This is the first post on a new topic: how to reduce one online learning problem into another in a black-box way. That is, we will use an online convex optimization algorithm to solve a problem different from what it was meant to solve, without looking at its internal working in any way. The only thing we will change will be the input we pass to the algorithm. Why doing it? Because you might have optimization software that you cannot modify or just because designing and analyzing an online learning algorithm in one case might be easier.
Here, I’ll explain how to deal with constraints in online convex optimization in a black box way, and as a bonus, I’ll show how to easily prove the regret guarantee of the Regret Matching+ algorithm.
1. Solving Constrained OCO
We might have an Online Convex Optimization (OCO) algorithm designed for constrained online linear optimization over a feasible set 

Let’s see a prototypical example of this approach. We have a OCO algorithm that outputs in each round 







where 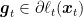


If we could do it, we would have

that is the regret of the OCO algorithm on some surrogate linear losses.
Using our definition of 
![\displaystyle \langle {\boldsymbol g}_t, {\boldsymbol x}_t-{\boldsymbol z}_t\rangle = \left\langle {\boldsymbol g}_t, \frac{{\boldsymbol z}_t}{\|{\boldsymbol z}_t\|_1}-{\boldsymbol z}_t\right\rangle = \left\langle {\boldsymbol g}_t, \frac{{\boldsymbol z}_t}{\|{\boldsymbol z}_t\|_1}\right\rangle \left(1-\|{\boldsymbol z}_t\|_1\right) = -\langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle \langle [1, \dots ,1]^\top, {\boldsymbol z}_t - {\boldsymbol u} \rangle~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t-%7B%5Cboldsymbol+z%7D_t%5Crangle+%3D+%5Cleft%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%5Cfrac%7B%7B%5Cboldsymbol+z%7D_t%7D%7B%5C%7C%7B%5Cboldsymbol+z%7D_t%5C%7C_1%7D-%7B%5Cboldsymbol+z%7D_t%5Cright%5Crangle+%3D+%5Cleft%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%5Cfrac%7B%7B%5Cboldsymbol+z%7D_t%7D%7B%5C%7C%7B%5Cboldsymbol+z%7D_t%5C%7C_1%7D%5Cright%5Crangle+%5Cleft%281-%5C%7C%7B%5Cboldsymbol+z%7D_t%5C%7C_1%5Cright%29+%3D+-%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Clangle+%5B1%2C+%5Cdots+%2C1%5D%5E%5Ctop%2C+%7B%5Cboldsymbol+z%7D_t+-+%7B%5Cboldsymbol+u%7D+%5Crangle%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Instead, if
![\displaystyle \langle {\boldsymbol g}_t, {\boldsymbol x}_t-{\boldsymbol z}_t\rangle = \langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle = -\langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle \langle [1, \dots ,1]^\top, {\boldsymbol z}_t - {\boldsymbol u} \rangle~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t-%7B%5Cboldsymbol+z%7D_t%5Crangle+%3D+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%3D+-%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5Clangle+%5B1%2C+%5Cdots+%2C1%5D%5E%5Ctop%2C+%7B%5Cboldsymbol+z%7D_t+-+%7B%5Cboldsymbol+u%7D+%5Crangle%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, we have that ![{\hat{{\boldsymbol g}_t}=- \langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle [1, \dots, 1]^\top}](https://s0.wp.com/latex.php?latex=%7B%5Chat%7B%7B%5Cboldsymbol+g%7D_t%7D%3D-+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle+%5B1%2C+%5Cdots%2C+1%5D%5E%5Ctop%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \label{eq:constrained_reduction_old} \tilde{\ell}_t({\boldsymbol x})=\langle {\boldsymbol g}_t - [1, \dots, 1]^\top \langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle,{\boldsymbol x}\rangle~. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clabel%7Beq%3Aconstrained_reduction_old%7D+%5Ctilde%7B%5Cell%7D_t%28%7B%5Cboldsymbol+x%7D%29%3D%5Clangle+%7B%5Cboldsymbol+g%7D_t+-+%5B1%2C+%5Cdots%2C+1%5D%5E%5Ctop+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle%2C%7B%5Cboldsymbol+x%7D%5Crangle%7E.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
In this way, we have

It is worth noting that the norm of the gradients of the surrogate losses is controlled: ![{\|{\boldsymbol g}_t-[1, \dots, 1]^\top \langle {\boldsymbol g}_t, {\boldsymbol x}_t\rangle\|_\infty\leq 2\|{\boldsymbol g}_t\|_\infty}](https://s0.wp.com/latex.php?latex=%7B%5C%7C%7B%5Cboldsymbol+g%7D_t-%5B1%2C+%5Cdots%2C+1%5D%5E%5Ctop+%5Clangle+%7B%5Cboldsymbol+g%7D_t%2C+%7B%5Cboldsymbol+x%7D_t%5Crangle%5C%7C_%5Cinfty%5Cleq+2%5C%7C%7B%5Cboldsymbol+g%7D_t%5C%7C_%5Cinfty%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We solved our problem, but this approach does not seem to scale to arbitrary complex feasible sets. Hence, we need a more general way to solve it. In the following, we will show two complementary ways to do it.
1.1. Dealing with Constraints using (Non-Euclidean) Projections

