This post is about Nesterov’s universal algorithm and how delicate is to claim that an algorithm is “universal”, “parameter-free”, “adaptive”, or any other similar word to denote the fact that the algorithm does not need prior knowledge of the characteristics of a function to converge at its best rate. This post was born from a visit I did to George Lan a few weeks ago.
This post is also a good occasion to point out an important distinction between algorithms that guarantee that the suboptimality gap shrinks at 



1. Nesterov’s Universal Algorithm
We will consider the setting of non-smooth functions, but similar considerations can be made for the weakly-smooth one. So, we have a convex non-smooth Lipschitz function 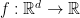

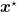
What is a “universal” optimization algorithm? Well, this concept was introduced by Nesterov (2015), but not precisely defined. More or less, he implied that a universal algorithm achieves the optimal convergence rate without knowledge of the characteristics of a function, where the function comes from a known and large function class.
Now, Nesterov’s universal algorithm uses subgradients and function values to guarantee the following complexity rate: 

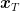


It is possible to show that this complexity bound is optimal, moreover the algorithm does not need to know 
Indeed, for everything we know about parameter-free optimization, the complexity rate above is too good to be true. In fact, you are expected to pay something for your lack of knowledge of the characteristics of 

So, where is the issue? Let’s take a look at Nesterov’s algorithm:

The guarantee for this algorithm is the following one: For any parameter 

Observe a peculiar thing: there is no stopping condition for this algorithm. Now, an algorithm has to terminate after a finite number of steps, otherwise it is not an algorithm! So, either we define a precise stopping condition or we decide to run it for a fixed number of iterations. When do we stop? The above guarantee tells us that if 



I am sure at this point you are trying to find a bug in my reasoning because you cannot believe that Nesterov’s universal algorithm is not universal! So, let me present you two pieces of evidence to show that the above problem is real.
First, I’ll show you how to obtain the exact same complexity with a very dumb algorithm. The algorithm is so dumb that you would have hard time claiming that it is parameter-free. Here is the algorithm:

where 
From the usual proofs, we have

Define 


Observe that this is the same guarantee of the Nesterov’s algorithm above. So, again, we need 

I hope you see it now: Both Nesterov’s algorithm and the dumb procedure above are not parameter-free. Both procedures sooner or later have
While you are still thinking about the above proof, let me also present the second piece of evidence. That is, how is it possible that Nesterov called “universal” an algorithm that still requires knowledge of unknown quantities? It turns out that Nesterov had in mind the constrained and bounded setting. This is clear from the stopping condition that he proposes:

Here, you can see that you can implement this stopping condition only when the feasible set has a bounded diameter, or you have some knowledge about the function. However, it is worth noting that in that case the algorithm stops in the worst case with a number of iterations that is 


2. Could we Tune
There might be still skeptical people, so let’s try to see if we can fix Nesterov’s algorithm. Let’s start from its guarantee:

where
An idea one might have is to say that I have a budget of 


This is optimal in 
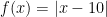
3. Is There any Fix at All?
As I see it, the issue above is due to the fact that we are hiding the required knowledge inside the stopping condition. Pretty sneaky if you ask me!
The presence of
What is the alternative? Suppose I had an algorithm that does not take any parameter and after 

Let me explain why this would be fine: This is a delicate point and the key message of this entire post, so let’s go slowly. I think we agreed that 1) algorithms must terminate and 2) having a stopping condition that depends on unknown quantities is a bad idea. Instead, an algorithm that guarantees
This second type of guarantees are less common because classic optimization focuses on producing a solution with a predefined accuracy. Think for example of an algorithm to calculate eigenvalues: you decide the desidered accuracy and the algorithm stops only when that accuracy is reached (in some measure) or it gives up with a warning saying that it reached the maximum number of iterations. Instead, in statistical learning theory we are very used to these type of guarantees, proving, for example, that the difference between the test error of a predictor and the test error of the best predictor is upper bounded by a term that depends optimally on all the unknown characteristics of the problem. Again, we cannot calculate how many samples we need to have a certain gap from the optimal predictor, because these bounds depend on unknown quantities. However, we still have the comfort of knowing that, no matter how many samples I use, the gap shrinks at the optimal rate. And I feel this is exactly the right thing to show.
4. What is the Best we Can (Currently) Do?
As far as I know, unfortunately we do not have an algorithm that guarantees 
This paper has also an interesting story that reminds us of how poor any scientific community is at recognizing good work:
