bigl(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f),0\bigr)\,\pi(\mathrm{d}f)~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cint_%7B%5Cmathcal%7BF%7D%7D+c_t%28f%29x_t%28f%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29+%26%3D+%5Cint_%7B%5C%7Bf%5C%2C%3A%5C%2Cx_t%28f%29%3E0%5C%7D%7D+x_t%28f%29%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%5Cbigr%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29+%5C%5C+%26%5Cqquad+%2B+%5Cint_%7B%5C%7Bf%5C%2C%3A%5C%2Cx_t%28f%29%5Cle+0%5C%7D%7D+x_t%28f%29%5Cmax%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%2C0%5Cbigr%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now define

If 




Hence,
![\displaystyle \begin{aligned} \int_{\{f\,:\,x_t(f)>0\}} x_t(f)\bigl(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f)\bigr)\,\pi(\mathrm{d}f) &= Z_t \int_{\mathcal{F}} \bigl(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f)\bigr)\,P_t(\mathrm{d}f) \\ &= Z_t \left(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-\mathop{\mathbb E}_{f\sim P_t}[g_t(f)]\right)\\ &=0~. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cint_%7B%5C%7Bf%5C%2C%3A%5C%2Cx_t%28f%29%3E0%5C%7D%7D+x_t%28f%29%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%5Cbigr%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29+%26%3D+Z_t+%5Cint_%7B%5Cmathcal%7BF%7D%7D+%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%5Cbigr%29%5C%2CP_t%28%5Cmathrm%7Bd%7Df%29+%5C%5C+%26%3D+Z_t+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+P_t%7D%5Bg_t%28f%29%5D%5Cright%29%5C%5C+%26%3D0%7E.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Therefore, in all cases,
![\displaystyle \begin{aligned} \int_{\mathcal{F}} c_t(f)x_t(f)\,\pi(\mathrm{d}f) &= 0+\int_{\{f\,:\,x_t(f)\le 0\}} x_t(f)\max\bigl(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f),0\bigr)\,\pi(\mathrm{d}f) \\ &\le 0~, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cint_%7B%5Cmathcal%7BF%7D%7D+c_t%28f%29x_t%28f%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29+%26%3D+0%2B%5Cint_%7B%5C%7Bf%5C%2C%3A%5C%2Cx_t%28f%29%5Cle+0%5C%7D%7D+x_t%28f%29%5Cmax%5Cbigl%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%2C0%5Cbigr%29%5C%2C%5Cpi%28%5Cmathrm%7Bd%7Df%29+%5C%5C+%26%5Cle+0%7E%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
because ![{\max(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f),0)\ge 0}](https://s0.wp.com/latex.php?latex=%7B%5Cmax%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%2C0%29%5Cge+0%7D&bg=ffffff&fg=000000&s=0&c=20201002)
From the assumption on 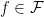
![{\{c_t(f)\}_{t=1}^T \subseteq [-1,1]^T}](https://s0.wp.com/latex.php?latex=%7B%5C%7Bc_t%28f%29%5C%7D_%7Bt%3D1%7D%5ET+%5Csubseteq+%5B-1%2C1%5D%5ET%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Integrating both sides with respect to

Now, fix any competitor 
![\displaystyle \begin{aligned} \text{Regret}_T(Q) &= \sum_{t=1}^T \left(\mathop{\mathbb E}_{f\sim P_t}[g_t(f)]-\mathop{\mathbb E}_{f\sim Q}[g_t(f)]\right) \\ &= \sum_{t=1}^T \int_{\mathcal{F}} \left(\mathop{\mathbb E}_{u\sim P_t}[g_t(u)]-g_t(f)\right)Q(\mathrm{d}f) \\ &\le \sum_{t=1}^T \int_{\mathcal{F}} c_t(f)\,Q(\mathrm{d}f) \qquad \text{(by definition of } c_t(f)\text{)} \\ &= \int_{\mathcal{F}} \sum_{t=1}^T c_t(f)\,Q(\mathrm{d}f) \\ &\le \int_{\mathcal{F}} h\left(f_T\left(\sum_{t=1}^T c_t(f)\right)\right)Q(\mathrm{d}f) \qquad \text{(definition of } h(x)\text{)} \\ &\le h\left(\int_{\mathcal{F}} f_T\left(\sum_{t=1}^T c_t(f)\right)Q(\mathrm{d}f)\right) \qquad \text{(by concavity of } h \text{ and Jensen inequality)}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Ctext%7BRegret%7D_T%28Q%29+%26%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+P_t%7D%5Bg_t%28f%29%5D-%5Cmathop%7B%5Cmathbb+E%7D_%7Bf%5Csim+Q%7D%5Bg_t%28f%29%5D%5Cright%29+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5ET+%5Cint_%7B%5Cmathcal%7BF%7D%7D+%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%7Bu%5Csim+P_t%7D%5Bg_t%28u%29%5D-g_t%28f%29%5Cright%29Q%28%5Cmathrm%7Bd%7Df%29+%5C%5C+%26%5Cle+%5Csum_%7Bt%3D1%7D%5ET+%5Cint_%7B%5Cmathcal%7BF%7D%7D+c_t%28f%29%5C%2CQ%28%5Cmathrm%7Bd%7Df%29+%5Cqquad+%5Ctext%7B%28by+definition+of+%7D+c_t%28f%29%5Ctext%7B%29%7D+%5C%5C+%26%3D+%5Cint_%7B%5Cmathcal%7BF%7D%7D+%5Csum_%7Bt%3D1%7D%5ET+c_t%28f%29%5C%2CQ%28%5Cmathrm%7Bd%7Df%29+%5C%5C+%26%5Cle+%5Cint_%7B%5Cmathcal%7BF%7D%7D+h%5Cleft%28f_T%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+c_t%28f%29%5Cright%29%5Cright%29Q%28%5Cmathrm%7Bd%7Df%29+%5Cqquad+%5Ctext%7B%28definition+of+%7D+h%28x%29%5Ctext%7B%29%7D+%5C%5C+%26%5Cle+h%5Cleft%28%5Cint_%7B%5Cmathcal%7BF%7D%7D+f_T%5Cleft%28%5Csum_%7Bt%3D1%7D%5ET+c_t%28f%29%5Cright%29Q%28%5Cmathrm%7Bd%7Df%29%5Cright%29+%5Cqquad+%5Ctext%7B%28by+concavity+of+%7D+h+%5Ctext%7B+and+Jensen+inequality%29%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
So, it remains to upper bound 



where in the inequality we used Jensen’s inequality for the concave function 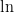

Substituting back the definition of 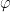

Using (5), the logarithm is at most 

Putting everything together, we have the stated bound.