Now, we extend the procedure in the previous section to general convex sets and general norms. First of all, we need some definitions and basic results.
Definition 1 (Distance to a set
be a convex and closed set. The distance to a set with respect to the norm
is the function
defined as
. We also define the generalized projection function
defined as
.
We have the following properties for the distance to a set function.
Lemma 2. Let
is convex.
.
, where
and
.
Proof: For the first property, we have

where in the first inequality we used the convexity of
For the second property, we have that

For the third property, by the definition of subgradient, 

Set 

that implies

Using the fact that 



Example 1. If we consider the L2 norm, we have
where
is the standard Euclidean projection.

Example 2. Note that the projection with respect to a norm different than L2 does not have to be unique. For example, we consider the L1 norm and
From this, we can see that the generalized projection is not unique. In fact, if
for
, then
. Indeed, we have
that is constant with respect to
. Similarly, if
, then
From the optimality condition, we have that
iff
where
is the normal cone to
, that is
This implies that if
and
are non-empty then they contain solutions of the generalized projection. In particular, if
then
and if
and
then
. This implies that if
then, for example,
when
and
if
. Moreover, we can also calculate a subgradient
of
as
if
and
if
.





We can now state the main theorem.
Theorem 3. Denote by
the regret of an OCO algorithm
with feasible set
be convex and closed and
, and the following choices of surrogate losses
:
.
Then, for any of the surrogate losses Algorithm 1 guarantees
Moreover, for any
we have
.




Proof: Note that the second and fourth surrogates are just linearization of the first and third surrogate losses, respectively. Hence, it is enough to prove the regret guarantee for the first and third surrogate loss.
For all of them, we start by observing that

For the first surrogate loss, we have

For the third surrogate loss, first of all, observe that this loss is convex because 


Remembering that 
Remark 1. In the case that
, we can sharpen the bound on the norm of
for the third and fourth loss. In fact, we have
and

Remark 2. The first surrogate loss has a very natural interpretation: it is a Lipschitz penalty function that we add to the (linearized) original losses, where the Lipschitz constant is the same of the original function. Hence, we essentially penalize the algorithm for predicting a point outside of the feasible set.
Example 3 (Regret Matching+). Consider a OGD with learning rate
, over the feasible set
and with initial prediction
. Its regret upper bound is
Now, using the observations in Example 2, we can project onto
with respect to the
norm, using
Then, using any of the above surrogate losses in Algorithm 1, we have
and
. Choosing
proportional to
gives an upper bound proportional to
, that is the expected one when using an algorithm with a Euclidean geometry.
However, we can do even better! Choose the specific surrogate losses in (1) with the projection
, then it should be easy to realize that
(left as an exercise for the reader). This means that we can set
but the regret guarantee of the resulting algorithm will be the one corresponding to the best
The resulting algorithm is known as Regret Matching+ and, despite the suboptimal dependency on
, this is one of the best performing algorithm in practice for the setting of learning with expert advice. If instead of projected OGD we use FTRL with a fixed squared L2 regularizer and feasible set

![\displaystyle {\boldsymbol x}_t= \begin{cases} \frac{{\boldsymbol z}_t}{\|{\boldsymbol z}_t\|_1}, &{\boldsymbol z}_t\neq \boldsymbol{0}\\ [1/d, \dots, 1/d]^\top, & {\boldsymbol z}_t= \boldsymbol{0} \end{cases}~.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cboldsymbol+x%7D_t%3D+%5Cbegin%7Bcases%7D+%5Cfrac%7B%7B%5Cboldsymbol+z%7D_t%7D%7B%5C%7C%7B%5Cboldsymbol+z%7D_t%5C%7C_1%7D%2C+%26%7B%5Cboldsymbol+z%7D_t%5Cneq+%5Cboldsymbol%7B0%7D%5C%5C+%5B1%2Fd%2C+%5Cdots%2C+1%2Fd%5D%5E%5Ctop%2C+%26+%7B%5Cboldsymbol+z%7D_t%3D+%5Cboldsymbol%7B0%7D+%5Cend%7Bcases%7D%7E.+&bg=ffffff&fg=000000&s=0&c=20201002)


1.2. Dealing with Constrains using Bregman Projections
Now, we show an alternative approach based on Bregman projections. First, we define the concept of Bregman projection.
Definition 4 (Bregman Projection). Let
be strictly convex with respect to
. Assume
to be convex and closed. Then, we define the Bregman projection as

With this new concept of projection, we can state the following theorem.
Theorem 5. Let
-strongly convex with respect to
-smooth with respect to
Then, we have
Moreover, we have
for any
.

Proof: Once again, we have

Moreover, we have

where in the second inequality we used the strong convexity of 

where in the second inequality we used the first-order optimality condition

For the bound on 

Example 4. Let’s calculate
where
,
, and we define
. Hence, we have to solve the following optimization problem
We can rewrite it as an unconstrained optimization reformulating the problem over
variables, as
Note that the constraint on
to be non-negative is enforced by the domain of the logarithm. This is now an unconstrained convex optimization problem, so we can solve it equating the gradient of the objective function to zero. Hence, we have
Summing over
, we have
. Solving it, we have
and using it in (3) gives
, for




3. Conclusion
To conclude I just want to stress the fact that these results show, once again, that constrained optimization in bounded sets is easier than unconstrained one. This should have been already clear from the lower bounds, but not we have a more constructive example: you can use an unconstrained algorithm plus projection and surrogate losses to do online optimization in a constrained set, while you cannot use a constrained algorithm to solve an unconstrained problem.
3. History Bits
The reduction from learning from 
As far as I know, the idea of using a black-box reduction for constrained optimization does not appear in the offline and stochastic optimization literature.
Cutkosky and Orabona (2018) proposed the first known black-box reduction from constrained OCO described in Section 1. Cutkosky (2020) proposed the third surrogate loss. Farina, Kroer, and Sandholm (2019) independently from the above work proved Theorem 5.
Regret Matching (RM) was proposed by Hart and Mas-Colell (2000) and Regret Matching+ (RM+) by Tammelin, Burch, Johanson, and Bowling (2015). RM was developed to find correlated equilibria in two-player games and is commonly used to minimize regret over the simplex. RM+ is a modification of RM designed to accelerate convergence and used to effectively solve the game of Heads-up Limit Texas Hold’em poker (Bowling, Burch, Johanson, and Tammelin, 2015). The observation that RM can be expressed as FTRL is due to Nicolò Cesa-Bianchi in an unpublished manuscript titled “The Joys of Regret Matching” dated October 14, 2015 (see Exercise 2). That result was shared with several people (including myself) and then later appeared in some papers too. The observation that RM+ can be obtained by projected OGD is by Farina, Kroer, and Sandholm (2021) and independently by Flaspohler, Orabona, Cohen, Mouatadid, Oprescu, Orenstein, and Mackey (2021). RM and RM+ were extended to 
Acknowledgments
Thanks to Ryan D’Orazio for letting me know about Greenwald, Li, and Marks (2006) and his Master’s thesis. Thanks to Alex Shtoff for finding typos in this post.
4. Exercises
Exercise 1. Find a solution to the projection from
to
Exercise 2. The Regret Matching algorithm predicts with
Prove that it corresponds to FTRL with a squared
regularizer and


Fantastic post! This topic is highly interesting and includes several incredibly important results for online learning!
In fact, we also employ these blackbox reductions with a slight modification in non-stationary online learning to enhance its computational efficiency.
Consider the dynamic regret minimization. Typically, one needs to initiate a two-layer method with O(log T) base learners, hence requiring O(log T) projections onto feasible domain X at each round. This isn’t ideal, espectially when X is complicated. We aim to streamline the projection complexity of non-stationary methods to match that of stationary methods, i.e., using only 1 projection per round.
We use blackbox reductions technique in the form of “domain-to-domain” transformation. The basic idea is very simple: we use an Euclidean ball Y (augementing original domain X) as the surrogate domain. We update all the base learners within this ball Y (so the projection involved in $y_{t,i}$ essentially becomes a rescaling operation), and subsequently project the aggregated decision $y_t$ onto X to obtain $x_t$. This approach allows us to maintain optimal dynamic regret while using only 1 projection onto X per round.
More results can be found in our Neurips’22 paper (Efficient Methods for Non-stationary Online Learning), where we also investigate small-loss bound and adaptive regret (interval regret).
By the way, I noticed two typos in the blog:
LikeLiked by 1 person
Hi Peng, I am glad you liked the post. Thanks for the reference: I plan to cover dynamic regret in the next posts and I’ll read your many papers on the topic 🙂
Thanks for finding the typos, they are fixed now.
LikeLiked by 1 person
A fundamental question is how to minimize regret when the constraints themselves are also time-varying and decided by the adversary. Note that this subsumes the class of projection-free algorithms with known and fixed constraints (e.g., what is discussed in the post above). Here, the objective is to simultaneously minimize regret and cumulative constraint violations. This problem has been studied for more than a decade, yet the optimal bounds/algorithms were not known until recently. We solved the problem optimally using a very elegant analysis by reducing it to plain old OCO in a blackbox fashion. Here is the preprint: https://arxiv.org/pdf/2310.18955
LikeLiked by 1 person
Thanks for sharing it!
LikeLike